语音点歌音乐盒项目报告
1、所选任务介绍
本项目基于嵌入式开发任务要求,目标是开发一款“语音点歌音乐盒”。核心任务要求如下:
1.1 音频播放:预置不少于 3 段旋律序列,通过蜂鸣器(或扬声器)进行播放。
1.2 灯光律动:由于选用蜂鸣器进行播放,需配合使用 RGB 灯带,使其根据音乐节拍或音符强弱产生律动灯效。
1.3 语音控制:通过麦克风进行关键词识别,实现至少 3 条语音指令,用于控制音乐盒的状态。
1.4 OLED显示:使用 OLED 屏幕实时显示当前曲目编号、播放进度百分比以及当前系统音量。
1.5 扩展功能:支持网页端远程查看状态和控制。
2、项目介绍
本项目是一个集成了离线语音识别、音频 PWM 生成、动态 UI 渲染以及 RGB 氛围灯控制的综合性物联网硬件作品。可以通过说关键词(播放,暂停,下一首,)来与设备进行非接触式交互。系统接收到指令后,改变蜂鸣器输出的 PWM 频率和占空比来模拟不同音符,芯片中通歌过数组存储的三首,同时驱动 RGB 灯带根据当前音符的频率呈现动态光效。还可以通过网页来控制设备。OLED 屏幕作为主要的人机交互界面,会实时刷新并反馈设备当前的工作参数,实现了一个完整且极具趣味性的桌面智能音乐盒。
3、硬件介绍
ESP32-S3 Sense:作为主控,拥有强大的 Xtensa 双核 LX7 处理器,具备出色的 AI处理能力,板载麦克风极其适合运行 ESP-SR 或 EDGE IMPULSE 等语音唤醒和识别模型。

无源蜂鸣器:连接GPIO9引脚。音频输出模块。与有源蜂鸣器不同,它需要主控输出不同频率的 PWM 波才能发出不同音高的声音,用于演奏代码预置的旋律。

RGB 灯带:连接GPIO8引脚。全彩 LED 模块,单总线控制,用于实现与音乐旋律同步的律动灯效。

OLED 显示屏:连接GPIO5,GPIO6引脚。0.96 寸或 1.3 寸单色/双色屏幕,功耗低、对比度高,用于清晰地显示歌曲序号、音量条和进度条。

数字硅麦克风:连接GPIO41,GPIO42引脚。这是一款采用 I2S PDM 数字接口的高性能麦克风,支持 16kHz 采样率与 16 位深度。它具有高信噪比、低功耗、抗干扰能力强的特点,作为系统的“听觉”传感器,负责全天候清晰地采集用户的环境语音,并高速传输给 AI 核心进行离线关键词识别与推理。

4、项目设计思路介绍
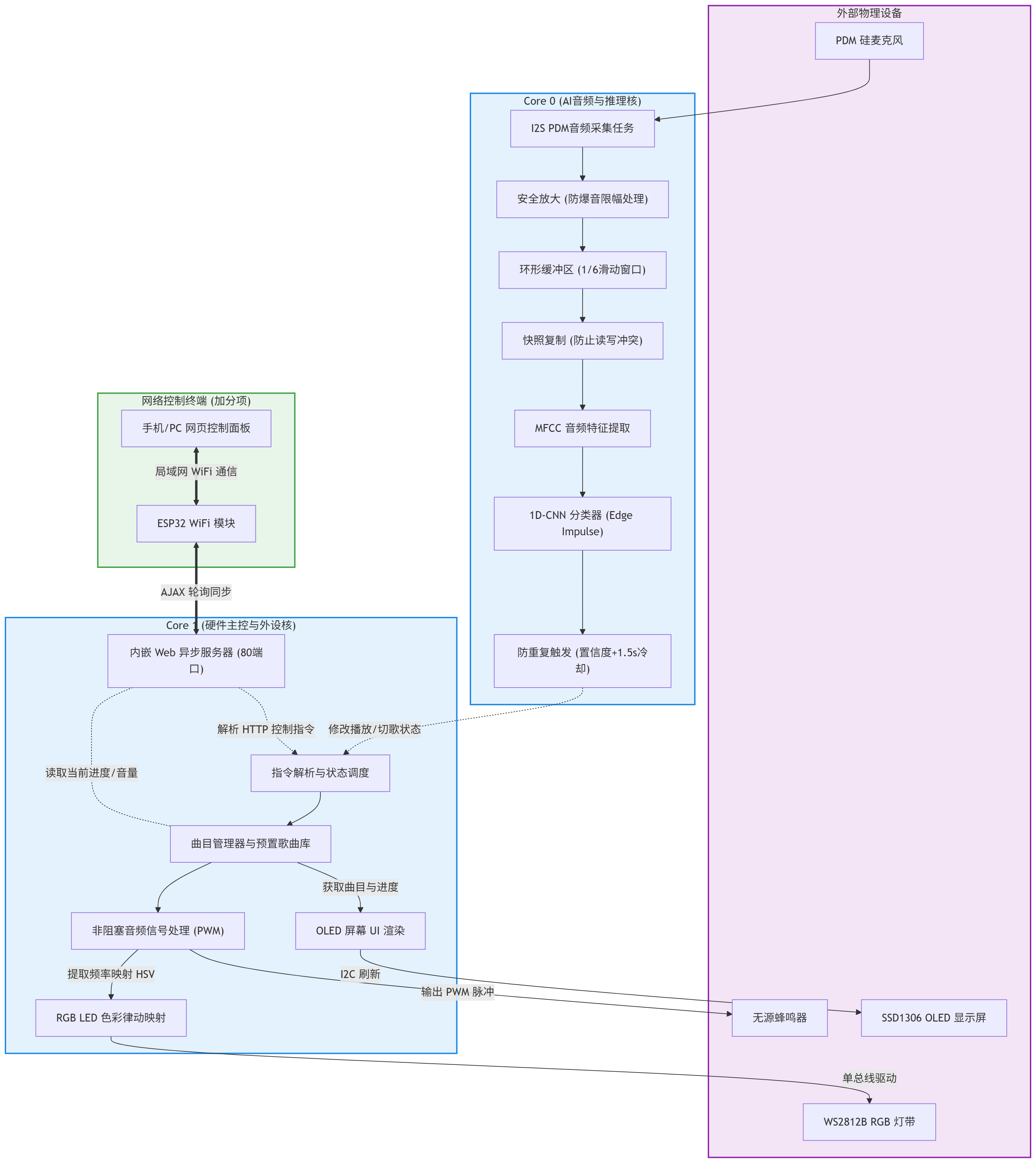
设计思路: 系统采用模块化与状态机结合的设计。主程序分为多个并行任务利用 FreeRTOS 的多任务特性把任务分为核心一和核心二。 核心一的功能:语音监听任务,持续读取 I2S 麦克风数据并送入模型推理,识别出语音指令后更新全局标志位。 核心二的功能:音乐播放任务:根据当前选中的曲目数组,遍历音符频率与节拍持续时间,驱动蜂鸣器发声,并将当前音符的特征值传递给灯效模块,UI 刷新任务:定时读取全局变量,更新 OLED 的显存并推送到屏幕。
方案框图:
5、调试软件及使用的编程语言说明、软件流程图及关键代码介绍
开发环境与语言:
开发环境:Arduino IDE。
编程语言:ESP32开发逻辑全部采用C++语言编写。AI模型推理部署采用C++。前端Web控制面板采用 HTML、CSS 和 JavaScript。
模型训练与部署:语音模型在Edge Impulse Studio平台上训练得出。使用在XIAO板上现场采集的play, pause, next,词汇。MFCC处理后进入TensorFlow Lite Micro深度学习网络进行训练,最终导出为Arduino C++静态库文件直接部署在Core 0上运行。
软件流程图:
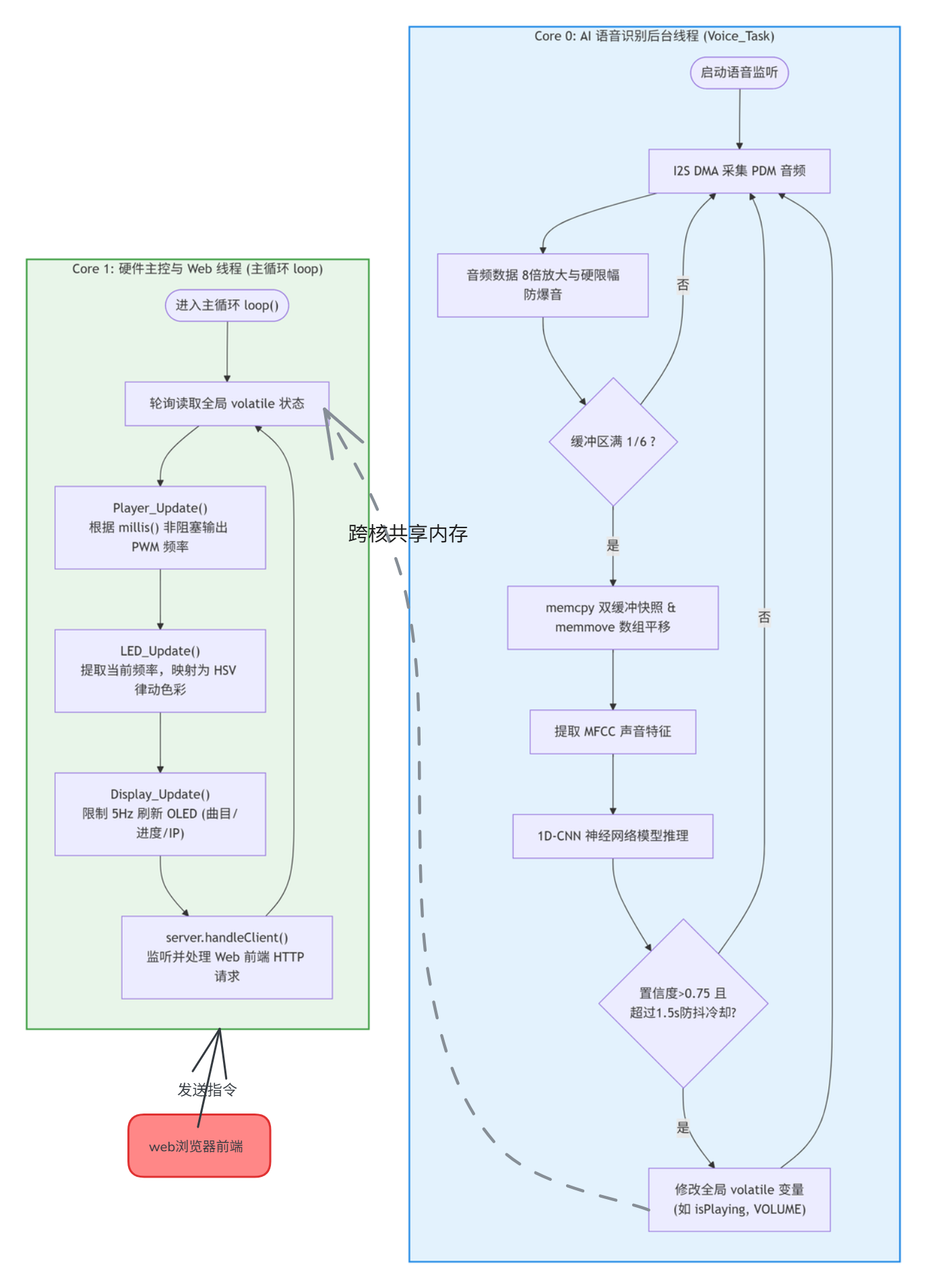
关键代码
一、主程序
存放头文件,硬件引脚配置,wifi配置盒全局共享配置。在loop中使用模块函数。
#include <esp32-project1_inferencing.h>
#include <Arduino.h>
#include <Wire.h>
#include <Adafruit_GFX.h>
#include <Adafruit_SSD1306.h>
#include <Adafruit_NeoPixel.h>
#include <WebServer.h>
#include <I2S.h>
/* ================== 1. 硬件引脚配置 ================== */
#define OLED_SDA 5
#define OLED_SCL 6
#define SCREEN_WIDTH 128
#define SCREEN_HEIGHT 64
#define LED_PIN 8
#define NUM_LEDS 10
#define BUZZER_PIN 9
#define LEDC_CH 0
#define LEDC_RES 8
#define LEDC_BASE_FREQ 2000
/* ================== 2. WiFi 配置 ================== */
const char* ssid = "kunkun"; // 填入你的WiFi名称
const char* password = "@123abc@"; // 填入你的WiFi密码
/* ================== 3. 全局共享状态 ================== */
volatile int VOLUME = 1;
volatile bool isPlaying = true;
volatile bool isPaused = false;
volatile int currentSongIndex = 0;
volatile int currentPitch = 0;
volatile int currentProgress = 0;
const char* currentSongName = "Init...";
/* ================== 4. 跨文件数据声明 ================== */
extern const int* melodies[];
extern const int songSizes[];
extern const char* songNames[];
extern const int TOTAL_SONGS;
/* ================== 5. 跨文件函数声明 ================== */
void Buzzer_Play(int freq);
void Buzzer_Stop();
void Buzzer_SetVolume(int v);
void Display_Init();
void Display_Update();
void LED_Init();
void LED_Update();
void Player_Init();
void Player_Update();
void Player_NextSong();
void Player_PrevSong();
void Player_SetSong(int index);
void Web_Init();
void Web_Update();
void Voice_Init();
/* ================== 6. 主程序 ================== */
void setup() {
Serial.begin(115200);
// 1. 连 WiFi
Serial.print("Connecting to WiFi: "); Serial.println(ssid);
WiFi.begin(ssid, password);
while (WiFi.status() != WL_CONNECTED) { delay(500); Serial.print("."); }
Serial.println("\nWiFi Connected!");
Serial.print("IP Address: "); Serial.println(WiFi.localIP());
// 2. 初始化各模块
Display_Init();
LED_Init();
Player_Init();
Web_Init();
Voice_Init();
}
void loop() {
Player_Update();
LED_Update();
Display_Update();
Web_Update(); // 处理网页请求
}
二、蜂鸣器播放及播放器(player.ino)
蜂鸣器的初始化,配置蜂鸣器的播放,暂停和音量。
/* ================== 音乐播放器逻辑 ================== */
unsigned long lastNoteTime = 0;
int fullNoteDuration = 0;
bool isNoteOn = false;
int noteIndex = 0;
void Buzzer_Stop() {
ledcWriteTone(LEDC_CH, 0);
ledcWrite(LEDC_CH, 0);
}
void Buzzer_Play(int freq) {
if (freq <= 0) {
Buzzer_Stop();
} else {
ledcWriteTone(LEDC_CH, freq);
ledcWrite(LEDC_CH, VOLUME);
}
}
// 修改音量设置:最大值为 10
void Buzzer_SetVolume(int vol) {
VOLUME = constrain(vol, 0, 10);
}
播放器的功能设置
void Player_NextSong() { //下一首
currentSongIndex++;
if (currentSongIndex >= TOTAL_SONGS) currentSongIndex = 0;
noteIndex = 0;
currentSongName = songNames[currentSongIndex];
currentProgress = 0;
lastNoteTime = millis();
}
void Player_PrevSong() { //上一首
currentSongIndex--;
if (currentSongIndex < 0) currentSongIndex = TOTAL_SONGS - 1;
noteIndex = 0;
currentSongName = songNames[currentSongIndex];
currentProgress = 0;
lastNoteTime = millis();
}
void Player_SetSong(int index) { //在web中选歌
if (index >= 0 && index < TOTAL_SONGS) {
currentSongIndex = index;
noteIndex = 0;
currentSongName = songNames[currentSongIndex];
currentProgress = 0;
lastNoteTime = millis();
isPlaying = true;
isPaused = false;
}
}
三、LED灯带效果(LED.ino)
暂停播放,彩虹呼吸灯。
if (isPaused || !isPlaying) {
// 控制特效刷新率:每20ms更新一次(避免CPU占用过高,效果更流畅)
if (now - lastLedUpdate > 20) {
lastLedUpdate = now;
rainbowHue += 100; // 色相递增,实现颜色循环(值越大,颜色切换越快)
// 呼吸亮度控制
breathVal += breathDir * 2; // 亮度步长为2,加快/减慢呼吸速度
if (breathVal >= 150) breathDir = -1; // 亮度到上限,开始变暗
if (breathVal <= 10) breathDir = 1; // 亮度到下限,开始变亮
// 绘制彩虹效果:参数(起始色相,相邻灯珠色相差,饱和度,亮度)
strip.rainbow(rainbowHue, 1, 255, breathVal);
strip.show(); // 刷新灯带,显示新效果
}
}
播放状态,频率联动频谱
} else {
// 频谱特效刷新率:每15ms更新一次(比呼吸灯快,更跟手)
if (now - lastLedUpdate > 15) {
lastLedUpdate = now;
// 1. 将音符频率映射为色相(200~1000Hz 对应 0~65535 色相)
uint16_t baseHue = map(currentPitch, 200, 1000, 0, 65535);
// 2. 将音符频率映射为亮灯长度(0~1000Hz 对应 0~总灯珠数)
int barLength = map(currentPitch, 0, 1000, 0, NUM_LEDS);
if(currentPitch <= 0) barLength = 0; // 休止符(频率0)时,灯全部灭
// 3. 逐灯珠绘制频谱效果
for(int i=0; i<NUM_LEDS; i++) {
if (i < barLength) {
// 亮灯区域:颜色随灯珠位置渐变(baseHue + i*2000)
strip.setPixelColor(i, strip.ColorHSV(baseHue + (i * 2000), 255, 80));
} else {
// 灭灯区域:渐隐效果(每次亮度减15,直到0)
uint32_t c = strip.getPixelColor(i); // 获取当前灯珠颜色
// 拆分颜色为 R/G/B 分量(GRB 格式,需注意顺序)
uint8_t r = (c >> 16), g = (c >> 8), b = c;
// 亮度衰减:大于15则减15,否则置0(避免负数)
r = (r > 15) ? r - 15 : 0;
g = (g > 15) ? g - 15 : 0;
b = (b > 15) ? b - 15 : 0;
strip.setPixelColor(i, r, g, b); // 设置衰减后的颜色
}
}
strip.show(); // 刷新灯带,显示频谱效果
}
}
}
四、OLED显示(display.ino)
第一行,播放状态和音量。第二行歌曲信息。第三行,播放进度。第四行,web服务的IP地址。
// --- 第一行:状态 + 音量 ---
display.setCursor(0, 0);
if (isPaused) display.print(" PAUSED ");
else if (isPlaying) display.print(" PLAYING");
else display.print(" STOPPED ");
// 在右侧显示音量 (假设 VOLUME 最大值为 10,则显示为 0-100)
display.setCursor(85, 0);
display.print("V:");
display.print(VOLUME * 10); // 将 1-10 映射为 10-100
// --- 第二行:歌曲信息 ---
display.setCursor(0, 16);
display.print("#"); display.print(currentSongIndex + 1); display.print(": ");
display.println(currentSongName);
// --- 第三行:简短进度条 + 数字 ---
// 进度条背景 (长度缩短到 95 像素)
display.drawRect(0, 35, 95, 10, WHITE);
// 填充进度
int barWidth = map(currentProgress, 0, 100, 0, 91);
display.fillRect(2, 37, barWidth, 6, WHITE);
// 进度百分比数字 (放在进度条右侧)
display.setCursor(100, 37);
display.print(currentProgress);
display.print("%");
// --- 第四行:IP 地址 ---
display.setCursor(0, 54);
display.print("IP:");
display.print(WiFi.localIP().toString().c_str());
display.display();
}
五、语音识别
语音识别功能放在core0上
// 将语音识别任务绑定到 Core 0,不干扰主程序 Core 1 的音乐
xTaskCreatePinnedToCore(
voice_recognition_task, // 任务函数
"VoiceTask", // 任务名称
8192, // 栈大小
NULL, // 参数
1, // 优先级
NULL, // 任务句柄
0 // 绑定到核心 0
);
音频回调与滑动窗口核心逻辑
/* --- 底层音频回调与连续推理滑动窗口策略 --- */
static void audio_inference_callback(uint32_t n_bytes) {
// n_bytes>>1:字节数转采样点数(int16=2字节,右移1位等价于除以2)
for(int i = 0; i < n_bytes>>1; i++) {
// 将I2S读取的采样点写入推理缓冲区
inference.buffer[inference.buf_count++] = sampleBuffer[i];
// 当缓冲区存满「单次推理需要的采样点数」时(比如模型需要1秒=16000个采样)
if(inference.buf_count >= inference.n_samples) {
// 1. 拍快照:把当前缓冲区的数据完整拷贝到快照数组(memcpy 是内存拷贝函数)
memcpy(inference_buffer_copy, inference.buffer, inference.n_samples * sizeof(int16_t));
inference.buf_ready = 1; // 置1:通知AI线程“数据准备好了,可以推理”
// 2. 1/6 滑动窗口策略(核心优化:降低识别延迟)
uint32_t slice_count = 6;
uint32_t step = inference.n_samples / slice_count; // 滑动步长(每次滑1/6的总长度)
uint32_t overlap = inference.n_samples - step; // 重叠区域长度(保留5/6的旧数据)
// memmove:安全的内存平移(支持内存重叠,比memcpy更安全)
// 把缓冲区中「step之后的重叠数据」移到缓冲区开头
memmove(inference.buffer, inference.buffer + step, overlap * sizeof(int16_t));
// 指针回退:下次新采样直接从重叠区域末尾开始写,无缝衔接
inference.buf_count = overlap;
}
}
}
I2S 音频采集任务(Core 0 后台运行)
static void capture_samples(void* arg) {
const int32_t i2s_bytes_to_read = (uint32_t)arg; // 单次读取的字节数(2048)
size_t bytes_read = i2s_bytes_to_read;
while (record_status) { // 循环采集,直到 record_status=false
// 从 I2S 麦克风读取音频数据(超时100ms)
esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
if (bytes_read > 0) { // 读到有效数据
// 核心新增:安全防爆音限幅(解决麦克风音量过大导致的音频失真)
for (int x = 0; x < i2s_bytes_to_read/2; x++) {
int32_t amplified = (int32_t)sampleBuffer[x] * 8; // 音量放大8倍(提升识别灵敏度)
if (amplified > 32767) amplified = 32767; // int16 最大值(防止溢出)
if (amplified < -32768) amplified = -32768; // int16 最小值
sampleBuffer[x] = (int16_t)amplified;
}
// 把处理后的音频数据交给回调函数,填充到推理缓冲区
audio_inference_callback(i2s_bytes_to_read);
}
}
vTaskDelete(NULL); // 停止采集后,删除这个任务
}
推理缓冲区初始化
static bool microphone_inference_start(uint32_t n_samples) {
// 为推理缓冲区分配内存(n_samples 是模型需要的采样点数)
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
// 核心新增:给快照数组也分配同样的内存空间
inference_buffer_copy = (int16_t *)malloc(n_samples * sizeof(int16_t));
// 内存分配失败则返回false
if(inference.buffer == NULL || inference_buffer_copy == NULL) return false;
// 初始化缓冲区状态
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
record_status = true;
// 创建音频采集任务(栈大小32KB,优先级10)
xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void*)sample_buffer_size, 10, NULL);
return true;
}
推理数据准备与格式转换
// 等待缓冲区就绪(buf_ready=1),就绪后重置标志
static bool microphone_inference_record(void) {
while (inference.buf_ready == 0) { delay(10); }
inference.buf_ready = 0; return true;
}
// Edge Impulse 模型的音频数据读取回调(模型需要 float 格式数据)
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {
// 核心修改:让模型去读快照数组,不受底层滑动窗口的干扰
numpy::int16_to_float(&inference_buffer_copy[offset], out_ptr, length);
return 0;
}
核心 AI 推理与指令执行任务
void voice_recognition_task(void *pvParameters) {
// 用于防抖的全局计时器
unsigned long last_trigger_time = 0;
const unsigned long COOLDOWN_MS = 1500; // 冷却时间:1.5秒,防重复切歌
while (1) { // 无限循环,持续推理
// 等待录音完成(滑动窗口每1/6秒触发一次)
if (!microphone_inference_record()) continue;
// 构建 Edge Impulse 信号结构体(告诉模型数据在哪、有多长)
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT; // 模型需要的采样点数(宏由Edge Impulse生成)
signal.get_data = µphone_audio_signal_get_data; // 数据读取回调
ei_impulse_result_t result = { 0 }; // 推理结果存储
// 运行模型推理
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, false);
if (r != EI_IMPULSE_OK) continue; // 推理失败则跳过
// 找出置信度最高的识别结果
int pred_index = -1;
float pred_value = 0;
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
if (result.classification[ix].value > pred_value){
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// 关键词控制逻辑:置信度 > 0.75 (过滤低置信度的误识别)
if (pred_value > 0.75 && pred_index >= 0) {
String keyword = result.classification[pred_index].label;
// 过滤噪音和未知词汇(模型训练时通常会加 noise/other 类别)
if (keyword != "noise" && keyword != "other") {
// 核心新增:动作冷却防抖逻辑
if (millis() - last_trigger_time > COOLDOWN_MS) {
// 串口打印识别结果(调试用)
Serial.print(" 高精度识别指令: ["); Serial.print(keyword);
Serial.print("] 置信度: "); Serial.println(pred_value);
// 更新触发时间(重置冷却计时)
last_trigger_time = millis();
// 执行控制动作
if (keyword == "play") {
isPlaying = true; isPaused = false; // 播放
}
else if (keyword == "pause") {
isPaused = true; // 暂停
}
else if (keyword == "next") {
Player_NextSong(); isPlaying = true; isPaused = false; // 下一首
}
}
}
}
// 给系统喘息的时间(10ms),防止CPU占满触发看门狗重启
vTaskDelay(10 / portTICK_PERIOD_MS);
}
}
6.实物展示
整体实物展示

介绍:显示屏上面显示第一行是播放还是暂停,还有音量,由于这个声音太大了,占空比为10就是最大音量了,这里10就是代表占空比为1.第二行展示歌曲序号和歌曲名。第三行展示的是进度条和详细的进度。第四行展示的是IP地址,当你的设备连接同一个wifi时,输入这个IP地址就可以控制设备了。
网页展示
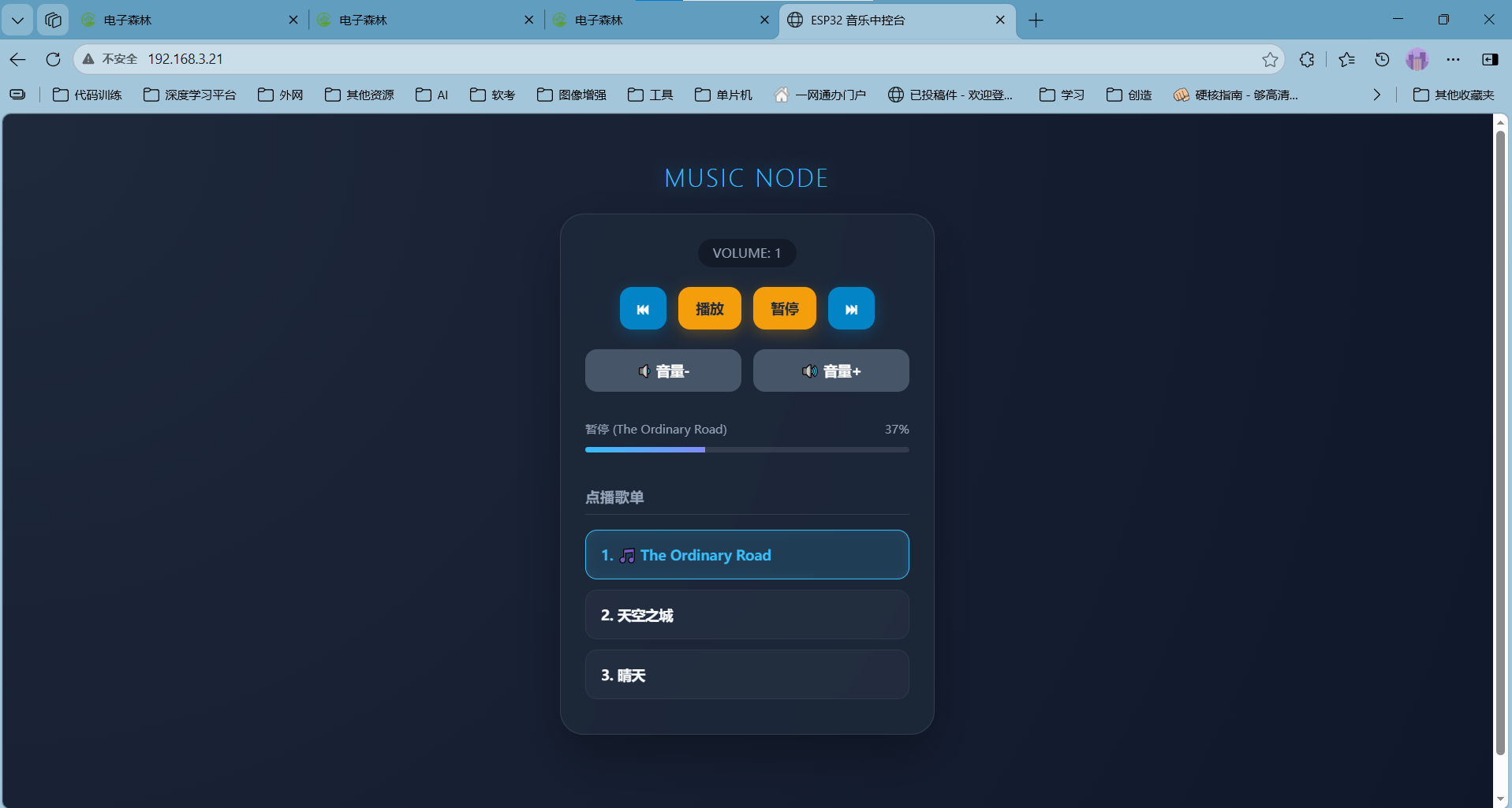
介绍:这个网页能控制单片机的动作,其中上面的框如里面的文字描述的一样,点击就是上面的功能,下面是存放的歌曲,点击那个就可以直接播放那首歌。
7、项目中的困难
1.问题:四位按键中后两位的adc值为最大4095.
通过单按和双按来区别,后面任务中取消了,还有电压太高,会损坏设备,就删除了这部分。
2.当刷入了OLED的代码后,再像刷入就一直刷不进程序。
当刷不进程序时,先将boot按键一直按住,再插入数据线,再下载程序。还有一个方法,就是先按住boot按键,再按reset按键,就进入下载模式了。我还因为在语音识别的时候,下载了其他的固件,导致第二种方法用不了。
3.web功能,当我换了wifi时,整个程序都没法用了。
当配置或修改了wifi时,一定要注意当前wifi是否配置正确,还要记得插天线,不然不能使用wifi。
4.语音识别功能识别很差。
一定要使用板载麦克风来采集数据,数据量也要充足(一个关键词60s左右),太少是一定不行的,而且数据中要有noise和other两类,noise是没声音的时候,other是可能会干扰到你识别时候的声音,就比如当你播放音乐时,可以把音乐设置成other。还有就是感谢群里大佬的语音识别算法的思路,通过双缓冲,滑动窗口,防抖的添加,能大大提高识别的准确率。
8.心得体会
本次项目实践是一次从“硬件底层驱动”到“多模态交互应用”的完整跨越,让我深刻体会到了边缘 AI 与物联网技术结合的魅力。
在技术层面,我掌握了 ESP32-S3 的双核调度、I2S 音频采集以及 Edge Impulse 模型部署,并提升了 Web 前端开发能力。面对 AI 推理阻塞音乐、语音识别率低等难题,我通过引入 FreeRTOS 双核并发、滑动窗口快照与防抖算法逐一攻克,显著提升了复杂系统的综合调试能力。
在设计层面,我深刻意识到“多模态用户体验”的重要性:不仅终端的 OLED 显示需清晰直观,RGB 灯带的律动也需与物理音高严密契合;同时,Web 中控面板操作需简洁流畅,真正做到软硬件之间毫无延迟的状态同步。
非常感谢这次的主办方,因为我才学完stm32,想通过这个项目来学习esp32和Ai相关的知识,和群里的大佬们进行交流能学到很多东西,群里的工作人员在面对我们的问题,回复的也非常及时,通过这个项目,我也学到了很多。还有Aii十分强大,当我们有想法和有问题的时候都可以通过Ai来实现,用ai的心得,就如当时讲课的老师说的,要用就要用好的AI,能节约很多时间和精力。再次致谢本次活动,这段经历让我从零开始,对 ESP32 有了初步的接触与认知.
附件
代码文件:
通过网盘分享的文件:2026寒假一起练-智能人工实验平台-周然鹏
链接: https://pan.baidu.com/s/1tx10QGNtUp2vw6dptsevbg?pwd=jav3 提取码: jav3



