任务介绍
本项目实现了2026寒假练活动Seeed XIAO ESP32S3 Sense开发板的语音控制音乐播放器任务,基于ESP32-S3双核架构,利用板载PDM麦克风采集语音信号,通过Edge Impulse训练的神经网络模型实现关键词识别,控制SD卡中MP3文件的播放,同时通过OLED屏幕实时显示曲目编号、播放进度百分比和当前音量等状态信息。

硬件平台
本次使用Seeed Studio推出的XIAO ESP32S3 Sense开发板,是一款面向AIoT应用的超小型高性能开发平台。该开发板搭载了基于Xtensa LX7双核架构的ESP32-S3芯片,主频高达240MHz,具备丰富的外设资源,包括多个I2C接口、SPI接口、I2S接口等,非常适合用于边缘AI与实时嵌入式系统的开发。开发板集成了PDM数字麦克风、摄像头接口、microSD卡槽,便于快速搭建多媒体原型系统。
在软件方面,本项目采用Arduino框架作为底层开发环境,结合FreeRTOS多任务调度机制实现双核并行处理。语音识别部分使用Edge Impulse平台训练的轻量级神经网络模型,音频解码采用ESP8266Audio库实现MP3实时解码播放。
主控设备:Seeed XIAO ESP32S3 Sense开发板
- 搭载ESP32-S3芯片(Xtensa LX7双核,240MHz)
- 集成PDM数字麦克风(GPIO42/GPIO41)
- 板载microSD卡槽,支持MP3文件存储
- 支持FreeRTOS多核任务调度
外设扩展模块
- 128x64 SSD1306 OLED显示屏(I2C接口,D4=SDA,D5=SCL)
- MAX98357A I2S DAC功放模块(D0=BCLK,D1=LRC,D3=DOUT)
- microSD卡(存储不少于3首MP3音乐文件)
任务分析与实现
本系统实现了基于ESP32-S3双核架构的语音控制MP3播放器,主要功能包括:
四通道数据交互:
- 语音采集与识别
- PDM麦克风采样率:16kHz
- 支持"start"、"pause"、"next"三条语音指令
- MP3音频解码播放
- I2S DAC输出,支持暂停/恢复断点续播
- 自动播放下一首,循环播放
- OLED显示控制
- 显示刷新率:2Hz(每500ms更新一次)
- 实时显示曲目编号、播放进度、音量信息
- 串口命令控制
- 支持播放/暂停、停止、上下曲、音量调节等完整指令集
系统架构设计
本项目充分利用ESP32-S3的双核特性,将语音识别与音频播放分别部署在不同的CPU核心上,通过FreeRTOS Queue实现线程安全的跨核通信:
核心 | 任务 | 说明 |
|---|---|---|
Core 0 | 语音采集 + Edge Impulse推理 | PDM麦克风数据采集与神经网络分类 |
Core 1 | MP3解码 + OLED显示 + 串口处理 | 音频播放主循环与用户界面 |
方案框图:
%22%3E%3Cpath%20d%3D%22M19.5%2C136%20L199.5%2C136%20A3.75%2C3.75%200%200%201%20202%2C138.5%20L209%2C155.9688%20L209.5%2C155.9688%20A2.5%2C2.5%200%200%201%20212%2C158.4688%20L212%2C763.5%20A2.5%2C2.5%200%200%201%20209.5%2C766%20L19.5%2C766%20A2.5%2C2.5%200%200%201%2017%2C763.5%20L17%2C138.5%20A2.5%2C2.5%200%200%201%2019.5%2C136%20%22%20fill%3D%22none%22%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%20x1%3D%2217%22%20x2%3D%22209%22%20y1%3D%22155.9688%22%20y2%3D%22155.9688%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22179%22%20x%3D%2221%22%20y%3D%22149.1387%22%3EEdge%20Impulse%26%2325512%3B%26%2329702%3B%20(Core%200)%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2274%22%20x%3D%2281.5%22%20y%3D%22169.1074%22%3E%26%23171%3BESP32-S3%26%23187%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22cluster_FreeRTOS%26%2336890%3B%26%2320449%3B%22%3E%3Cpath%20d%3D%22M64.5%2C797%20L160.5%2C797%20A3.75%2C3.75%200%200%201%20163%2C799.5%20L170%2C816.9688%20L179.5%2C816.9688%20A2.5%2C2.5%200%200%201%20182%2C819.4688%20L182%2C900.5%20A2.5%2C2.5%200%200%201%20179.5%2C903%20L64.5%2C903%20A2.5%2C2.5%200%200%201%2062%2C900.5%20L62%2C799.5%20A2.5%2C2.5%200%200%201%2064.5%2C797%20%22%20fill%3D%22none%22%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%20x1%3D%2262%22%20x2%3D%22170%22%20y1%3D%22816.9688%22%20y2%3D%22816.9688%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2295%22%20x%3D%2266%22%20y%3D%22810.1387%22%3EFreeRTOS%26%2336890%3B%26%2320449%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22cluster_%26%2325773%3B%26%2325918%3B%26%2325511%3B%26%2321046%3B%20(Core%201)%22%3E%3Cpath%20d%3D%22M210.5%2C790%20L322.5%2C790%20A3.75%2C3.75%200%200%201%20325%2C792.5%20L332%2C809.9688%20L515.5%2C809.9688%20A2.5%2C2.5%200%200%201%20518%2C812.4688%20L518%2C1236.5%20A2.5%2C2.5%200%200%201%20515.5%2C1239%20L210.5%2C1239%20A2.5%2C2.5%200%200%201%20208%2C1236.5%20L208%2C792.5%20A2.5%2C2.5%200%200%201%20210.5%2C790%20%22%20fill%3D%22none%22%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%20x1%3D%22208%22%20x2%3D%22332%22%20y1%3D%22809.9688%22%20y2%3D%22809.9688%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22111%22%20x%3D%22212%22%20y%3D%22803.1387%22%3E%26%2325773%3B%26%2325918%3B%26%2325511%3B%26%2321046%3B%20(Core%201)%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-style%3D%22italic%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2274%22%20x%3D%22330%22%20y%3D%22823.1074%22%3E%26%23171%3BESP32-S3%26%23187%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22cluster_%26%2338899%3B%26%2339057%3B%26%2336755%3B%26%2320986%3B%26%2323618%3B%22%3E%3Cpath%20d%3D%22M362.5%2C1263%20L428.5%2C1263%20A3.75%2C3.75%200%200%201%20431%2C1265.5%20L438%2C1282.9688%20L465.5%2C1282.9688%20A2.5%2C2.5%200%200%201%20468%2C1285.4688%20L468%2C1352.5%20A2.5%2C2.5%200%200%201%20465.5%2C1355%20L362.5%2C1355%20A2.5%2C2.5%200%200%201%20360%2C1352.5%20L360%2C1265.5%20A2.5%2C2.5%200%200%201%20362.5%2C1263%20%22%20fill%3D%22none%22%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%20x1%3D%22360%22%20x2%3D%22438%22%20y1%3D%221282.9688%22%20y2%3D%221282.9688%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%22364%22%20y%3D%221276.1387%22%3E%26%2338899%3B%26%2339057%3B%26%2336755%3B%26%2320986%3B%26%2323618%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22cluster_%26%2323384%3B%26%2320648%3B%26%2323618%3B%22%3E%3Cpath%20d%3D%22M544.5%2C797%20L584.5%2C797%20A3.75%2C3.75%200%200%201%20587%2C799.5%20L594%2C816.9688%20L695.5%2C816.9688%20A2.5%2C2.5%200%200%201%20698%2C819.4688%20L698%2C900.5%20A2.5%2C2.5%200%200%201%20695.5%2C903%20L544.5%2C903%20A2.5%2C2.5%200%200%201%20542%2C900.5%20L542%2C799.5%20A2.5%2C2.5%200%200%201%20544.5%2C797%20%22%20fill%3D%22none%22%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%20x1%3D%22542%22%20x2%3D%22594%22%20y1%3D%22816.9688%22%20y2%3D%22816.9688%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2239%22%20x%3D%22546%22%20y%3D%22810.1387%22%3E%26%2323384%3B%26%2320648%3B%26%2323618%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22cluster_%26%2326174%3B%26%2331034%3B%26%2323618%3B%22%3E%3Cpath%20d%3D%22M544.5%2C1010%20L584.5%2C1010%20A3.75%2C3.75%200%200%201%20587%2C1012.5%20L594%2C1029.9688%20L995.5%2C1029.9688%20A2.5%2C2.5%200%200%201%20998%2C1032.4688%20L998%2C1236.5%20A2.5%2C2.5%200%200%201%20995.5%2C1239%20L544.5%2C1239%20A2.5%2C2.5%200%200%201%20542%2C1236.5%20L542%2C1012.5%20A2.5%2C2.5%200%200%201%20544.5%2C1010%20%22%20fill%3D%22none%22%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23000000%3Bstroke-width%3A1.5%3B%22%20x1%3D%22542%22%20x2%3D%22594%22%20y1%3D%221029.9688%22%20y2%3D%221029.9688%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2239%22%20x%3D%22546%22%20y%3D%221023.1387%22%3E%26%2326174%3B%26%2331034%3B%26%2323618%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_mic%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22144%22%20x%3D%2250%22%20y%3D%2238%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22174%22%20y%3D%2243%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22172%22%20y%3D%2245%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22172%22%20y%3D%2249%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2263%22%20x%3D%2265%22%20y%3D%2269.1387%22%3EPDM%26%2340614%3B%26%2320811%3B%26%2339118%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22104%22%20x%3D%2265%22%20y%3D%2283.1074%22%3E(GPIO42%2FGPIO41)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_capture%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22139%22%20x%3D%2252.5%22%20y%3D%22182%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22171.5%22%20y%3D%22187%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22169.5%22%20y%3D%22189%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22169.5%22%20y%3D%22193%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2299%22%20x%3D%2267.5%22%20y%3D%22213.1387%22%3EPDM%26%2338899%3B%26%2339057%3B%26%2337319%3B%26%2338598%3B%26%2320219%3B%26%2321153%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_ringbuf%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22100%22%20x%3D%2272%22%20y%3D%22287%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22152%22%20y%3D%22292%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22150%22%20y%3D%22294%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22150%22%20y%3D%22298%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%2287%22%20y%3D%22318.1387%22%3E%26%2329615%3B%26%2324418%3B%26%2332531%3B%26%2320914%3B%26%2321306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2258%22%20x%3D%2287%22%20y%3D%22332.1074%22%3E(%26%2328369%3B%26%2321160%3B%26%2331383%3B%26%2321475%3B)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_snapshot%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2288%22%20x%3D%2278%22%20y%3D%22406%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22146%22%20y%3D%22411%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22144%22%20y%3D%22413%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22144%22%20y%3D%22417%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%2293%22%20y%3D%22437.1387%22%3E%26%2324555%3B%26%2329031%3B%26%2322797%3B%26%2321046%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_mfcc%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22121%22%20x%3D%2261.5%22%20y%3D%22500%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22162.5%22%20y%3D%22505%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22160.5%22%20y%3D%22507%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22160.5%22%20y%3D%22511%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2281%22%20x%3D%2276.5%22%20y%3D%22531.1387%22%3EMFCC%26%2329305%3B%26%2324449%3B%26%2325552%3B%26%2321462%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_cnn%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22123%22%20x%3D%2260.5%22%20y%3D%22594%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22163.5%22%20y%3D%22599%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22161.5%22%20y%3D%22601%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22161.5%22%20y%3D%22605%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2283%22%20x%3D%2275.5%22%20y%3D%22625.1387%22%3E1D-CNN%26%2320998%3B%26%2331867%3B%26%2322120%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_debounce%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22120%22%20x%3D%2262%22%20y%3D%22692%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22162%22%20y%3D%22697%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22160%22%20y%3D%22699%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22160%22%20y%3D%22703%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%2277%22%20y%3D%22723.1387%22%3E%26%2338450%3B%26%2337325%3B%26%2322797%3B%26%2335302%3B%26%2321457%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2280%22%20x%3D%2277%22%20y%3D%22737.1074%22%3E(%26%2338408%3B%26%2320540%3B%2B%26%2320919%3B%26%2321364%3B%26%2326399%3B)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_queue%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2288%22%20x%3D%2278%22%20y%3D%22829%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22146%22%20y%3D%22834%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22144%22%20y%3D%22836%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22144%22%20y%3D%22840%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2247%22%20x%3D%2293%22%20y%3D%22860.1387%22%3ExQueue%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%2293%22%20y%3D%22874.1074%22%3E%26%2321629%3B%26%2320196%3B%26%2338431%3B%26%2321015%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_dispatcher%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22100%22%20x%3D%22224%22%20y%3D%22937%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22304%22%20y%3D%22942%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22302%22%20y%3D%22944%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22302%22%20y%3D%22948%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%22239%22%20y%3D%22968.1387%22%3E%26%2321629%3B%26%2320196%3B%26%2320998%3B%26%2321457%3B%26%2322120%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_mp3dec%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22175%22%20x%3D%22326.5%22%20y%3D%221042%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22481.5%22%20y%3D%221047%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22479.5%22%20y%3D%221049%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22479.5%22%20y%3D%221053%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2262%22%20x%3D%22341.5%22%20y%3D%221073.1387%22%3EMP3%26%2335299%3B%26%2330721%3B%26%2322120%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22135%22%20x%3D%22341.5%22%20y%3D%221087.1074%22%3E(AudioGeneratorMP3)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_sdcard%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22117%22%20x%3D%22384.5%22%20y%3D%22937%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22481.5%22%20y%3D%22942%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22479.5%22%20y%3D%22944%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22479.5%22%20y%3D%22948%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2277%22%20x%3D%22399.5%22%20y%3D%22968.1387%22%3ESD%26%2321345%3B%26%2325991%3B%26%2320214%3B%26%2331649%3B%26%2329702%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_i2s_out%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22123%22%20x%3D%22352.5%22%20y%3D%221165%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22455.5%22%20y%3D%221170%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22453.5%22%20y%3D%221172%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22453.5%22%20y%3D%221176%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%22367.5%22%20y%3D%221196.1387%22%3EI2S%20DAC%26%2336755%3B%26%2320986%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2283%22%20x%3D%22367.5%22%20y%3D%221210.1074%22%3E(MAX98357A)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_serial%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22112%22%20x%3D%22226%22%20y%3D%22836%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22318%22%20y%3D%22841%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22316%22%20y%3D%22843%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22316%22%20y%3D%22847%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%22241%22%20y%3D%22867.1387%22%3E%26%2320018%3B%26%2321475%3B%26%2321629%3B%26%2320196%3B%26%2335299%3B%26%2326512%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_speaker%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2243.9688%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2276%22%20x%3D%22376%22%20y%3D%221295%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22432%22%20y%3D%221300%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22430%22%20y%3D%221302%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22430%22%20y%3D%221306%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2236%22%20x%3D%22391%22%20y%3D%221326.1387%22%3E%26%2325196%3B%26%2322768%3B%26%2322120%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_sdfile%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22124%22%20x%3D%22558%22%20y%3D%22829%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22662%22%20y%3D%22834%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22660%22%20y%3D%22836%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22660%22%20y%3D%22840%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2263%22%20x%3D%22573%22%20y%3D%22860.1387%22%3EmicroSD%26%2321345%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2284%22%20x%3D%22573%22%20y%3D%22874.1074%22%3E(MP3%26%2325991%3B%26%2320214%3Bx3%2B)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_oled%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22133%22%20x%3D%22717.5%22%20y%3D%221042%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22830.5%22%20y%3D%221047%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22828.5%22%20y%3D%221049%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22828.5%22%20y%3D%221053%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2293%22%20x%3D%22732.5%22%20y%3D%221073.1387%22%3ESSD1306%20OLED%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2269%22%20x%3D%22732.5%22%20y%3D%221087.1074%22%3E128x64%20I2C%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_track_info%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2294%22%20x%3D%22888%22%20y%3D%221165%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22962%22%20y%3D%221170%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22960%22%20y%3D%221172%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22960%22%20y%3D%221176%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%22903%22%20y%3D%221196.1387%22%3E%26%2326354%3B%26%2330446%3B%26%2332534%3B%26%2321495%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2254%22%20x%3D%22903%22%20y%3D%221210.1074%22%3ETrack%20x%2Fy%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_progress%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%22122%22%20x%3D%22558%22%20y%3D%221165%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22660%22%20y%3D%221170%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22658%22%20y%3D%221172%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22658%22%20y%3D%221176%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%22573%22%20y%3D%221196.1387%22%3E%26%2325773%3B%26%2325918%3B%26%2336827%3B%26%2324230%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2282%22%20x%3D%22573%22%20y%3D%221210.1074%22%3E%26%2336827%3B%26%2324230%3B%26%2326465%3B%2B%26%2330334%3B%26%2320998%3B%26%2327604%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_volume%22%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2257.9375%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2288%22%20x%3D%22740%22%20y%3D%221165%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%2210%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%2215%22%20x%3D%22808%22%20y%3D%221170%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22806%22%20y%3D%221172%22%2F%3E%3Crect%20fill%3D%22%23F1F1F1%22%20height%3D%222%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%20width%3D%224%22%20x%3D%22806%22%20y%3D%221176%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%22755%22%20y%3D%221196.1387%22%3E%26%2324403%3B%26%2321069%3B%26%2338899%3B%26%2337327%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2246%22%20x%3D%22755%22%20y%3D%221210.1074%22%3EVol%3Axx%25%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_GMN46%22%3E%3Cpath%20d%3D%22M254%2C27%20L254%2C63%20L194.179%2C67%20L254%2C71%20L254%2C106.8438%20A0%2C0%200%200%200%20254%2C106.8438%20L362%2C106.8438%20A0%2C0%200%200%200%20362%2C106.8438%20L362%2C37%20L352%2C27%20L254%2C27%20A0%2C0%200%200%200%20254%2C27%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpath%20d%3D%22M352%2C27%20L352%2C37%20L362%2C37%20L352%2C27%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%22260%22%20y%3D%2243.1387%22%3E%26%2337319%3B%26%2338598%3B%26%2321442%3B%26%2325968%3B%26%2365306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2287%22%20x%3D%22260%22%20y%3D%2257.1074%22%3EPDM%26%2325968%3B%26%2323383%3B%26%2340614%3B%26%2320811%3B%26%2339118%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2273%22%20x%3D%22260%22%20y%3D%2271.0762%22%3E16kHz%26%2337319%3B%26%2326679%3B%26%2329575%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2280%22%20x%3D%22260%22%20y%3D%2285.0449%22%3E16bit%26%2337319%3B%26%2326679%3B%26%2328145%3B%26%2324230%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2236%22%20x%3D%22260%22%20y%3D%2299.0137%22%3E%26%2321333%3B%26%2322768%3B%26%2336947%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_GMN49%22%3E%3Cpath%20d%3D%22M232.5%2C276%20L232.5%2C312%20L172.209%2C316%20L232.5%2C320%20L232.5%2C355.8438%20A0%2C0%200%200%200%20232.5%2C355.8438%20L389.5%2C355.8438%20A0%2C0%200%200%200%20389.5%2C355.8438%20L389.5%2C286%20L379.5%2C276%20L232.5%2C276%20A0%2C0%200%200%200%20232.5%2C276%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpath%20d%3D%22M379.5%2C276%20L379.5%2C286%20L389.5%2C286%20L379.5%2C276%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%22238.5%22%20y%3D%22292.1387%22%3E%26%2328369%3B%26%2321160%3B%26%2331383%3B%26%2321475%3B%26%2365306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22110%22%20x%3D%22238.5%22%20y%3D%22306.1074%22%3E%26%2331383%3B%26%2321475%3B%26%2322823%3B%26%2323567%3B%26%2365306%3B1000ms%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22105%22%20x%3D%22238.5%22%20y%3D%22320.0762%22%3ESLICE_DIVISOR%3D6%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2285%22%20x%3D%22238.5%22%20y%3D%22334.0449%22%3E%26%2337325%3B%26%2321472%3B%26%2329575%3B%26%2365306%3B~83%25%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22136%22%20x%3D%22238.5%22%20y%3D%22348.0137%22%3E%26%2329615%3B%26%2324418%3B%26%2332531%3B%26%2320914%3B%26%2321306%3B%26%2323481%3B%26%2337327%3B%26%2365306%3B16000%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_GMN52%22%3E%3Cpath%20d%3D%22M242%2C688%20L242%2C717%20L182.247%2C721%20L242%2C725%20L242%2C753.875%20A0%2C0%200%200%200%20242%2C753.875%20L400%2C753.875%20A0%2C0%200%200%200%20400%2C753.875%20L400%2C698%20L390%2C688%20L242%2C688%20A0%2C0%200%200%200%20242%2C688%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpath%20d%3D%22M390%2C688%20L390%2C698%20L400%2C698%20L390%2C688%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%22248%22%20y%3D%22704.1387%22%3E%26%2319977%3B%26%2337325%3B%26%2338450%3B%26%2324481%3B%26%2365306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22113%22%20x%3D%22248%22%20y%3D%22718.1074%22%3E%26%239312%3B%20%26%2332622%3B%26%2320449%3B%26%2324230%3B%26%2338408%3B%26%2320540%3B%20%26gt%3B%200.8%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22137%22%20x%3D%22248%22%20y%3D%22732.0762%22%3E%26%239313%3B%20%26%2336830%3B%26%2332493%3B%26%2330830%3B%26%2335748%3B(Debounce)%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22105%22%20x%3D%22248%22%20y%3D%22746.0449%22%3E%26%239314%3B%20%26%2320919%3B%26%2321364%3B%26%2326399%3B%201500ms%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_GMN55%22%3E%3Cpath%20d%3D%22M1014%2C1031%20L1014%2C1110.8438%20L1138%2C1110.8438%20L1138%2C1041%20L1128%2C1031%20L1014%2C1031%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpath%20d%3D%22M1128%2C1031%20L1128%2C1041%20L1138%2C1041%20L1128%2C1031%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%221020%22%20y%3D%221047.1387%22%3E%26%2325773%3B%26%2325918%3B%26%2329305%3B%26%2324615%3B%26%2365306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22103%22%20x%3D%221020%22%20y%3D%221061.1074%22%3EESP8266Audio%26%2324211%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%221020%22%20y%3D%221075.0762%22%3E%26%2326029%3B%26%2328857%3B%26%2332493%3B%26%2325773%3B%26%2325903%3B%26%2325345%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%221020%22%20y%3D%221089.0449%22%3E%26%2324103%3B%26%2322836%3B%26%2333258%3B%26%2321160%3B%26%2325628%3B%26%2332034%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%221020%22%20y%3D%221103.0137%22%3E%26%2320114%3B%26%2326021%3B%26%2338145%3B%26%2320445%3B%26%2325252%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22elem_GMN58%22%3E%3Cpath%20d%3D%22M1042.5%2C1161%20L1042.5%2C1226.875%20L1165.5%2C1226.875%20L1165.5%2C1171%20L1155.5%2C1161%20L1042.5%2C1161%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpath%20d%3D%22M1155.5%2C1161%20L1155.5%2C1171%20L1165.5%2C1171%20L1155.5%2C1161%20%22%20fill%3D%22%23FEFFDD%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%221048.5%22%20y%3D%221177.1387%22%3E%26%2326174%3B%26%2331034%3B%26%2320869%3B%26%2323481%3B%26%2365306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22102%22%20x%3D%221048.5%22%20y%3D%221191.1074%22%3E%26%2321047%3B%26%2326032%3B%26%2321608%3B%26%2326399%3B%26%2365306%3B500ms%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2269%22%20x%3D%221048.5%22%20y%3D%221205.0762%22%3EU8g2%26%2339537%3B%26%2321160%3B%26%2324211%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2291%22%20x%3D%221048.5%22%20y%3D%221219.0449%22%3EI2C%26%2325509%3B%26%2321475%3B(D4%2FD5)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_mic_capture%22%3E%3Cpath%20d%3D%22M122%2C96.05%20C122%2C121.66%20122%2C152.42%20122%2C175.75%20%22%20fill%3D%22none%22%20id%3D%22mic-to-capture%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C181.75%2C126%2C172.75%2C122%2C176.75%2C118%2C172.75%2C122%2C181.75%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2275%22%20x%3D%2246%22%20y%3D%22122.0387%22%3EPDM%26%2325968%3B%26%2323383%3B%26%2320449%3B%26%2321495%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2261%22%20x%3D%2253%22%20y%3D%22136.0074%22%3E16kHz%26%2337319%3B%26%2326679%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_capture_ringbuf%22%3E%3Cpath%20d%3D%22M122%2C226.13%20C122%2C243.47%20122%2C261.75%20122%2C280.7%20%22%20fill%3D%22none%22%20id%3D%22capture-to-ringbuf%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C286.7%2C126%2C277.7%2C122%2C281.7%2C118%2C277.7%2C122%2C286.7%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%2249%22%20y%3D%22239.5487%22%3E%26%2339281%3B%26%2321644%3B%26%2322686%3B%26%2330410%3B%26%2325918%3B%26%2322823%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2230%22%20x%3D%2270%22%20y%3D%22253.5174%22%3E(8%26%2320493%3B)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_ringbuf_snapshot%22%3E%3Cpath%20d%3D%22M122%2C345.13%20C122%2C364.06%20122%2C382.351%20122%2C399.732%20%22%20fill%3D%22none%22%20id%3D%22ringbuf-to-snapshot%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C405.732%2C126%2C396.732%2C122%2C400.732%2C118%2C396.732%2C122%2C405.732%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2256%22%20x%3D%2265%22%20y%3D%22358.5687%22%3E%26%2327599%3B1%2F6%26%2331383%3B%26%2321475%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%2269%22%20y%3D%22372.5374%22%3E%26%2335302%3B%26%2321457%3B%26%2324555%3B%26%2329031%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_snapshot_mfcc%22%3E%3Cpath%20d%3D%22M122%2C450.277%20C122%2C465.261%20122%2C478.932%20122%2C493.883%20%22%20fill%3D%22none%22%20id%3D%22snapshot-to-mfcc%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C499.883%2C126%2C490.883%2C122%2C494.883%2C118%2C490.883%2C122%2C499.883%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%2254%22%20y%3D%22458.2187%22%3E%26%2325512%3B%26%2329702%3B%26%2332531%3B%26%2320914%3B%26%2321306%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2274%22%20x%3D%2247%22%20y%3D%22472.1874%22%3E(16000%26%2326679%3B%26%2326412%3B)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_mfcc_cnn%22%3E%3Cpath%20d%3D%22M122%2C544.277%20C122%2C559.261%20122%2C572.932%20122%2C587.883%20%22%20fill%3D%22none%22%20id%3D%22mfcc-to-cnn%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C593.883%2C126%2C584.883%2C122%2C588.883%2C118%2C584.883%2C122%2C593.883%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2236%22%20x%3D%2279%22%20y%3D%22552.2187%22%3E637%26%2332500%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%2273%22%20y%3D%22566.1874%22%3E%26%2329305%3B%26%2324449%3B%26%2321521%3B%26%2337327%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_cnn_debounce%22%3E%3Cpath%20d%3D%22M122%2C638.011%20C122%2C653.647%20122%2C668.803%20122%2C685.841%20%22%20fill%3D%22none%22%20id%3D%22cnn-to-debounce%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C691.841%2C126%2C682.841%2C122%2C686.841%2C118%2C682.841%2C122%2C691.841%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%2273%22%20y%3D%22648.0647%22%3E%26%2320998%3B%26%2331867%3B%26%2332467%3B%26%2326524%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2230%22%20x%3D%2282%22%20y%3D%22662.0334%22%3E(5%26%2331867%3B)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_debounce_queue%22%3E%3Cpath%20d%3D%22M122%2C750.054%20C122%2C773.304%20122%2C799.749%20122%2C822.988%20%22%20fill%3D%22none%22%20id%3D%22debounce-to-queue%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22122%2C828.988%2C126%2C819.988%2C122%2C823.988%2C118%2C819.988%2C122%2C828.988%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2281%22%20x%3D%2223.5%22%20y%3D%22772.6597%22%3Eplayer_cmd_t%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22114%22%20x%3D%227%22%20y%3D%22786.6284%22%3E(start%2Fpause%2Fnext)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_queue_dispatcher%22%3E%3Cpath%20d%3D%22M166.372%2C885%20C206.278%2C885%20258.667%2C885%20258.667%2C885%20C258.667%2C885%20258.667%2C909%20258.667%2C930.798%20%22%20fill%3D%22none%22%20id%3D%22queue-to-dispatcher%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22258.667%2C936.798%2C262.667%2C927.798%2C258.667%2C931.798%2C254.667%2C927.798%2C258.667%2C936.798%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2295%22%20x%3D%22239.418%22%20y%3D%22897.1387%22%3ExQueueReceive%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_serial_dispatcher%22%3E%3Cpath%20d%3D%22M291.333%2C880.415%20C291.333%2C897.269%20291.333%2C914.242%20291.333%2C930.995%20%22%20fill%3D%22none%22%20id%3D%22serial-to-dispatcher%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22291.333%2C936.995%2C295.333%2C927.995%2C291.333%2C931.995%2C287.333%2C927.995%2C291.333%2C936.995%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%22294.333%22%20y%3D%22920.8437%22%3E%26%2320018%3B%26%2321475%3B%26%2321333%3B%26%2323383%3B%26%2331526%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2264%22%20x%3D%22292.333%22%20y%3D%22934.8124%22%3E(p%2Fn%2Fb%2F%2B%2F-)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_dispatcher_mp3dec%22%3E%3Cpath%20d%3D%22M324.151%2C959%20C329.05%2C959%20332.25%2C959%20332.25%2C959%20C332.25%2C959%20332.25%2C1002.681%20332.25%2C1035.866%20%22%20fill%3D%22none%22%20id%3D%22dispatcher-to-mp3dec%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22332.25%2C1041.866%2C336.25%2C1032.866%2C332.25%2C1036.866%2C328.25%2C1032.866%2C332.25%2C1041.866%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2252%22%20x%3D%22273.25%22%20y%3D%221008.5217%22%3E%26%2325773%3B%26%2325918%3B%2F%26%2326242%3B%26%2320572%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2264%22%20x%3D%22267.25%22%20y%3D%221022.4904%22%3E%26%2319978%3B%26%2319979%3B%26%2326354%3B%2F%26%2338899%3B%26%2337327%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_sdcard_mp3dec%22%3E%3Cpath%20d%3D%22M443%2C981.128%20C443%2C998.468%20443%2C1016.748%20443%2C1035.701%20%22%20fill%3D%22none%22%20id%3D%22sdcard-to-mp3dec%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22443%2C1041.701%2C447%2C1032.701%2C443%2C1036.701%2C439%2C1032.701%2C443%2C1041.701%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2260%22%20x%3D%22382%22%20y%3D%221008.5527%22%3E%26%2338899%3B%26%2339057%3B%26%2325991%3B%26%2320214%3B%26%2327969%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_sdfile_sdcard%22%3E%3Cpath%20d%3D%22M557.939%2C883%20C509.635%2C883%20450.75%2C883%20450.75%2C883%20C450.75%2C883%20450.75%2C908.19%20450.75%2C930.609%20%22%20fill%3D%22none%22%20id%3D%22sdfile-to-sdcard%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22450.75%2C936.609%2C454.75%2C927.609%2C450.75%2C931.609%2C446.75%2C927.609%2C450.75%2C936.609%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2243%22%20x%3D%22417.54%22%20y%3D%22866.1387%22%3ESPI%26%2335835%3B%26%2321462%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2275%22%20x%3D%22401.54%22%20y%3D%22880.1074%22%3E(GPIO21%20CS)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_mp3dec_i2s_out%22%3E%3Cpath%20d%3D%22M414%2C1100.149%20C414%2C1119.614%20414%2C1139.124%20414%2C1158.634%20%22%20fill%3D%22none%22%20id%3D%22mp3dec-to-i2s_out%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22414%2C1164.634%2C418%2C1155.634%2C414%2C1159.634%2C410%2C1155.634%2C414%2C1164.634%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2274%22%20x%3D%22339%22%20y%3D%221129.5297%22%3EPCM%26%2335299%3B%26%2330721%3B%26%2325968%3B%26%2325454%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_i2s_out_speaker%22%3E%3Cpath%20d%3D%22M414%2C1223.149%20C414%2C1245.172%20414%2C1268.9314%20414%2C1288.9857%20%22%20fill%3D%22none%22%20id%3D%22i2s_out-to-speaker%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22414%2C1294.9857%2C418%2C1285.9857%2C414%2C1289.9857%2C410%2C1285.9857%2C414%2C1294.9857%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2243%22%20x%3D%22357%22%20y%3D%221242.2057%22%3EI2S%26%2320449%3B%26%2321495%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2269%22%20x%3D%22344%22%20y%3D%221256.1744%22%3E(D0%2FD1%2FD3)%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_dispatcher_oled%22%3E%3Cpath%20d%3D%22M274%2C981.124%20C274%2C993.314%20274%2C1006%20274%2C1006%20C274%2C1006%20784%2C1006%20784%2C1006%20C784%2C1006%20784%2C1018.615%20784%2C1035.922%20%22%20fill%3D%22none%22%20id%3D%22dispatcher-to-oled%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22784%2C1041.922%2C788%2C1032.922%2C784%2C1036.922%2C780%2C1032.922%2C784%2C1041.922%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2254%22%20x%3D%22479.523%22%20y%3D%221018.1387%22%3E%26%2327599%3B500ms%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2212%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2248%22%20x%3D%22482.523%22%20y%3D%221032.1074%22%3E%26%2321047%3B%26%2326032%3B%26%2329366%3B%26%2324577%3B%3C%2Ftext%3E%3C%2Fg%3E%3Cg%20id%3D%22link_oled_track_info%22%3E%3Cpath%20d%3D%22M835.5%2C1100.149%20C835.5%2C1136.522%20835.5%2C1194%20835.5%2C1194%20C835.5%2C1194%20856.155%2C1194%20881.872%2C1194%20%22%20fill%3D%22none%22%20id%3D%22oled-to-track_info%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22887.872%2C1194%2C878.872%2C1190%2C882.872%2C1194%2C878.872%2C1198%2C887.872%2C1194%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3C%2Fg%3E%3Cg%20id%3D%22link_oled_progress%22%3E%3Cpath%20d%3D%22M728.75%2C1100.149%20C728.75%2C1136.522%20728.75%2C1194%20728.75%2C1194%20C728.75%2C1194%20711.432%2C1194%20686.293%2C1194%20%22%20fill%3D%22none%22%20id%3D%22oled-to-progress%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22680.293%2C1194%2C689.293%2C1198%2C685.293%2C1194%2C689.293%2C1190%2C680.293%2C1194%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3C%2Fg%3E%3Cg%20id%3D%22link_oled_volume%22%3E%3Cpath%20d%3D%22M784%2C1100.149%20C784%2C1119.614%20784%2C1139.124%20784%2C1158.634%20%22%20fill%3D%22none%22%20id%3D%22oled-to-volume%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22784%2C1164.634%2C788%2C1155.634%2C784%2C1159.634%2C780%2C1155.634%2C784%2C1164.634%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3C%2Fg%3E%3Cg%20id%3D%22link_GMN55_mp3dec%22%3E%3Cpath%20d%3D%22M1013.96%2C1106%20C862.941%2C1106%20488.5%2C1106%20488.5%2C1106%20C488.5%2C1106%20488.5%2C1103.674%20488.5%2C1100.22%20%22%20fill%3D%22none%22%20id%3D%22GMN55-mp3dec%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3Bstroke-dasharray%3A7.0%2C7.0%3B%22%2F%3E%3C%2Fg%3E%3Cg%20id%3D%22link_oled_GMN58%22%3E%3Cpath%20d%3D%22M843%2C1100.078%20C843%2C1117.385%20843%2C1136%20843%2C1136%20C843%2C1136%201090.25%2C1136%201090.25%2C1136%20C1090.25%2C1136%201090.25%2C1147.909%201090.25%2C1160.934%20%22%20fill%3D%22none%22%20id%3D%22oled-GMN58%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3Bstroke-dasharray%3A7.0%2C7.0%3B%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
Edge Impulse 语音模型训练过程
本项目的语音识别功能基于Edge Impulse平台完成模型训练与部署,以下详细描述了从数据采集到模型导出的完整流程。
一、数据采集与预处理
1. 语音样本录制
使用XIAO ESP32S3 Sense板载PDM麦克风录制语音样本,每个关键词录制多段长音频(约10秒),采样率设置为16kHz、16位单声道。录制的关键词类别包括:
- start:用于触发播放/恢复功能
- pause:用于触发暂停功能
- next:用于切换到下一首曲目
- noise:环境背景噪声样本
- unknown:非目标关键词的语音样本
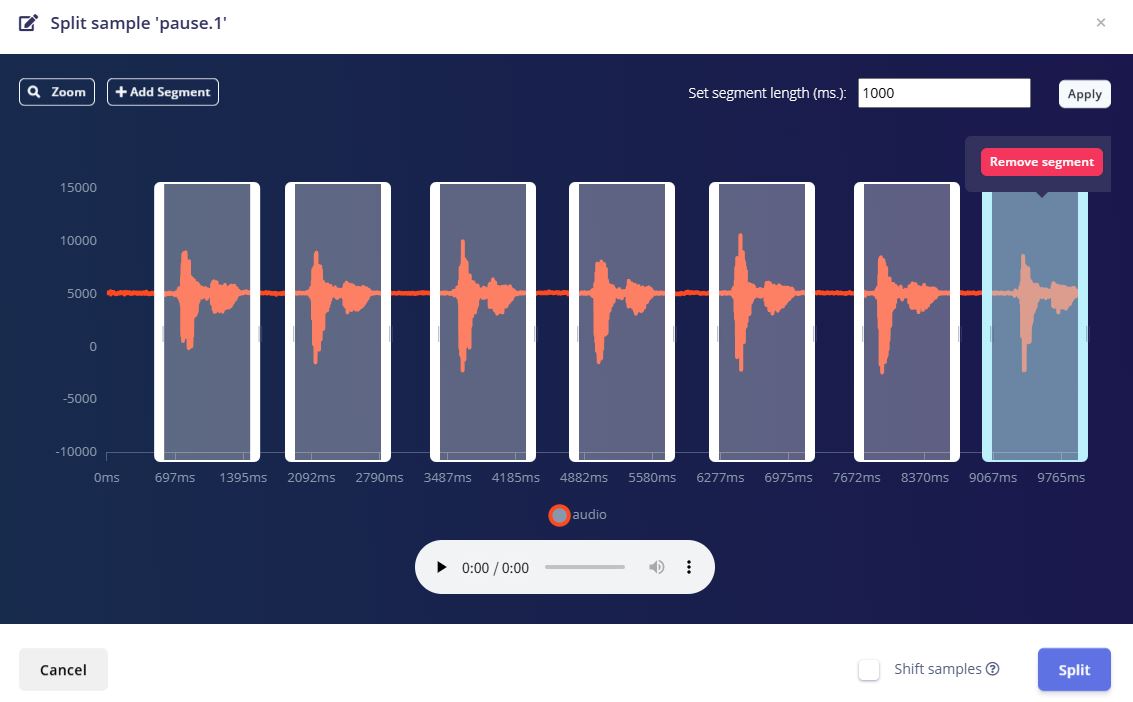
2. 数据分割
将录制的长音频上传至Edge Impulse后,使用平台提供的Split Sample功能将每段长音频按照1000ms的窗口长度自动分割为独立的训练样本。每个关键词被分割为多个1秒长度的样本片段,确保模型能够学习到关键词在不同时间位置出现的特征。
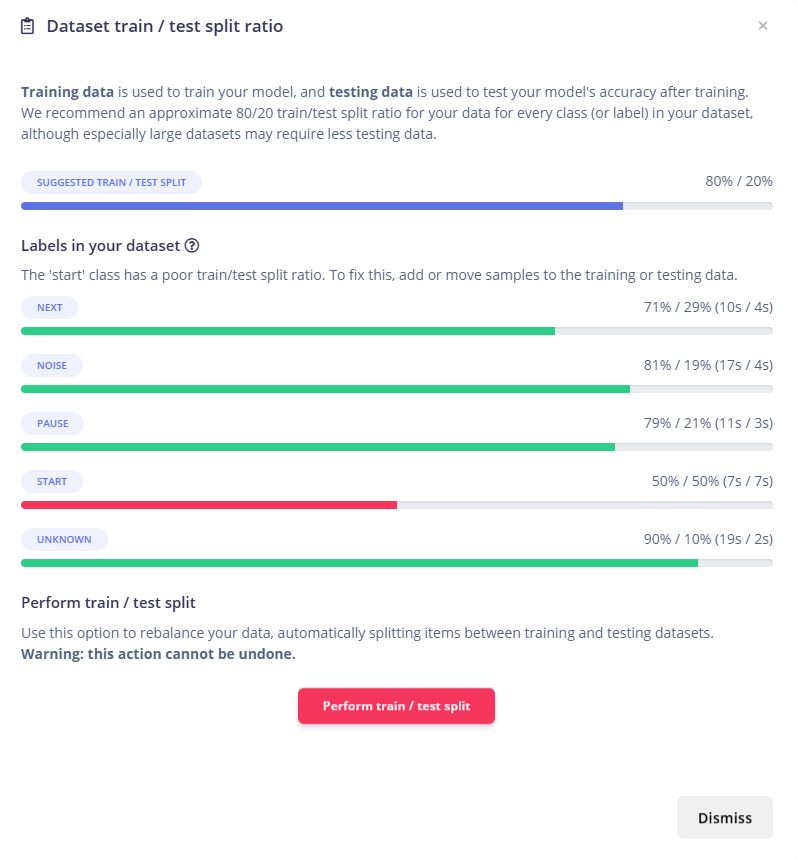
3. 训练/测试集划分
数据采集完成后,通过Edge Impulse的"Perform train/test split"功能自动将数据集按照约80%/20%的比例划分为训练集和测试集。初始划分时发现"start"类别的训练/测试比例为50%/50%,存在不均衡问题。
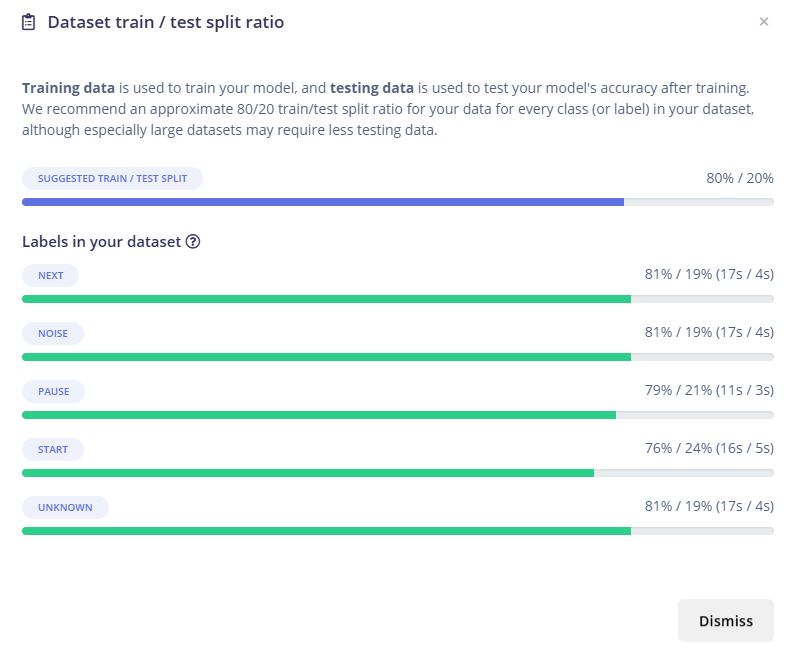
执行自动划分操作后,各类别的比例趋于合理:
二、Impulse设计与特征提取
1. 创建Impulse
在Edge Impulse的"Create impulse"页面中配置处理管线:
- 时间序列数据块:输入轴为audio,窗口大小设置为1000ms,窗口步进(stride)为500ms,采样频率16000Hz,启用Zero-pad data
- 处理块:选择Audio (MFCC),提取梅尔频率倒谱系数作为语音特征
- 学习块:选择Classification分类器
- 输出特征:5个类别(next, noise, pause, start, unknown)
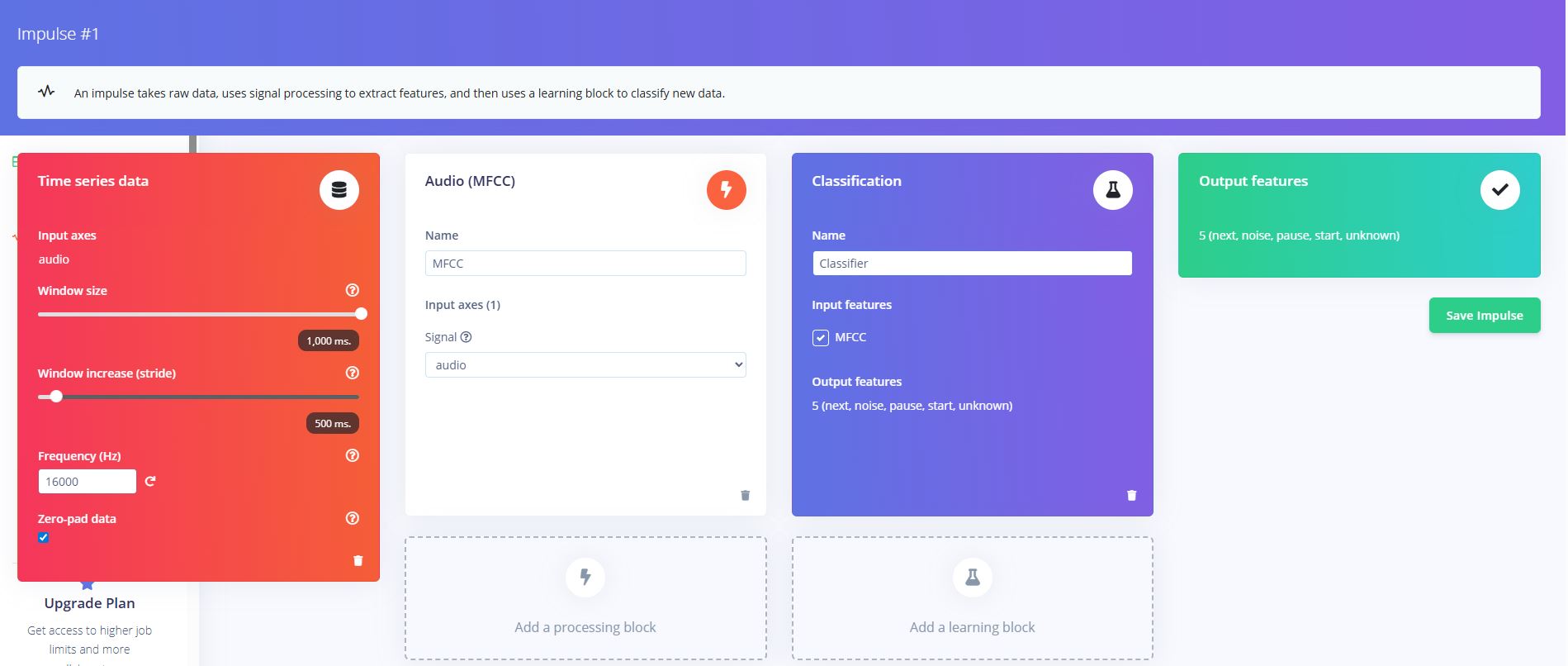
2. MFCC特征参数
MFCC处理块将原始音频信号转换为637维特征向量,通过对音频信号进行短时傅里叶变换、梅尔滤波器组映射和离散余弦变换,提取出能够有效表征语音内容的频谱特征。
三、模型训练与评估
1. 神经网络架构
分类器采用1D卷积神经网络架构,具体网络结构如下:
textInput layer (637 features)
↓
Reshape layer (13 columns)
↓
1D conv/pool layer (8 filters, 3 kernel size, 1 layer)
↓
Dropout (rate 0.25)
↓
1D conv/pool layer (16 filters, 3 kernel size, 1 layer)
↓
Dropout (rate 0.25)
↓
Flatten layer
↓
Output layer (5 classes)
模型版本选择Quantized (int8)以适配ESP32-S3的有限计算资源。
2. 训练结果
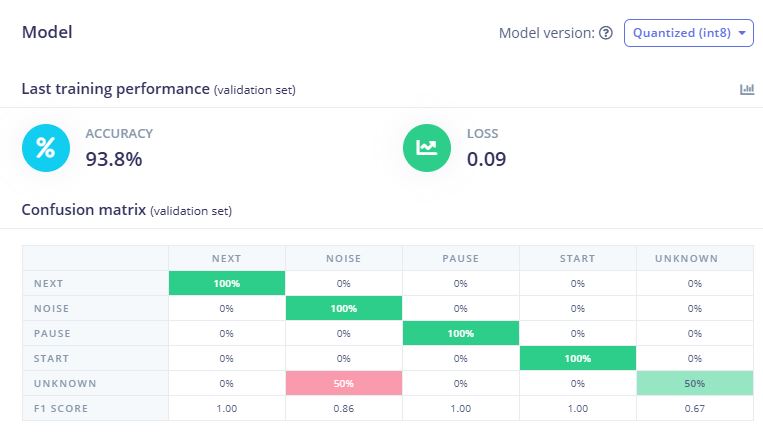
模型在验证集上取得了优异的分类性能:
- 准确率(Accuracy):93.8%
- 损失值(Loss):0.09
混淆矩阵显示,三个关键词指令(NEXT、PAUSE、START)均达到100%的识别准确率,NOISE类别也达到100%。UNKNOWN类别有50%被误分类为NOISE,这在实际应用中影响较小,因为两者都属于非指令类别。
3. 模型导出
训练完成后,将模型导出为Arduino库格式(esp32-XIAO-voice_inferencing),直接集成到Arduino项目中使用。
代码详解
整体软件架构
%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22160%22%20x%3D%22387%22%20y%3D%22105.1328%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22140%22%20x%3D%22397%22%20y%3D%22127.1997%22%3E%26%2321019%3B%26%2324314%3BFreeRTOS%26%2321629%3B%26%2320196%3B%26%2338431%3B%26%2321015%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22133%22%20x%3D%22400.5%22%20y%3D%22160.2656%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22113%22%20x%3D%22410.5%22%20y%3D%22182.3325%22%3E%26%2321021%3B%26%2322987%3B%26%2321270%3BOLED%26%2326174%3B%26%2331034%3B%26%2323631%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22134%22%20x%3D%22400%22%20y%3D%22215.3984%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22114%22%20x%3D%22410%22%20y%3D%22237.4653%22%3E%26%2326174%3B%26%2331034%3B%20%22Initializing...%22%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22185%22%20x%3D%22374.5%22%20y%3D%22270.5313%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22104%22%20x%3D%22384.5%22%20y%3D%22292.5981%22%3E%26%2321021%3B%26%2322987%3B%26%2321270%3B%26%2338899%3B%26%2339057%3B%26%2325773%3B%26%2325918%3B%26%2322120%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22165%22%20x%3D%22384.5%22%20y%3D%22307.731%22%3E(SD%26%2321345%3B%26%2325346%3B%26%2336733%3B%20%2B%20I2S%20DAC%26%2337197%3B%26%2332622%3B)%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22157%22%20x%3D%22388.5%22%20y%3D%22340.7969%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22137%22%20x%3D%22398.5%22%20y%3D%22362.8638%22%3E%26%2325195%3B%26%2325551%3BSD%26%2321345%3BMP3%26%2325991%3B%26%2320214%3B%26%2321015%3B%26%2334920%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23555555%22%20height%3D%226%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23555555%3Bstroke-width%3A1.0%3B%22%20width%3D%22919.9375%22%20x%3D%2211%22%20y%3D%22395.9297%22%2F%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2251.4297%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22114%22%20x%3D%22464.4375%22%20y%3D%22567.2383%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2214%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2294%22%20x%3D%22474.4375%22%20y%3D%22590.2334%22%3ECore%200%20%3D%3D%3D%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2278%22%20x%3D%22474.4375%22%20y%3D%22605.6021%22%3E%26%2335821%3B%26%2338899%3B%26%2335782%3B%26%2321035%3B%26%2320219%3B%26%2321153%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22151%22%20x%3D%22445.9375%22%20y%3D%22714.4727%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22120%22%20x%3D%22455.9375%22%20y%3D%22736.5396%22%3EPDM%26%2340614%3B%26%2320811%3B%26%2339118%3B%26%2336830%3B%26%2332493%3B%26%2337319%3B%26%2338598%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22131%22%20x%3D%22455.9375%22%20y%3D%22751.6724%22%3E(16kHz%2C%20%26%2339281%3B%26%2321644%3B%26%2322686%3B%26%2330410%3B8%26%2320493%3B)%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22111%22%20x%3D%22465.9375%22%20y%3D%22797.1094%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2291%22%20x%3D%22475.9375%22%20y%3D%22819.1763%22%3E%26%2320889%3B%26%2320837%3B%26%2329615%3B%26%2324418%3B%26%2332531%3B%26%2320914%3B%26%2321306%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22465.9375%2C867.2422%2C576.9375%2C867.2422%2C588.9375%2C879.2422%2C576.9375%2C891.2422%2C465.9375%2C891.2422%2C453.9375%2C879.2422%2C465.9375%2C867.2422%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22111%22%20x%3D%22465.9375%22%20y%3D%22883.7427%22%3E%26%2326032%3B%26%2337319%3B%26%2326679%3B%20%26%238805%3B%201%2F6%26%2331383%3B%26%2321475%3B%3F%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22442.9375%22%20y%3D%22876.6479%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22588.9375%22%20y%3D%22876.6479%22%3E%26%2321542%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22156%22%20x%3D%22318.875%22%20y%3D%22901.2422%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22136%22%20x%3D%22328.875%22%20y%3D%22923.3091%22%3E%26%2324555%3B%26%2329031%3B%26%2322797%3B%26%2321046%3B%20%26%238594%3B%20%26%2325512%3B%26%2329702%3B%26%2332531%3B%26%2320914%3B%26%2321306%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22108%22%20x%3D%22342.875%22%20y%3D%22971.375%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2288%22%20x%3D%22352.875%22%20y%3D%22993.4419%22%3EMFCC%26%2329305%3B%26%2324449%3B%26%2325552%3B%26%2321462%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2273%22%20x%3D%22352.875%22%20y%3D%221008.5747%22%3E(637%26%2332500%3B%26%2321521%3B%26%2337327%3B)%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22188%22%20x%3D%22302.875%22%20y%3D%221056.6406%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22168%22%20x%3D%22312.875%22%20y%3D%221078.7075%22%3EEdge%20Impulse%201D-CNN%26%2325512%3B%26%2329702%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22354.375%2C1126.7734%2C439.375%2C1126.7734%2C451.375%2C1138.7734%2C439.375%2C1150.7734%2C354.375%2C1150.7734%2C342.375%2C1138.7734%2C354.375%2C1126.7734%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2285%22%20x%3D%22354.375%22%20y%3D%221143.2739%22%3E%26%2332622%3B%26%2320449%3B%26%2324230%3B%20%26gt%3B%200.8%3F%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22331.375%22%20y%3D%221136.1792%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22451.375%22%20y%3D%221136.1792%22%3E%26%2321542%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22209.75%2C1160.7734%2C341.75%2C1160.7734%2C353.75%2C1172.7734%2C341.75%2C1184.7734%2C209.75%2C1184.7734%2C197.75%2C1172.7734%2C209.75%2C1160.7734%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22132%22%20x%3D%22209.75%22%20y%3D%221177.2739%22%3E%26%2336830%3B%26%2332493%3B%26%2330830%3B%26%2335748%3B%20%26%2319988%3B%20%26%2320919%3B%26%2321364%3B%26%2326399%3B%26%2322806%3B%3F%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22186.75%22%20y%3D%221170.1792%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22353.75%22%20y%3D%221170.1792%22%3E%26%2321542%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22267%22%20x%3D%2241%22%20y%3D%221194.7734%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22123%22%20x%3D%2251%22%20y%3D%221216.8403%22%3E%26%2326144%3B%26%2323556%3B%26%2335821%3B%26%2338899%3B%26%2326631%3B%26%2331614%3B%20%26%238594%3B%20%26%2321629%3B%26%2320196%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22247%22%20x%3D%2251%22%20y%3D%221231.9731%22%3E(start%26%238594%3B%26%2325773%3B%26%2325918%3B%2C%20pause%26%238594%3B%26%2326242%3B%26%2320572%3B%2C%20next%26%238594%3B%26%2319979%3B%26%2319968%3B%26%2326354%3B)%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22134%22%20x%3D%22107.5%22%20y%3D%221280.0391%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22114%22%20x%3D%22117.5%22%20y%3D%221302.106%22%3E%26%2321457%3B%26%2336865%3B%26%2321629%3B%26%2320196%3B%26%2333267%3BxQueue%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%2298%22%20x%3D%22328%22%20y%3D%221194.7734%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2278%22%20x%3D%22338%22%20y%3D%221216.8403%22%3E%26%2325233%3B%26%2321046%3B%26%2337325%3B%26%2322797%3B%26%2335302%3B%26%2321457%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22275.75%2C1321.1719%2C287.75%2C1333.1719%2C275.75%2C1345.1719%2C263.75%2C1333.1719%2C275.75%2C1321.1719%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22124%22%20x%3D%22456%22%20y%3D%221160.7734%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22104%22%20x%3D%22466%22%20y%3D%221182.8403%22%3E%26%2324573%3B%26%2330053%3B%26%2320302%3B%26%2332622%3B%26%2320449%3B%26%2324230%3B%26%2332467%3B%26%2326524%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22396.875%2C1351.1719%2C408.875%2C1363.1719%2C396.875%2C1375.1719%2C384.875%2C1363.1719%2C396.875%2C1351.1719%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%2272%22%20x%3D%22609.9375%22%20y%3D%22901.2422%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2252%22%20x%3D%22619.9375%22%20y%3D%22923.3091%22%3E%26%2332487%3B%26%2332493%3B%26%2337319%3B%26%2338598%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22521.4375%2C1381.1719%2C533.4375%2C1393.1719%2C521.4375%2C1405.1719%2C509.4375%2C1393.1719%2C521.4375%2C1381.1719%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22485.4375%2C653.668%2C557.4375%2C653.668%2C569.4375%2C665.668%2C557.4375%2C677.668%2C485.4375%2C677.668%2C473.4375%2C665.668%2C485.4375%2C653.668%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22525.4375%22%20y%3D%22687.8784%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%22485.4375%22%20y%3D%22670.1685%22%3E%26%2331995%3B%26%2332479%3B%26%2336816%3B%26%2334892%3B%26%2320013%3B%3F%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2251.4297%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22114%22%20x%3D%22756.4375%22%20y%3D%22421.9297%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2214%22%20font-weight%3D%22bold%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2294%22%20x%3D%22766.4375%22%20y%3D%22444.9248%22%3ECore%201%20%3D%3D%3D%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2265%22%20x%3D%22766.4375%22%20y%3D%22460.2935%22%3E%26%2320027%3B%26%2324490%3B%26%2329615%3B%26%2320219%3B%26%2321153%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22138%22%20x%3D%22744.4375%22%20y%3D%22493.3594%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22118%22%20x%3D%22754.4375%22%20y%3D%22515.4263%22%3E%26%2333258%3B%26%2321160%3B%26%2325773%3B%26%2325918%3B%26%2331532%3B%26%2319968%3B%26%2339318%3BMP3%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%2298%22%20x%3D%22764.4375%22%20y%3D%22657.6992%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2278%22%20x%3D%22774.4375%22%20y%3D%22679.7661%22%3E%26%2321462%3B%26%2320986%3B%26%2335821%3B%26%2338899%3B%26%2321629%3B%26%2320196%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%2298%22%20x%3D%22764.4375%22%20y%3D%22727.832%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2278%22%20x%3D%22774.4375%22%20y%3D%22749.8989%22%3E%26%2325191%3B%26%2334892%3B%26%2323545%3B%26%2324212%3B%26%2325805%3B%26%2320316%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22764.4375%2C609.2969%2C862.4375%2C609.2969%2C874.4375%2C621.2969%2C862.4375%2C633.2969%2C764.4375%2C633.2969%2C752.4375%2C621.2969%2C764.4375%2C609.2969%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22817.4375%22%20y%3D%22643.5073%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2298%22%20x%3D%22764.4375%22%20y%3D%22625.7974%22%3E%26%2321629%3B%26%2320196%3B%26%2338431%3B%26%2321015%3B%26%2326377%3B%26%2325968%3B%26%2325454%3B%3F%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22813.4375%2C784.7383%2C825.4375%2C796.7383%2C813.4375%2C808.7383%2C801.4375%2C796.7383%2C813.4375%2C784.7383%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%2298%22%20x%3D%22764.4375%22%20y%3D%22892.1406%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2278%22%20x%3D%22774.4375%22%20y%3D%22914.2075%22%3E%26%2335299%3B%26%2326512%3B%26%2320018%3B%26%2321475%3B%26%2321629%3B%26%2320196%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2277%22%20x%3D%22774.4375%22%20y%3D%22929.3403%22%3E(p%2Fs%2Fn%2Fb%2F%2B%2F-)%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%2298%22%20x%3D%22764.4375%22%20y%3D%22977.4063%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2278%22%20x%3D%22774.4375%22%20y%3D%22999.4731%22%3E%26%2325191%3B%26%2334892%3B%26%2323545%3B%26%2324212%3B%26%2325805%3B%26%2320316%3B%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22770.9375%2C843.7383%2C855.9375%2C843.7383%2C867.9375%2C855.7383%2C855.9375%2C867.7383%2C770.9375%2C867.7383%2C758.9375%2C855.7383%2C770.9375%2C843.7383%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22817.4375%22%20y%3D%22877.9487%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2285%22%20x%3D%22770.9375%22%20y%3D%22860.2388%22%3E%26%2320018%3B%26%2321475%3B%26%2325910%3B%26%2321040%3B%26%2323383%3B%26%2331526%3B%3F%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22813.4375%2C1036.9414%2C825.4375%2C1048.9414%2C813.4375%2C1060.9414%2C801.4375%2C1048.9414%2C813.4375%2C1036.9414%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22175%22%20x%3D%22725.9375%22%20y%3D%221095.9414%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22155%22%20x%3D%22735.9375%22%20y%3D%221118.0083%22%3E%26%2335843%3B%26%2329992%3B%20audio_player_loop()%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2292%22%20x%3D%22735.9375%22%20y%3D%221133.1411%22%3E%26%2325512%3B%26%2336827%3BMP3%26%2324103%3B%26%2335299%3B%26%2330721%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22111%22%20x%3D%22757.9375%22%20y%3D%221229.6094%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2291%22%20x%3D%22767.9375%22%20y%3D%221251.6763%22%3E%26%2333258%3B%26%2321160%3B%26%2325773%3B%26%2325918%3B%26%2319979%3B%26%2319968%3B%26%2339318%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2262%22%20x%3D%22767.9375%22%20y%3D%221266.8091%22%3E(%26%2324490%3B%26%2329615%3B%26%2325773%3B%26%2325918%3B)%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22757.9375%2C1181.207%2C868.9375%2C1181.207%2C880.9375%2C1193.207%2C868.9375%2C1205.207%2C757.9375%2C1205.207%2C745.9375%2C1193.207%2C757.9375%2C1181.207%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22817.4375%22%20y%3D%221215.4175%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22111%22%20x%3D%22757.9375%22%20y%3D%221197.7075%22%3E%26%2324403%3B%26%2321069%3B%26%2326354%3B%26%2330446%3B%26%2325773%3B%26%2325918%3B%26%2323436%3B%26%2327605%3B%3F%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22813.4375%2C1304.2773%2C825.4375%2C1316.2773%2C813.4375%2C1328.2773%2C801.4375%2C1316.2773%2C813.4375%2C1304.2773%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2235.1328%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22111%22%20x%3D%22757.9375%22%20y%3D%221411.6797%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2291%22%20x%3D%22767.9375%22%20y%3D%221433.7466%22%3E%26%2333719%3B%26%2321462%3B%26%2325773%3B%26%2325918%3B%26%2322120%3B%26%2329366%3B%26%2324577%3B%3C%2Ftext%3E%3Crect%20fill%3D%22%23F5F5F5%22%20height%3D%2250.2656%22%20rx%3D%2212.5%22%20ry%3D%2212.5%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%20width%3D%22116%22%20x%3D%22755.4375%22%20y%3D%221476.7461%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2287%22%20x%3D%22765.4375%22%20y%3D%221498.813%22%3EOLED%26%2321047%3B%26%2326032%3B%26%2326174%3B%26%2331034%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2296%22%20x%3D%22765.4375%22%20y%3D%221513.9458%22%3E(%26%2326354%3B%26%2330446%3B%2F%26%2336827%3B%26%2324230%3B%2F%26%2338899%3B%26%2337327%3B)%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22745.9375%2C1363.2773%2C880.9375%2C1363.2773%2C892.9375%2C1375.2773%2C880.9375%2C1387.2773%2C745.9375%2C1387.2773%2C733.9375%2C1375.2773%2C745.9375%2C1363.2773%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22817.4375%22%20y%3D%221397.4878%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%22135%22%20x%3D%22745.9375%22%20y%3D%221379.7778%22%3E%26%2336317%3B%26%2319978%3B%26%2327425%3B%26%2321047%3B%26%2326032%3B%20%26gt%3B%20500ms%3F%3C%2Ftext%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22813.4375%2C1547.0117%2C825.4375%2C1559.0117%2C813.4375%2C1571.0117%2C801.4375%2C1559.0117%2C813.4375%2C1547.0117%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Cpolygon%20fill%3D%22%23F5F5F5%22%20points%3D%22777.4375%2C548.4922%2C849.4375%2C548.4922%2C861.4375%2C560.4922%2C849.4375%2C572.4922%2C777.4375%2C572.4922%2C765.4375%2C560.4922%2C777.4375%2C548.4922%22%20style%3D%22stroke%3A%23333333%3Bstroke-width%3A0.5%3B%22%2F%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22sans-serif%22%20font-size%3D%2211%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2211%22%20x%3D%22817.4375%22%20y%3D%22582.7026%22%3E%26%2326159%3B%3C%2Ftext%3E%3Ctext%20fill%3D%22%23000000%22%20font-family%3D%22%26%2324494%3B%26%2336719%3B%26%2338597%3B%26%2340657%3B%22%20font-size%3D%2213%22%20lengthAdjust%3D%22spacing%22%20textLength%3D%2272%22%20x%3D%22777.4375%22%20y%3D%22564.9927%22%3E%26%2331995%3B%26%2332479%3B%26%2336816%3B%26%2334892%3B%26%2320013%3B%3F%3C%2Ftext%3E%3Crect%20fill%3D%22%23555555%22%20height%3D%226%22%20rx%3D%222.5%22%20ry%3D%222.5%22%20style%3D%22stroke%3A%23555555%3Bstroke-width%3A1.0%3B%22%20width%3D%22919.9375%22%20x%3D%2211%22%20y%3D%221613.0117%22%2F%3E%3Cellipse%20cx%3D%22467%22%20cy%3D%221650.0117%22%20fill%3D%22none%22%20rx%3D%2211%22%20ry%3D%2211%22%20style%3D%22stroke%3A%23222222%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cellipse%20cx%3D%22467%22%20cy%3D%221650.0117%22%20fill%3D%22%23222222%22%20rx%3D%226%22%20ry%3D%226%22%20style%3D%22stroke%3A%23222222%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%2230%22%20y2%3D%2250%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C40%2C467%2C50%2C471%2C40%2C467%2C44%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%2285.1328%22%20y2%3D%22105.1328%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C95.1328%2C467%2C105.1328%2C471%2C95.1328%2C467%2C99.1328%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%22140.2656%22%20y2%3D%22160.2656%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C150.2656%2C467%2C160.2656%2C471%2C150.2656%2C467%2C154.2656%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%22195.3984%22%20y2%3D%22215.3984%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C205.3984%2C467%2C215.3984%2C471%2C205.3984%2C467%2C209.3984%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%22250.5313%22%20y2%3D%22270.5313%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C260.5313%2C467%2C270.5313%2C471%2C260.5313%2C467%2C264.5313%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%22320.7969%22%20y2%3D%22340.7969%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C330.7969%2C467%2C340.7969%2C471%2C330.7969%2C467%2C334.7969%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%22764.7383%22%20y2%3D%22797.1094%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22517.4375%2C787.1094%2C521.4375%2C797.1094%2C525.4375%2C787.1094%2C521.4375%2C791.1094%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22396.875%22%20x2%3D%22396.875%22%20y1%3D%22936.375%22%20y2%3D%22971.375%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22392.875%2C961.375%2C396.875%2C971.375%2C400.875%2C961.375%2C396.875%2C965.375%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22396.875%22%20x2%3D%22396.875%22%20y1%3D%221021.6406%22%20y2%3D%221056.6406%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22392.875%2C1046.6406%2C396.875%2C1056.6406%2C400.875%2C1046.6406%2C396.875%2C1050.6406%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22174.5%22%20x2%3D%22174.5%22%20y1%3D%221245.0391%22%20y2%3D%221280.0391%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22170.5%2C1270.0391%2C174.5%2C1280.0391%2C178.5%2C1270.0391%2C174.5%2C1274.0391%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22197.75%22%20x2%3D%22174.5%22%20y1%3D%221172.7734%22%20y2%3D%221172.7734%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22174.5%22%20x2%3D%22174.5%22%20y1%3D%221172.7734%22%20y2%3D%221194.7734%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22170.5%2C1184.7734%2C174.5%2C1194.7734%2C178.5%2C1184.7734%2C174.5%2C1188.7734%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22353.75%22%20x2%3D%22377%22%20y1%3D%221172.7734%22%20y2%3D%221172.7734%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22377%22%20x2%3D%22377%22%20y1%3D%221172.7734%22%20y2%3D%221194.7734%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22373%2C1184.7734%2C377%2C1194.7734%2C381%2C1184.7734%2C377%2C1188.7734%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22174.5%22%20x2%3D%22174.5%22%20y1%3D%221315.1719%22%20y2%3D%221333.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22174.5%22%20x2%3D%22263.75%22%20y1%3D%221333.1719%22%20y2%3D%221333.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22253.75%2C1329.1719%2C263.75%2C1333.1719%2C253.75%2C1337.1719%2C257.75%2C1333.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22377%22%20x2%3D%22377%22%20y1%3D%221229.9063%22%20y2%3D%221333.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22377%22%20x2%3D%22287.75%22%20y1%3D%221333.1719%22%20y2%3D%221333.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22297.75%2C1329.1719%2C287.75%2C1333.1719%2C297.75%2C1337.1719%2C293.75%2C1333.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22342.375%22%20x2%3D%22275.75%22%20y1%3D%221138.7734%22%20y2%3D%221138.7734%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22275.75%22%20x2%3D%22275.75%22%20y1%3D%221138.7734%22%20y2%3D%221160.7734%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22271.75%2C1150.7734%2C275.75%2C1160.7734%2C279.75%2C1150.7734%2C275.75%2C1154.7734%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22451.375%22%20x2%3D%22518%22%20y1%3D%221138.7734%22%20y2%3D%221138.7734%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22518%22%20x2%3D%22518%22%20y1%3D%221138.7734%22%20y2%3D%221160.7734%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22514%2C1150.7734%2C518%2C1160.7734%2C522%2C1150.7734%2C518%2C1154.7734%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22275.75%22%20x2%3D%22275.75%22%20y1%3D%221345.1719%22%20y2%3D%221363.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22275.75%22%20x2%3D%22384.875%22%20y1%3D%221363.1719%22%20y2%3D%221363.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22374.875%2C1359.1719%2C384.875%2C1363.1719%2C374.875%2C1367.1719%2C378.875%2C1363.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22518%22%20x2%3D%22518%22%20y1%3D%221195.9063%22%20y2%3D%221363.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22518%22%20x2%3D%22408.875%22%20y1%3D%221363.1719%22%20y2%3D%221363.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22418.875%2C1359.1719%2C408.875%2C1363.1719%2C418.875%2C1367.1719%2C414.875%2C1363.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22396.875%22%20x2%3D%22396.875%22%20y1%3D%221091.7734%22%20y2%3D%221126.7734%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22392.875%2C1116.7734%2C396.875%2C1126.7734%2C400.875%2C1116.7734%2C396.875%2C1120.7734%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22453.9375%22%20x2%3D%22396.875%22%20y1%3D%22879.2422%22%20y2%3D%22879.2422%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22396.875%22%20x2%3D%22396.875%22%20y1%3D%22879.2422%22%20y2%3D%22901.2422%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22392.875%2C891.2422%2C396.875%2C901.2422%2C400.875%2C891.2422%2C396.875%2C895.2422%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22588.9375%22%20x2%3D%22645.9375%22%20y1%3D%22879.2422%22%20y2%3D%22879.2422%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22645.9375%22%20x2%3D%22645.9375%22%20y1%3D%22879.2422%22%20y2%3D%22901.2422%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22641.9375%2C891.2422%2C645.9375%2C901.2422%2C649.9375%2C891.2422%2C645.9375%2C895.2422%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22396.875%22%20x2%3D%22396.875%22%20y1%3D%221375.1719%22%20y2%3D%221393.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22396.875%22%20x2%3D%22509.4375%22%20y1%3D%221393.1719%22%20y2%3D%221393.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22499.4375%2C1389.1719%2C509.4375%2C1393.1719%2C499.4375%2C1397.1719%2C503.4375%2C1393.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22645.9375%22%20x2%3D%22645.9375%22%20y1%3D%22936.375%22%20y2%3D%221393.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22645.9375%22%20x2%3D%22533.4375%22%20y1%3D%221393.1719%22%20y2%3D%221393.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22543.4375%2C1389.1719%2C533.4375%2C1393.1719%2C543.4375%2C1397.1719%2C539.4375%2C1393.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%22832.2422%22%20y2%3D%22867.2422%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22517.4375%2C857.2422%2C521.4375%2C867.2422%2C525.4375%2C857.2422%2C521.4375%2C861.2422%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%22677.668%22%20y2%3D%22714.4727%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22517.4375%2C704.4727%2C521.4375%2C714.4727%2C525.4375%2C704.4727%2C521.4375%2C708.4727%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%221405.1719%22%20y2%3D%221417.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22695.9375%22%20y1%3D%221417.1719%22%20y2%3D%221417.1719%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22691.9375%2C1050.1055%2C695.9375%2C1040.1055%2C699.9375%2C1050.1055%2C695.9375%2C1046.1055%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22695.9375%22%20x2%3D%22695.9375%22%20y1%3D%22665.668%22%20y2%3D%221417.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22695.9375%22%20x2%3D%22569.4375%22%20y1%3D%22665.668%22%20y2%3D%22665.668%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22579.4375%2C661.668%2C569.4375%2C665.668%2C579.4375%2C669.668%2C575.4375%2C665.668%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22473.4375%22%20x2%3D%2227%22%20y1%3D%22665.668%22%20y2%3D%22665.668%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%2223%2C1036.1055%2C27%2C1046.1055%2C31%2C1036.1055%2C27%2C1040.1055%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%2227%22%20x2%3D%2227%22%20y1%3D%22665.668%22%20y2%3D%221429.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%2227%22%20x2%3D%22521.4375%22%20y1%3D%221429.1719%22%20y2%3D%221429.1719%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%221429.1719%22%20y2%3D%221613.0117%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22517.4375%2C1603.0117%2C521.4375%2C1613.0117%2C525.4375%2C1603.0117%2C521.4375%2C1607.0117%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%22618.668%22%20y2%3D%22653.668%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22517.4375%2C643.668%2C521.4375%2C653.668%2C525.4375%2C643.668%2C521.4375%2C647.668%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22473.3594%22%20y2%3D%22493.3594%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C483.3594%2C813.4375%2C493.3594%2C817.4375%2C483.3594%2C813.4375%2C487.3594%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22692.832%22%20y2%3D%22727.832%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C717.832%2C813.4375%2C727.832%2C817.4375%2C717.832%2C813.4375%2C721.832%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22633.2969%22%20y2%3D%22657.6992%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C647.6992%2C813.4375%2C657.6992%2C817.4375%2C647.6992%2C813.4375%2C651.6992%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22874.4375%22%20x2%3D%22886.4375%22%20y1%3D%22621.2969%22%20y2%3D%22621.2969%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22882.4375%2C700.332%2C886.4375%2C710.332%2C890.4375%2C700.332%2C886.4375%2C704.332%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22886.4375%22%20x2%3D%22886.4375%22%20y1%3D%22621.2969%22%20y2%3D%22796.7383%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22886.4375%22%20x2%3D%22825.4375%22%20y1%3D%22796.7383%22%20y2%3D%22796.7383%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22835.4375%2C792.7383%2C825.4375%2C796.7383%2C835.4375%2C800.7383%2C831.4375%2C796.7383%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22762.9648%22%20y2%3D%22784.7383%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C774.7383%2C813.4375%2C784.7383%2C817.4375%2C774.7383%2C813.4375%2C778.7383%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22942.4063%22%20y2%3D%22977.4063%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C967.4063%2C813.4375%2C977.4063%2C817.4375%2C967.4063%2C813.4375%2C971.4063%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22867.7383%22%20y2%3D%22892.1406%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C882.1406%2C813.4375%2C892.1406%2C817.4375%2C882.1406%2C813.4375%2C886.1406%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22867.9375%22%20x2%3D%22879.9375%22%20y1%3D%22855.7383%22%20y2%3D%22855.7383%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22875.9375%2C942.3398%2C879.9375%2C952.3398%2C883.9375%2C942.3398%2C879.9375%2C946.3398%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22879.9375%22%20x2%3D%22879.9375%22%20y1%3D%22855.7383%22%20y2%3D%221048.9414%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22879.9375%22%20x2%3D%22825.4375%22%20y1%3D%221048.9414%22%20y2%3D%221048.9414%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22835.4375%2C1044.9414%2C825.4375%2C1048.9414%2C835.4375%2C1052.9414%2C831.4375%2C1048.9414%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221012.5391%22%20y2%3D%221036.9414%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1026.9414%2C813.4375%2C1036.9414%2C817.4375%2C1026.9414%2C813.4375%2C1030.9414%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22808.7383%22%20y2%3D%22843.7383%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C833.7383%2C813.4375%2C843.7383%2C817.4375%2C833.7383%2C813.4375%2C837.7383%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221060.9414%22%20y2%3D%221095.9414%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1085.9414%2C813.4375%2C1095.9414%2C817.4375%2C1085.9414%2C813.4375%2C1089.9414%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221205.207%22%20y2%3D%221229.6094%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1219.6094%2C813.4375%2C1229.6094%2C817.4375%2C1219.6094%2C813.4375%2C1223.6094%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22880.9375%22%20x2%3D%22892.9375%22%20y1%3D%221193.207%22%20y2%3D%221193.207%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22888.9375%2C1244.7422%2C892.9375%2C1254.7422%2C896.9375%2C1244.7422%2C892.9375%2C1248.7422%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22892.9375%22%20x2%3D%22892.9375%22%20y1%3D%221193.207%22%20y2%3D%221316.2773%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22892.9375%22%20x2%3D%22825.4375%22%20y1%3D%221316.2773%22%20y2%3D%221316.2773%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22835.4375%2C1312.2773%2C825.4375%2C1316.2773%2C835.4375%2C1320.2773%2C831.4375%2C1316.2773%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221279.875%22%20y2%3D%221304.2773%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1294.2773%2C813.4375%2C1304.2773%2C817.4375%2C1294.2773%2C813.4375%2C1298.2773%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221146.207%22%20y2%3D%221181.207%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1171.207%2C813.4375%2C1181.207%2C817.4375%2C1171.207%2C813.4375%2C1175.207%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221446.8125%22%20y2%3D%221476.7461%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1466.7461%2C813.4375%2C1476.7461%2C817.4375%2C1466.7461%2C813.4375%2C1470.7461%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221387.2773%22%20y2%3D%221411.6797%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1401.6797%2C813.4375%2C1411.6797%2C817.4375%2C1401.6797%2C813.4375%2C1405.6797%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22892.9375%22%20x2%3D%22904.9375%22%20y1%3D%221375.2773%22%20y2%3D%221375.2773%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22900.9375%2C1456.8125%2C904.9375%2C1466.8125%2C908.9375%2C1456.8125%2C904.9375%2C1460.8125%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22904.9375%22%20x2%3D%22904.9375%22%20y1%3D%221375.2773%22%20y2%3D%221559.0117%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22904.9375%22%20x2%3D%22825.4375%22%20y1%3D%221559.0117%22%20y2%3D%221559.0117%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22835.4375%2C1555.0117%2C825.4375%2C1559.0117%2C835.4375%2C1563.0117%2C831.4375%2C1559.0117%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221527.0117%22%20y2%3D%221547.0117%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1537.0117%2C813.4375%2C1547.0117%2C817.4375%2C1537.0117%2C813.4375%2C1541.0117%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221328.2773%22%20y2%3D%221363.2773%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1353.2773%2C813.4375%2C1363.2773%2C817.4375%2C1353.2773%2C813.4375%2C1357.2773%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22572.4922%22%20y2%3D%22609.2969%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C599.2969%2C813.4375%2C609.2969%2C817.4375%2C599.2969%2C813.4375%2C603.2969%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221571.0117%22%20y2%3D%221581.0117%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22916.9375%22%20y1%3D%221581.0117%22%20y2%3D%221581.0117%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22912.9375%2C1085.1719%2C916.9375%2C1075.1719%2C920.9375%2C1085.1719%2C916.9375%2C1081.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22916.9375%22%20x2%3D%22916.9375%22%20y1%3D%22560.4922%22%20y2%3D%221581.0117%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22916.9375%22%20x2%3D%22861.4375%22%20y1%3D%22560.4922%22%20y2%3D%22560.4922%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22871.4375%2C556.4922%2C861.4375%2C560.4922%2C871.4375%2C564.4922%2C867.4375%2C560.4922%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22765.4375%22%20x2%3D%22713.9375%22%20y1%3D%22560.4922%22%20y2%3D%22560.4922%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22709.9375%2C1071.1719%2C713.9375%2C1081.1719%2C717.9375%2C1071.1719%2C713.9375%2C1075.1719%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22713.9375%22%20x2%3D%22713.9375%22%20y1%3D%22560.4922%22%20y2%3D%221593.0117%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22713.9375%22%20x2%3D%22813.4375%22%20y1%3D%221593.0117%22%20y2%3D%221593.0117%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%221593.0117%22%20y2%3D%221613.0117%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C1603.0117%2C813.4375%2C1613.0117%2C817.4375%2C1603.0117%2C813.4375%2C1607.0117%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22528.4922%22%20y2%3D%22548.4922%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C538.4922%2C813.4375%2C548.4922%2C817.4375%2C538.4922%2C813.4375%2C542.4922%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22521.4375%22%20x2%3D%22521.4375%22%20y1%3D%22401.9297%22%20y2%3D%22567.2383%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22517.4375%2C557.2383%2C521.4375%2C567.2383%2C525.4375%2C557.2383%2C521.4375%2C561.2383%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22813.4375%22%20x2%3D%22813.4375%22%20y1%3D%22401.9297%22%20y2%3D%22421.9297%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22809.4375%2C411.9297%2C813.4375%2C421.9297%2C817.4375%2C411.9297%2C813.4375%2C415.9297%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%22375.9297%22%20y2%3D%22395.9297%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C385.9297%2C467%2C395.9297%2C471%2C385.9297%2C467%2C389.9297%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3Cline%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%20x1%3D%22467%22%20x2%3D%22467%22%20y1%3D%221619.0117%22%20y2%3D%221639.0117%22%2F%3E%3Cpolygon%20fill%3D%22%23181818%22%20points%3D%22463%2C1629.0117%2C467%2C1639.0117%2C471%2C1629.0117%2C467%2C1633.0117%22%20style%3D%22stroke%3A%23181818%3Bstroke-width%3A1.0%3B%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)
系统采用模块化设计,共包含4个核心模块:
文件 | 功能 |
|---|---|
| 主程序,任务调度与命令分发 |
| MP3解码播放,SD卡管理 |
| PDM采集与Edge Impulse推理 |
| OLED显示驱动 |
一、主程序与双核任务调度
系统启动后在setup()函数中完成初始化序列,关键流程如下:
- 创建FreeRTOS命令队列(容量10条),用于语音识别模块向播放器模块传递指令
- 初始化OLED显示屏,显示"Initializing..."启动提示
- 初始化音频播放器(SD卡挂载 + I2S DAC配置)
- 在Core 0上创建语音识别任务,分配32KB栈空间(神经网络推理需要大栈)
- 自动播放第一首MP3文件
void setup() {
Serial.begin(115200);
// 创建命令队列
commandQueue = xQueueCreate(10, sizeof(player_cmd_t));
// 初始化显示
display_init();
display_show_message("Initializing...");
// 初始化播放器(SD卡 + I2S DAC)
audio_player_init();
// 在 Core 0 启动语音识别
xTaskCreatePinnedToCore(
voiceTaskCore0,
"VoiceTask",
1024 * 32, // 栈大小(推理需要大栈)
NULL, 1, NULL,
0 // Core 0
);
// 自动播放第一首
audio_player_play(0);
}
主循环loop()运行在Core 1上,依次执行四项任务:
- 处理语音命令:从队列中取出语音识别发送的命令并执行
- 处理串口命令:解析用户通过串口发送的单字符控制指令
- MP3解码:持续调用
audio_player_loop()推进MP3帧解码 - 定时刷新OLED:每500ms更新一次显示内容
void loop() {
handleVoiceCommands(); // 1. 处理语音命令
handleSerialCommand(); // 2. 处理串口命令
audio_player_loop(); // 3. MP3 解码
// 4. 定时刷新 OLED
static uint32_t lastDisplay = 0;
if (millis() - lastDisplay > 500) {
lastDisplay = millis();
display_update(audio_player_get_state());
}
}
命令系统采用统一的枚举类型player_cmd_t,无论是语音指令还是串口输入,最终都通过executeCommand()函数统一执行:
void executeCommand(player_cmd_t cmd) {
switch (cmd) {
case CMD_PLAY_PAUSE: audio_player_toggle_pause(); break;
case CMD_STOP: audio_player_stop(); break;
case CMD_NEXT: audio_player_next(); break;
case CMD_PREV: audio_player_prev(); break;
case CMD_VOL_UP: audio_player_volume_up(); break;
case CMD_VOL_DOWN: audio_player_volume_down(); break;
default: break;
}
display_update(audio_player_get_state());
}
二、音频播放器模块 (audio_player.cpp)
音频播放器模块负责SD卡上MP3文件的管理与解码播放,核心设计要点如下:
1. 硬件引脚配置
I2S DAC引脚经过精心选择,避免与SPI(SD卡)和I2C(OLED)产生冲突:
#define I2S_BCLK D0 // GPIO1
#define I2S_LRC D1 // GPIO2
#define I2S_DOUT D3 // GPIO4
#define SD_CS 21 // GPIO21
2. 初始化流程
初始化过程依次完成互斥锁创建、SD卡挂载、MP3文件扫描和I2S输出配置:
bool audio_player_init() {
playerMutex = xSemaphoreCreateMutex();
SD.begin(SD_CS);
scanMP3Files(); // 扫描根目录下所有.mp3文件
out = new AudioOutputI2S();
out->SetPinout(I2S_BCLK, I2S_LRC, I2S_DOUT);
out->SetGain(currentGain); // 默认75%音量
mp3 = new AudioGeneratorMP3();
return true;
}
scanMP3Files()函数遍历SD卡根目录,将所有.mp3文件路径存入数组,最多支持50个文件。
3. 播放控制
播放指定文件:停止当前播放,打开新文件并记录文件大小(用于计算播放进度),启动MP3解码器。
void audio_player_play(int index) {
xSemaphoreTake(playerMutex, portMAX_DELAY);
if (mp3 && mp3->isRunning()) mp3->stop();
if (file) { delete file; file = NULL; }
currentFile = index;
// 获取文件大小用于进度计算
File f = SD.open(mp3Files[index].c_str());
if (f) { fileSize = f.size(); f.close(); }
file = new AudioFileSourceSD(mp3Files[index].c_str());
mp3->begin(file, out);
isPlaying = true;
xSemaphoreGive(playerMutex);
}
暂停/恢复:暂停时记录当前文件读取位置,恢复时通过seek()定位到暂停点继续播放。如果恢复失败,会尝试向前回退2048字节重新寻找MP3帧头,确保续播的可靠性。
void audio_player_toggle_pause() {
// ...
if (isPaused) {
if (file) pausedPosition = file->getPos();
mp3->stop();
} else {
file = new AudioFileSourceSD(mp3Files[currentFile].c_str());
file->seek(pausedPosition, SEEK_SET);
bool started = mp3->begin(file, out);
if (!started) {
// 回退找帧头
uint32_t retryPos = (pausedPosition > 2048) ?
(pausedPosition - 2048) : 0;
// ...重试逻辑
}
}
}
音量控制:采用浮点增益值(0.0~1.0),步进25%,通过AudioOutputI2S::SetGain()实时调节输出增益。
void audio_player_volume_up() {
xSemaphoreTake(playerMutex, portMAX_DELAY);
currentGain += GAIN_STEP; // GAIN_STEP = 0.25f
if (currentGain > GAIN_MAX) currentGain = GAIN_MAX;
out->SetGain(currentGain);
xSemaphoreGive(playerMutex);
}
4. 线程安全
所有播放器操作均通过playerMutex互斥锁保护,确保Core 0的语音命令与Core 1的播放循环不会产生数据竞争。
5. 播放状态查询
audio_player_get_state()函数返回完整的播放器状态结构体,供OLED显示模块使用:
typedef struct {
bool isPlaying;
bool isPaused;
int currentFile;
int fileCount;
int progressPercent; // 基于文件位置/文件大小计算
int volumePercent; // currentGain * 100
char fileName[32];
} player_state_t;
三、语音识别模块 (voice_control.cpp)
语音识别模块是本项目的核心创新点,运行在Core 0上,包含两个关键子系统:PDM音频采集和Edge Impulse神经网络推理。
1. 滑动窗口采集机制
传统的固定窗口采集方式存在严重的"时机依赖"问题——如果语音指令恰好跨越两个采集窗口的边界,两个窗口都无法捕获完整的指令,导致识别率仅有20-30%。
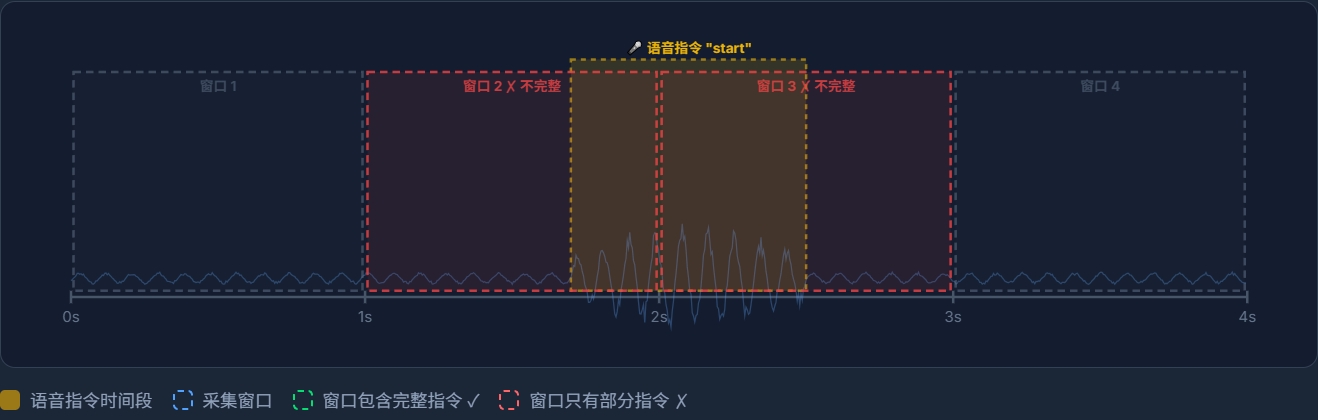
本项目采用滑动窗口 + 环形缓冲区 + 快照复制的三重优化方案:
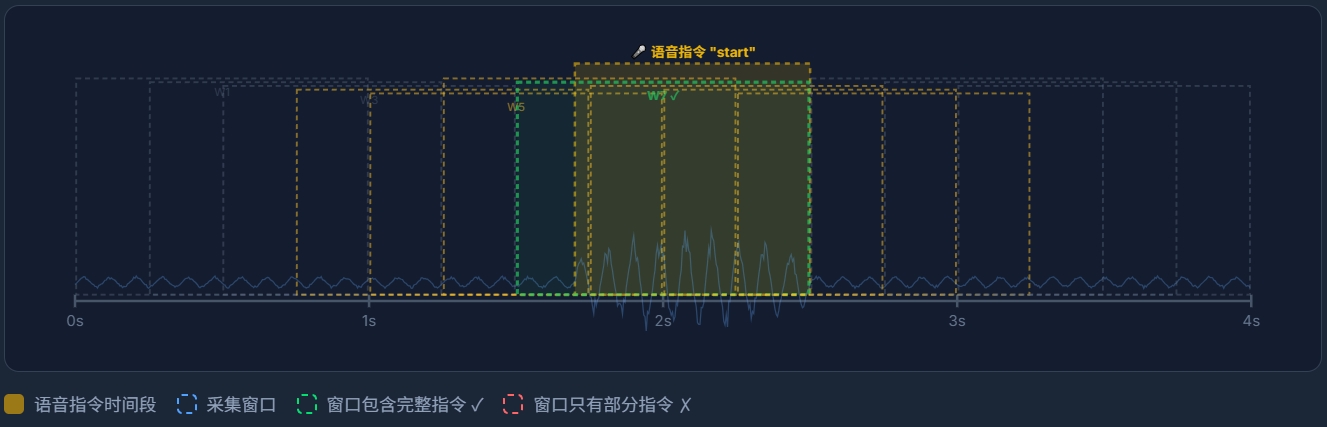
具体实现中,采集任务持续从PDM麦克风读取音频数据,写入环形缓冲区。每当新采集的样本数达到slice_size(窗口大小的1/6)时,将环形缓冲区的当前内容快照复制到独立的推理缓冲区,触发一次推理:
static void voice_capture_task(void *arg) {
while (voice_record_status) {
size_t bytes_read = VoiceI2S.readBytes(
(char*)voiceSampleBuffer, i2s_read_size);
int samples_read = bytes_read / 2;
// 饱和增益放大(8倍)
for (int i = 0; i < samples_read; i++) {
voiceSampleBuffer[i] = saturate_amplify(voiceSampleBuffer[i], 8);
}
// 写入环形缓冲区 + 滑动窗口触发
for (int i = 0; i < samples_read; i++) {
ring_buffer[ring_buf_ix] = voiceSampleBuffer[i];
ring_buf_ix = (ring_buf_ix + 1) % n_samples;
slice_counter++;
if (slice_counter >= slice_size && !inference_ready) {
slice_counter = 0;
// 快照复制:环形缓冲区 → 推理缓冲区
uint32_t copy_ix = ring_buf_ix;
for (uint32_t j = 0; j < n_samples; j++) {
inference_buffer[j] = ring_buffer[copy_ix];
copy_ix = (copy_ix + 1) % n_samples;
}
inference_ready = true;
}
}
}
}
这种设计使得采集窗口之间有约83%的重叠(SLICE_DIVISOR=6),无论语音指令在何时出现,都能被至少一个窗口完整捕获,识别率从20-30%提升至85-95%。
2. 推理与命令映射
推理循环等待采集任务设置inference_ready标志后,构建信号对象并调用Edge Impulse的run_classifier()函数执行神经网络推理:
void voice_control_loop() {
while (!inference_ready) {
vTaskDelay(pdMS_TO_TICKS(5));
}
inference_ready = false;
signal_t signal;
signal.total_length = n_samples;
signal.get_data = &voice_get_signal_data;
ei_impulse_result_t result = { 0 };
run_classifier(&signal, &result, false);
// 找出最高置信度的分类结果
// ...
}
语音标签到播放器命令的映射关系:
语音标签 | 播放器命令 | 功能说明 |
|---|---|---|
"start" |
| 开始播放/恢复 |
"pause" |
| 暂停播放 |
"next" |
| 切换到下一首曲目 |
3. 防重复触发机制
由于滑动窗口的高重叠率,一次语音指令可能在多个连续窗口中被识别到,导致同一指令被重复执行。为此,系统实现了三重防御方案:
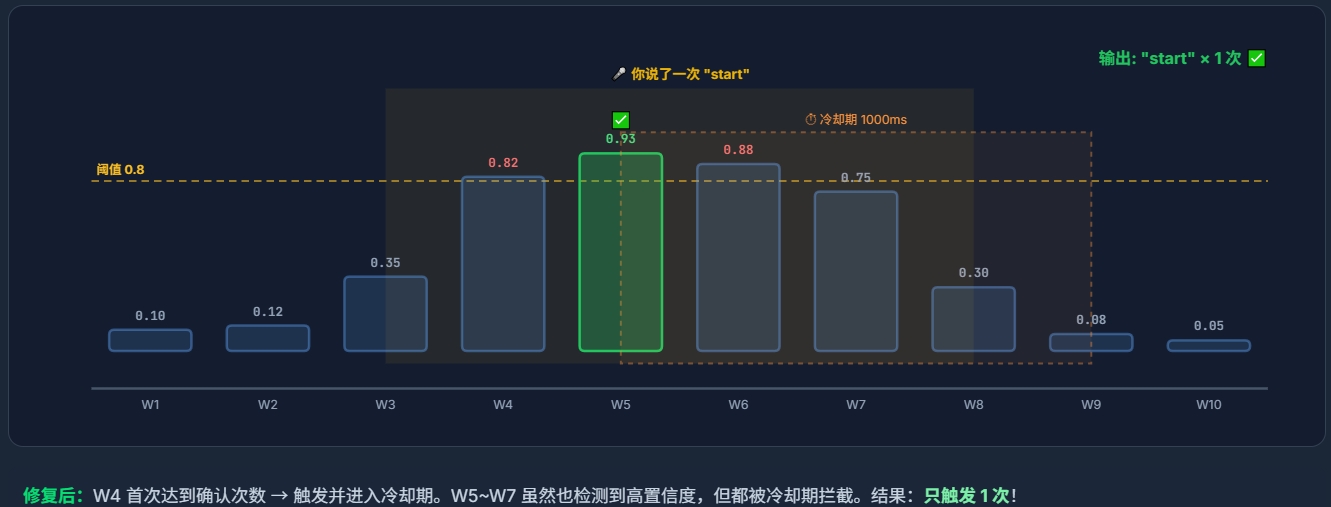
第一重:置信度阈值过滤
只有当分类结果的置信度超过0.8时才视为有效指令,过滤掉低置信度的模糊识别结果:
#define CONFIDENCE_THRESHOLD 0.8f
if (is_command && pred_value > CONFIDENCE_THRESHOLD) {
// 进入后续确认流程
}
第二重:连续确认(Debounce)
要求连续CONFIRM_COUNT次(默认1次)窗口检测到相同指令才触发执行,过滤单帧噪声误检:
if (pred_index == last_pred_index) {
consecutive_count++;
} else {
consecutive_count = 1;
last_pred_index = pred_index;
}
第三重:冷却期(Cooldown)
成功触发一次指令后,在COOLDOWN_MS(1500ms)内忽略同类指令,确保一句话只输出一次结果:
#define COOLDOWN_MS 1500
if (now - last_trigger_time > COOLDOWN_MS) {
sendCommand(cmd, pred_label, pred_value);
last_trigger_time = now;
} else {
Serial.printf("[Voice] [cooldown] %s suppressed\n", pred_label);
}
四、OLED显示模块 (display.cpp)
显示模块使用U8g2库驱动128x64 SSD1306 OLED屏幕,通过默认I2C接口(D4=SDA,D5=SCL)通信。屏幕内容分为四行信息:
void display_update(player_state_t state) {
u8g2.clearBuffer();
u8g2.setFont(u8g2_font_ncenB08_tr);
// 第一行:标题 + 播放状态([PLAY]/[PAUSE]/[STOP])
u8g2.drawStr(0, 12, "MP3 Player");
// 第二行:当前文件名
u8g2.drawStr(0, 28, state.fileName);
// 第三行:进度条 + 百分比
int fillW = 100 * state.progressPercent / 100;
u8g2.drawFrame(0, 34, 100, 10); // 进度条外框
u8g2.drawBox(1, 35, fillW - 1, 8); // 进度条填充
// 第四行:曲目编号(Track x/y)+ 音量(Vol:xx%)
snprintf(info, sizeof(info), "Track %d/%d",
state.currentFile + 1, state.fileCount);
snprintf(volStr, sizeof(volStr), "Vol:%d%%", state.volumePercent);
u8g2.sendBuffer();
}
OLED显示的具体信息包括:
- 曲目编号:显示"Track x/y"格式,x为当前曲目序号,y为总曲目数
- 播放进度百分比:通过文件当前读取位置与文件总大小的比值计算,同时以图形进度条直观展示
- 当前音量:显示"Vol:xx%"格式,范围0%-100%
效果展示

系统上电后自动扫描SD卡中的MP3文件并开始播放第一首曲目。OLED屏幕实时显示播放器状态,用户可以通过语音指令或串口命令控制播放。
串口支持的完整命令集:
按键 | 功能 | 按键 | 功能 |
|---|---|---|---|
p | 播放/暂停 | s | 停止 |
n | 下一曲 | b | 上一曲 |
+ | 音量增加(+25%) | - | 音量降低 |
l | 列出文件 | h | 帮助 |
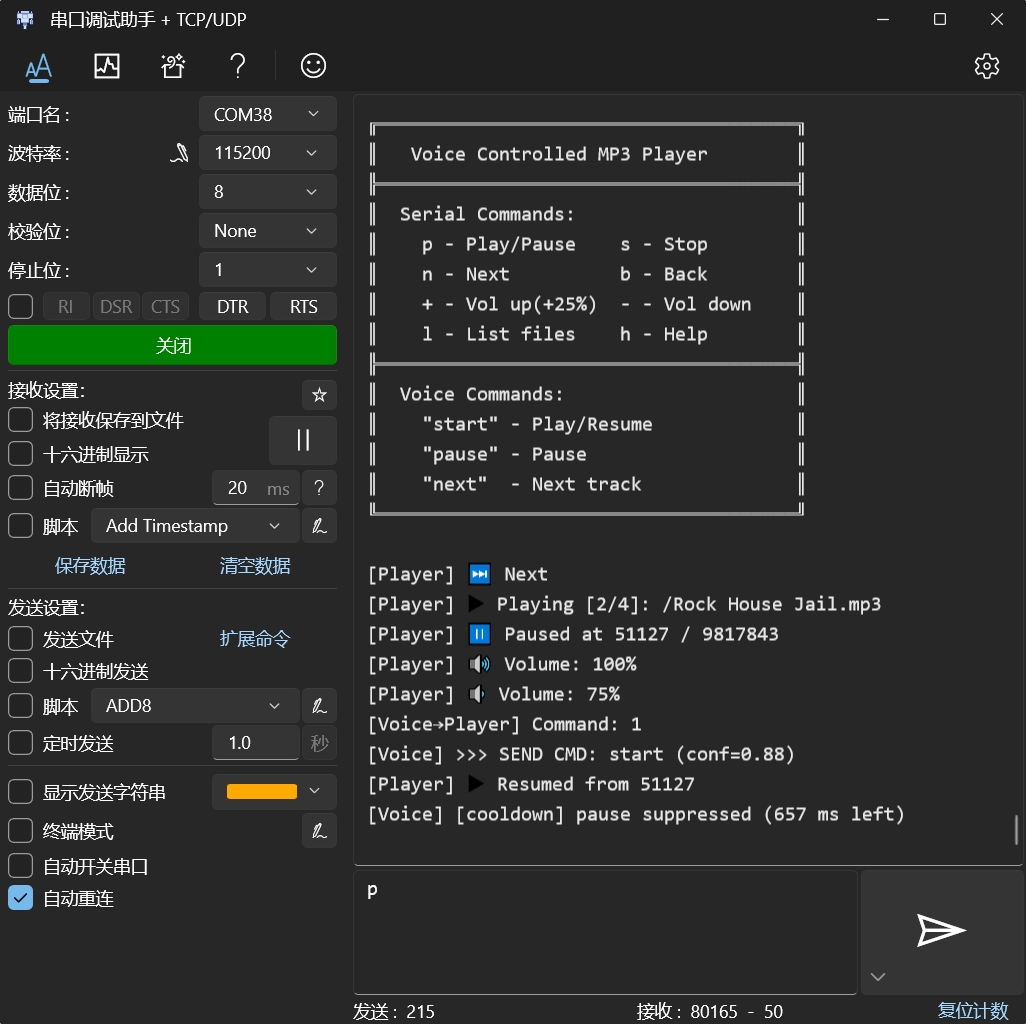
语音指令支持的操作:
关键词 | 功能 |
|---|---|
"播放" | 开始播放/恢复 |
"暂停" | 暂停播放 |
"下一首" | 切换下一首曲目 |
遇到的难题与解决办法
问题一:语音识别率极低,仅约20-30%
解法:分析发现原始方案使用固定窗口采集,语音指令跨窗口边界时无法被完整捕获。改用滑动窗口 + 环形缓冲区 + 快照复制的方案后,识别率提升至85-95%。关键参数为SLICE_DIVISOR=6(约83%重叠),确保任何时刻的语音指令都能被至少一个窗口完整包含。
问题二:识别成功后同一指令被重复执行多次
解法:实现了三重防御机制——置信度阈值(0.8)过滤低置信度结果、连续确认过滤单帧误检、冷却期(1500ms)防止同一指令的多窗口重复触发。
问题三:双核并行导致音频播放器状态被同时访问
解法:为播放器所有操作添加playerMutex互斥锁保护,Core 0的语音命令通过FreeRTOS Queue异步传递给Core 1执行,避免直接跨核访问共享资源。
问题四:MP3暂停后恢复播放时出现解码错误
解法:暂停时记录文件读取位置,恢复时先尝试从记录位置开始解码。如果失败,自动向前回退2048字节重新寻找MP3帧头;如果仍然失败,则从文件开头重新播放作为保底方案。
活动感想
通过本项目实践,深入掌握了ESP32-S3双核架构下FreeRTOS多任务调度的设计方法、Edge Impulse平台从数据采集到模型部署的完整工作流程,以及嵌入式系统中音频采集、解码播放、显示驱动的协同工作机制。XIAO ESP32S3 Sense开发板紧凑的尺寸和丰富的板载传感器极大降低了原型开发的硬件搭建难度。整个开发过程中,体会到嵌入式AI应用需要算法模型与系统工程的紧密配合——不仅需要训练出高准确率的模型,还需要在工程层面解决实时采集、防重复触发、多核同步等一系列实际问题,每一个环节的优化都能显著提升最终的用户体验。
感谢硬禾科技举办的2026寒假练活动,祝硬禾的活动越办越好!

 tinySDR
tinySDR