电子森林音乐盒项目文档
一、 任务要求
- 预置不少于 3 段旋律序列,通过扬声器或蜂鸣器播放;
- 若使用蜂鸣器,需使用 RGB 灯带按节拍或音符强弱实现律动灯效;
- 麦克风关键词识别实现播放、暂停、下一首、上一首、音量大、音量小等至少 3 条指令,注意指令必须包含切换播放曲目。语音识别可使用EDGE IMPULSE、ESP-SR或上位机等部署相关模型;
- OLED 显示曲目编号、播放进度百分比、当前音量;
- 可选加分:微信小程序或网页远程选曲、查看进度与调整音量;
- 可选加分:自行设计 3D 外壳或音乐盒结构,需提交结构文件与装配说明。
二、 解决方案概要
- 音频播放:使用 Flask 搭建网页后台并准备三首音乐,通过 ESP32 驱动 I2S 扬声器进行网络音频流播放。
- 视觉效果:本项目未采用蜂鸣器,因此未添加 RGB 灯带做律动灯效。
- 语音识别与抗干扰处理:使用 Edge Impulse 训练语音模型。
- 最终方案:综合评估后,决定仍沿用直接的关键词识别方式,并通过加强环境噪音的数据训练来提高模型抗干扰能力。
- 显示与按键控制:OLED 界面基于
u8g2图形库实现;交互控制采用 ADC 模拟按键实现功能操作。 - 远程控制后台:利用 Flask 部署网页后台(支持本地与云服务器),实现远程选曲和音量调节。
三、 任务实现详细过程
3.1 硬件准备与调试
在进行项目开发前,需对所用硬件进行整体测试,以便及时发现并解决潜在的设计问题。
1. ADC 按键模块

- 电压匹配问题:按键模块设计的基准电压为 5V,而 ESP32 的 ADC 基准电压为 3.3V。如果直接接入,分压后的电压会超过 ESP32 的安全量程。

- 硬件修正:将分压电阻 R2 替换为 5.1kΩ 及以下规格的电阻,使最高采样电压降至 3.3V 左右。
- 按键规划:因为按键 1 的分压电阻差值不够精确,且本项目仅需 3 个按键即可完成操作,因此不使用按键 1。
- 信号处理:实测发现基准电压存在毛刺波动,需通过软件采集多组数据并进行中值滤波以获取稳定的 ADC 值。
- 各按键触发阈值定义如下:
// [按键2] 音量+ (700-900)
#define BTN_RANGE_2_MIN 700
#define BTN_RANGE_2_MAX 900
// [按键3] 音量- (920-1200)
#define BTN_RANGE_3_MIN 920
#define BTN_RANGE_3_MAX 1200
// [按键4] 播放/暂停 (1600-2100)
#define BTN_RANGE_4_MIN 1600
#define BTN_RANGE_4_MAX 2100
2. 其余器件
所需核心器件包含:OLED 屏幕、MAX98357A 音频解码器、ESP32 核心板、SD 卡一张,以及为了保证音量效果替换的大功率喇叭。各模块经测试均可正常工作。

3.2 软件开发环境
- 开发平台:Arduino IDE、Python
- ESP32 版本:3.3.6
- 后端框架:Flask
- 模型训练平台:Edge Impulse
3.3 模型训练过程
参考相关教程完成模型训练:
- 根据 Arduino IDE 中安装的 ESP32 版本,选择对应的 3.x 教程进行 SD 卡识别训练。

- 录制并上传四个关键词的语音数据集。

- 训练完成后,导出包含模型的
.zip库文件,并将其导入 Arduino 库中调用即可。


3.4 OLED 界面开发
系统使用 u8g2 库并开启 UTF-8 支持来绘制包含中文字符的播放器界面。
- 上电状态:初始化时屏幕显示“正在连接 WiFi...”。

- 音乐播放状态 UI 布局:

- 左上角:显示当前播放状态(播放/暂停)。
- 右上角:显示当前曲目序号及云端歌单总数。
- 居中部分:显示当前正在播放的歌曲名称。
- 中下部分:根据歌曲总时长与当前播放时间,绘制进度百分比条及时间文本。
- 最底部:以图形化条状图实时反馈当前的音量大小。
3.5 ADC 按键处理逻辑
系统配置了三个功能按键:音量+、音量-、暂停/播放。
软件层面,每次按键扫描连续采集 5 次模拟量,经过冒泡排序算法剔除极值取中位数,以确保采集数值的准确性。获取稳定的 ADC 值后,程序判断其所在的阈值区间触发相应事件,并加入了软件防抖逻辑。
- 滤波处理
int getMedianADC() {
int values[5];
for(int i=0; i<5; i++) {
values[i] = analogRead(ADC_PIN);
delay(2);
}
for(int i=0; i<4; i++) {
for(int j=i+1; j<5; j++) {
if(values[i] > values[j]) {
int temp = values[i];
values[i] = values[j];
values[j] = temp;
}
}
}
return values[2];
}
- 具体实现功能
void handleADCButtons() {
int cleanVal = getMedianADC();
int currentID = getKeyID(cleanVal);
if (currentID != lastKeyID) {
stableStartTime = millis();
lastKeyID = currentID;
}
else {
if ((millis() - stableStartTime) > 60) {
if (currentID != KEY_NONE) {
if (!isKeyPressed) {
Serial.printf("Key Action: %d (ADC: %d)\n", currentID, cleanVal);
switch (currentID) {
case KEY_VOL_UP:
if (currentVolume < 21) {
currentVolume++;
audio.setVolume(currentVolume);
drawPlayerInterface();
}
break;
case KEY_VOL_DOWN:
if (currentVolume > 0) {
currentVolume--;
audio.setVolume(currentVolume);
drawPlayerInterface();
}
break;
case KEY_PLAY_PAUSE:
togglePlayPause(); // 使用统一封装的函数
break;
}
isKeyPressed = true;
}
} else {
isKeyPressed = false;
}
}
}
}
- 触发相关阈值
enum KeyID { KEY_NONE, KEY_VOL_UP, KEY_VOL_DOWN, KEY_PLAY_PAUSE };
int lastKeyID = KEY_NONE;
unsigned long stableStartTime = 0;
bool isKeyPressed = false;
int getKeyID(int val) {
if (val < 400 || val > 2200) return KEY_NONE;
if (val >= BTN_RANGE_2_MIN && val <= BTN_RANGE_2_MAX) return KEY_VOL_UP;
if (val >= BTN_RANGE_3_MIN && val <= BTN_RANGE_3_MAX) return KEY_VOL_DOWN;
if (val >= BTN_RANGE_4_MIN && val <= BTN_RANGE_4_MAX) return KEY_PLAY_PAUSE;
return KEY_NONE;
}
3.6 网络通信与ESP32轮询
ESP32 连接 WiFi 后,通过访问部署的 Flask 后端,实现远程指令下发与音乐链接解析。
- 指令轮询:ESP32 每隔 800ms 向服务器发起
GET /api/poll-command。
获取其中的指令:指令通过 json 格式,获取当前的状态
这里服务器主要下发:
1.音乐的 url 和其中音乐名称给 OLED 显示中文名
{"act":"play","filename":"\u6211\u7231\u4f60.mp3","index":1,"total":4,"url":"你的音乐网址"}
2.下发音量大小,根据音量大小来调节 ESP32 端播放的音乐声音
{"act":"volume","val":"72"}
3.发送暂停和播放的指令
{"act":"pause"}
其中 800ms 轮询一次,服务器可以知道消息是否被获取,可以知道当前设备是否
if (millis() - lastCheckTime > checkInterval) {
checkCommand();
lastCheckTime = millis();
}
- 指令执行:解析服务器返回的 JSON,执行播放(
play)、音量(volume)、暂停/恢复(pause/resume)等操作。
- 逻辑处理代码
void checkCommand() {
if(WiFi.status() != WL_CONNECTED) return;
HTTPClient http;
http.begin(serverHost + "/api/poll-command");
http.setTimeout(300);
if (http.GET() == 200) {
DynamicJsonDocument doc(2048);
if (!deserializeJson(doc, http.getString())) {
String action = doc["act"].as<String>();
if (doc.containsKey("index")) currentSongIndex = doc["index"];
if (doc.containsKey("total")) totalSongs = doc["total"];
if (action == "play") {
String newUrl = doc["url"].as<String>();
if (doc.containsKey("filename")) {
String fname = doc["filename"].as<String>();
fname.replace(".mp3", "");
currentTitle = fname;
}
if (streamUrl != newUrl || !audio.isRunning()) {
streamUrl = newUrl;
audio.connecttohost(newUrl.c_str());
currentStatusRaw = "Buffering";
isManualPause = false;
drawPlayerInterface();
} else if (isManualPause) {
audio.pauseResume();
isManualPause = false;
currentStatusRaw = "Playing";
drawPlayerInterface();
}
}
else if (action == "pause") {
if(audio.isRunning() && !isManualPause) {
audio.pauseResume();
isManualPause = true;
currentStatusRaw = "Paused";
drawPlayerInterface();
}
}
else if (action == "resume") {
if (isManualPause || !audio.isRunning()) {
audio.pauseResume();
isManualPause = false;
currentStatusRaw = "Playing";
drawPlayerInterface();
}
}
else if (action == "volume") {
int webVol = doc["val"];
currentVolume = map(webVol, 0, 100, 0, 21);
audio.setVolume(currentVolume);
drawPlayerInterface();
}
}
}
http.end();
}
3.7 网页后端与云端逻辑 (Flask)
本项目利用 Python 的 Flask 框架搭建了轻量级的 Web 控制端,它主要承担了 UI 渲染、文件管理、以及作为 Web 端与 ESP32 硬件之间的“命令中枢”。以下是其核心逻辑拆解:
1. UI 渲染与静态资源托管
服务器直接渲染内嵌的 HTML 模板(包含前端极光 UI 及交互逻辑),并将 music 文件夹下的音乐文件暴露为静态资源,供前端本地试听直接调用。
# 渲染前端控制台页面,并传入歌曲列表
@app.route('/')
def index():
return render_template_string(HTML_TEMPLATE, songs=get_song_list())
# 暴露本地音乐文件,供前端 "本机试听" 模式播放
@app.route('/music/<path:filename>')
def serve_file_raw(filename):
return send_from_directory(MUSIC_FOLDER, filename)
2. 文件上传与管理
为了方便用户随时更新歌单,后端提供了上传和删除接口,并在上传时进行了安全拦截(限制文件大小为 10MB 及仅限 MP3 格式)。
@app.route('/api/upload', methods=['POST'])
def upload():
f = request.files.get('file')
if f and f.filename:
# 获取文件大小
f.seek(0, os.SEEK_END)
file_size = f.tell()
f.seek(0)
# 安全与格式校验
if file_size > MAX_FILE_SIZE:
return jsonify(success=False, msg="上传失败:文件大小超过 10MB")
if not f.filename.lower().endswith('.mp3'):
return jsonify(success=False, msg="仅支持 MP3 格式文件")
# 保存文件
f.save(os.path.join(MUSIC_FOLDER, f.filename))
return jsonify(success=True)
3. 指令中转与设备心跳机制
由于 Web 无法主动向处于局域网或内网的 ESP32 推送数据,后端采用了一个 esp_command_queue 列表作为指令缓冲池。ESP32 轮询拿走指令的同时,后端会记录当前时间戳,以此来判定设备是否在线。
esp_command_queue = []
last_esp_active_time = 0
# ESP32 硬件请求此接口获取指令
@app.route('/api/poll-command')
def poll():
global last_esp_active_time
last_esp_active_time = time.time() # 刷新设备活跃时间(心跳)
# 队列有指令则弹出下发,否则返回空动作
if esp_command_queue:
return jsonify(esp_command_queue.pop(0))
return jsonify({'act': 'none'})
# 供前端页面查询设备是否在线 (超时5秒判定为离线)
@app.route('/api/esp-status')
def status():
return jsonify(online=(time.time() - last_esp_active_time) < 5)
4. 播放控制与音频流安全分发
当用户在网页端点歌时,后端不会直接下发原文件名给 ESP32。由于文件名可能包含中文或空格,容易导致 ESP32 URL 解析失败。后端巧妙地将文件名进行了 Base64 编码,生成安全的串流 URL 下发,并在 ESP32 请求该 URL 时解码并返回音频流。同时,后端还动态计算当前歌曲的序号和总数供 OLED 显示。
@app.route('/api/send-command', methods=['POST'])
def receive_command():
cmd = request.json
if cmd.get('act') == 'play':
fname = cmd.get('filename')
# 将文件名进行 Base64 编码,生成安全的音频流 URL
b64 = base64.urlsafe_b64encode(fname.encode()).decode()
safe_url = f"{request.host_url}api/stream/{b64}"
cmd['url'] = safe_url
# 动态计算当前曲目在歌单中的 Index (1-based) 和 Total
songs = get_song_list()
cmd['total'] = len(songs)
cmd['index'] = songs.index(fname) + 1 if fname in songs else 1
esp_command_queue.append(cmd)
return jsonify(success=True)
# ESP32 请求播放音频流时触发解码并发送文件
@app.route('/api/stream/<b64_name>')
def stream_music_b64(b64_name):
try:
fname = base64.urlsafe_b64decode(b64_name).decode()
return send_from_directory(MUSIC_FOLDER, fname)
except:
return "Error", 404
5.Flask项目路径
D:\
├── app.py <-- 你的 Python 代码
└── music\ <-- 新建这个文件夹!
├── 晴天.mp3 <-- 放入歌曲
└──test.mp3
6.如何部署
由于我的环境问题,我当前是部署到腾讯云的服务器上,感兴趣的小伙伴,可以在网上查找资料,如购买域名,部署轻量级服务器,还有端口的开放。在家庭中使用可以使用内网来部署,更安全可靠,直接使用本地电脑当作服务器的后台。系统架构是flask,直接python环境配置好,将相关包配置好就能成功实现。
7.网页端UI
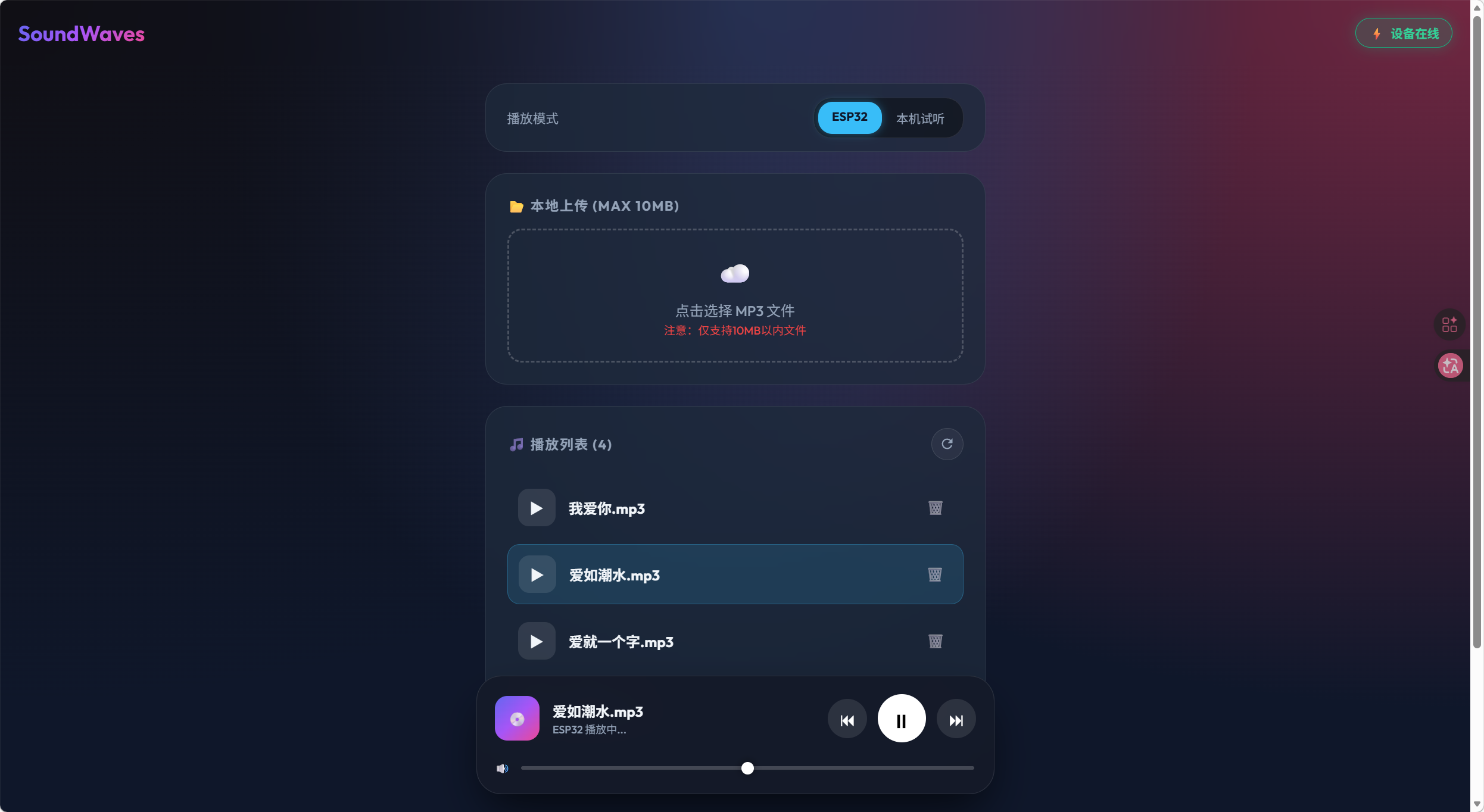
3.8 系统软件交互流程图
本项目采用了“前端 UI <-> 云端中枢 <-> 硬件终端”的三层架构,通过 HTTP 协议进行异步指令通信与音频流传输。
1. 系统架构与数据流向图
该图展示了三个核心模块之间是如何通过 API 接口进行数据交互和相互协同的。

2. 核心控制时序图 (播放与轮询机制)
由于 Web 无法主动向处于局域网内的 ESP32 推送数据,系统采用了硬件轮询 (Polling) 机制。下图展示了从用户在网页点击“下一首”到硬件发出声音的完整时间线。

3.9 语音识别与离线指令控制
本项目引入了基于 Edge Impulse 训练的轻量级关键词唤醒(KWS)模型,通过 I2S PDM 数字麦克风实时侦听环境声音,实现免接触的切歌与播放控制(如“last”、“next”、“stop”)。为了在资源受限的 ESP32 上既保证音频流媒体的平滑播放,又实现高频的 AI 采样,系统在架构与算法上做了深度优化。
1. 软硬分工与双核并行架构 ESP32 包含两个独立的处理器核心。在常规单核运行模式下,密集的 AI 矩阵运算极易导致主循环中的 MP3 音频解码任务(audio.loop())被“饿死”,从而产生音乐卡顿现象。 为了解决这一问题,本项目采用了 FreeRTOS 多任务机制 进行严格的核分离:
- Core 1(主处理核): 负责运行
loop()主循环,处理 Wi-Fi 通信、JSON 解析、OLED 屏幕刷新以及繁重的 I2S 音乐数据解码输出。 - Core 0(后台处理核): 通过
xTaskCreatePinnedToCore将 AI 推理任务(kws_inference_task)和麦克风采样任务锁定在 Core 0 上独立运行,互不干扰。
2. 音频采集与滑动窗口算法 语音指令的出现时间是随机的,为了防止指令正好落在两次采样周期的交界处而被漏听,系统引入了环形缓冲区(Ring Buffer)与滑动窗口(Sliding Window)机制。
- 软件增益: 由于原始麦克风采集的声音幅值较小,程序在底层读取数据时,直接将采样值放大了 8 倍,并加入了硬限幅防爆音处理。
- 连续切片: 预留 1 秒钟的声音缓冲区(共 2048 个采样点),并将其均匀切分为 4 份。麦克风每填满 1/4 秒(约 250ms)的数据,就通知 AI 唤醒一次,去“听”过去 1 秒内的完整声音快照。
3. 智能防误触与动态置信度 在实际运行中,扬声器播放的音乐很容易被麦克风重新采集,导致“自己播放的歌声触发了自己的切歌指令”(即回声误唤醒)。为此,程序在模型推理(run_classifier)后,加入了智能防误触逻辑:
- 动态门槛: 默认状态下,模型预测某项指令的概率置信度超过 0.75 (75%) 即认为触发成功。但当机器处于“播放中”状态(
currentStatusRaw == "Playing")时,系统会自动将门槛拉高至 0.88 (88%),以此过滤掉大部分环境杂音与背景音乐的干扰。 - 强制冷却期(Cooldown): 由于滑动窗口每秒触发 4 次推理,用户喊出一句指令可能会被连续识别多次。代码中设置了
1500ms的强制冷却时间,确保一次语音指令只会被执行一次动作。
核心代码实现逻辑:
C++
// AI 推理任务 (运行在 Core 0)
void kws_inference_task(void *pvParameters) {
unsigned long last_trigger_time = 0; // 记录上次成功触发动作的时间
const unsigned long COOLDOWN_MS = 1500; // 冷却期 1.5 秒
while (1) {
if (!slice_ready) {
vTaskDelay(10 / portTICK_PERIOD_MS);
continue;
}
// 运行模型推理
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, false);
if (r == EI_IMPULSE_OK) {
int best_idx = -1;
// 动态置信度门槛:播放时提高门槛防环境音干扰
float best_score = (currentStatusRaw == "Playing") ? 0.88 : 0.75;
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
if (result.classification[ix].value > best_score) {
best_score = result.classification[ix].value;
best_idx = ix;
}
}
if (best_idx != -1) {
const char* label = result.classification[best_idx].label;
// 排除静音与噪音,且检查是否度过 1500ms 冷却期
if (strcmp(label, "noise") != 0 && strcmp(label, "zero") != 0) {
if (millis() - last_trigger_time > COOLDOWN_MS) {
// 派发指令标志位给主循环
if (strcmp(label, "last") == 0) voiceCommandFlag = 1;
else if (strcmp(label, "next") == 0) voiceCommandFlag = 2;
else if (strcmp(label, "pause") == 0) voiceCommandFlag = 3;
last_trigger_time = millis(); // 进入冷却期
}
}
}
}
}
}
当 voiceCommandFlag 被置位后,Core 1 的主循环会立即捕捉到该标志,并调用对应的切歌或暂停函数,完成最终的设备控制。
总结
此次难点还是在语音识别,尽可能保持识别效果,但是还是多多少少还会有点误判。


