- 所选任务介绍
- 项目介绍

本次我使用了XIAO ESP32 Sense主控板(搭载ESP32S3、麦克风、SD卡槽)以及对应的底板(搭载SD卡),外加MAX98357和扬声器,实现语音点歌音乐盒:说出上一曲或下一曲时,mp3播放器会自动切换。
本次没有使用原版小车底座,主要是因为MAX98357和SD卡引脚有冲突,同时换成了自备的8Ω 0.5W扬声器,以提升音质效果。
使用开发工具为Arduino IDE,主要软件为Edge Impulse模型训练及部署平台,ESP32-audioI2S-master mp3播放库,以及U8g2 OLED驱动库。
- 简短的所有使用到的硬件介绍
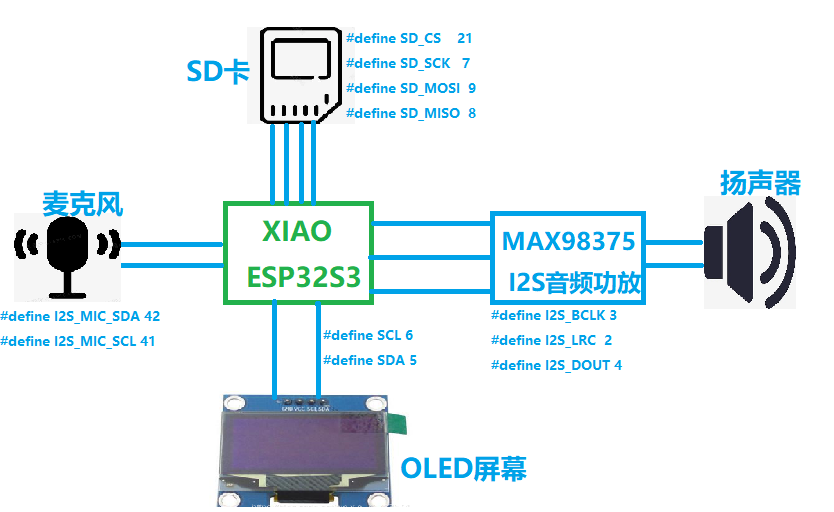
主要使用了麦克风、SD卡、OLED屏幕、I2S音频功放、扬声器,对应的引脚已在图中标示出。
- 方案框图和项目设计思路介绍
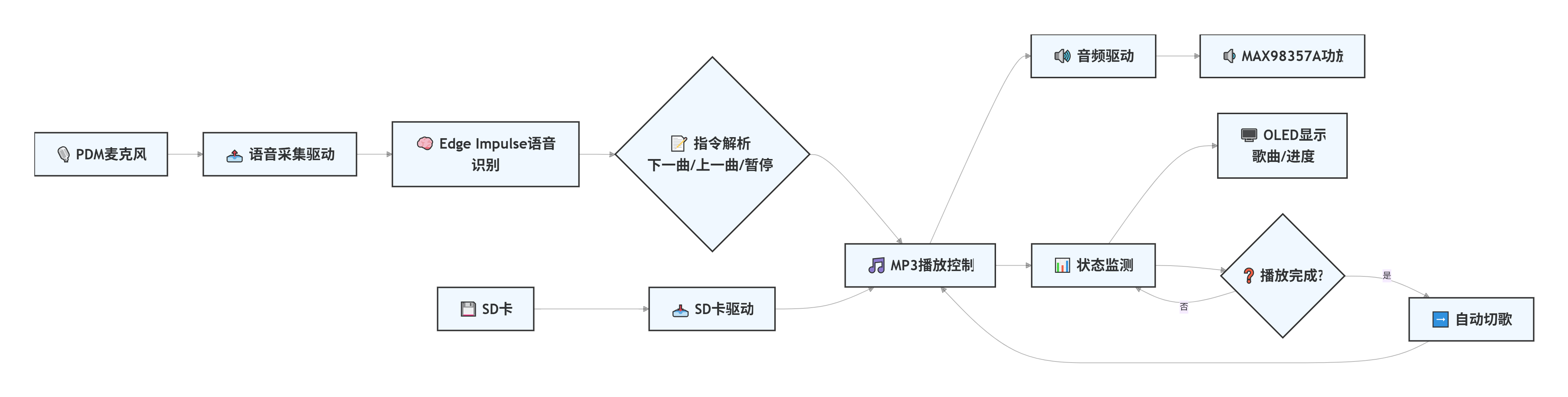
设计思路主要围绕2条主线
主线1:mp3播放及显示,使用了ESP32-audioI2S-master mp3播放库,以及U8g2 OLED驱动库。
为此前期专门编写了mp3播放程序及OLED显示程序。
主线2:语音识别及控制切歌,使用了Edge Impulse模型训练及部署平台。
具体方法参考了seeed官网中的方法。
- 调试软件及使用的编程语言说明、软件流程图及关键代码介绍
调试软件及使用的编程语言:Arduino IDE
所需ESP32开发板软件版本
ESP32 3.3.7(这个版本对各类库的兼容性最好)
所需arduino库
ESP32-audioI2S-master 3.4.4(播放SD卡中mp3)
U8g2 2.35.30(驱动OLED中英文显示)
软件流程图:
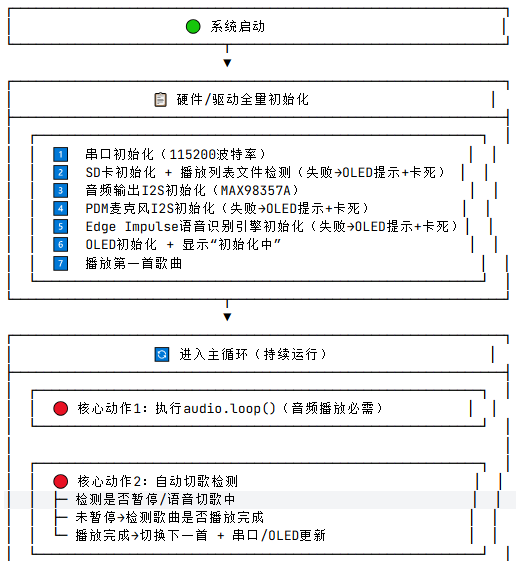
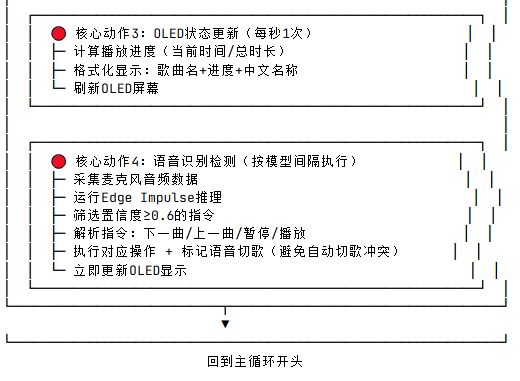
关键代码介绍
首先是edge impulse的素材采集、模型训练及部署,这部分参考了seeed官方的例程,详见:
https://wiki.seeedstudio.com/cn/tinyml_course_Key_Word_Spotting/
为了训练模型,建立了许多个edge impulse项目:
这里需要重点说明下:
在将素材分割成1s一个的语音片段时。
默认的自动切歌如图:
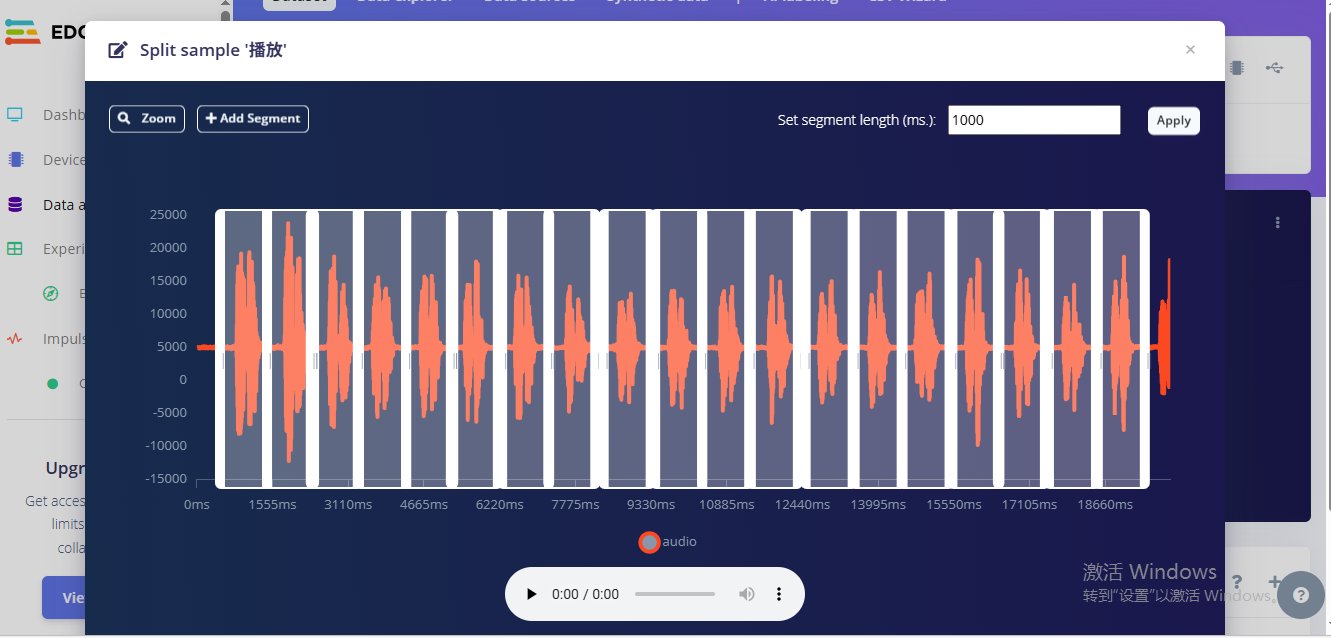
看起来非常工整,但经过多次测试,这种的识别率非常糟糕。
原因在于说话的时机,因为麦克风在采集时,你不一定是按上图所示去说话,也就是说不可能他在采集时,刚好过了一小会(比如200ms)你刚好开始说话,一旦不是这种就无法识别。
解决方案,在模型采集阶段,考虑各类说话时机:
1)刚开始采集就说话
2)采集开始约200ms开始说话(关键词刚好落在正中间,如上图)
3) 采集开始约500ms开始说话,采集结束,关键词也结束
优化后的切割方式如下图
大概5~6个方格,一上来就说话(语音在方格最左边)
大概5~6个方格,等片刻(约200ms)才说话(语音在方格最中间)
大概5~6个方格,刚结束就说完(语音在方格最右边)
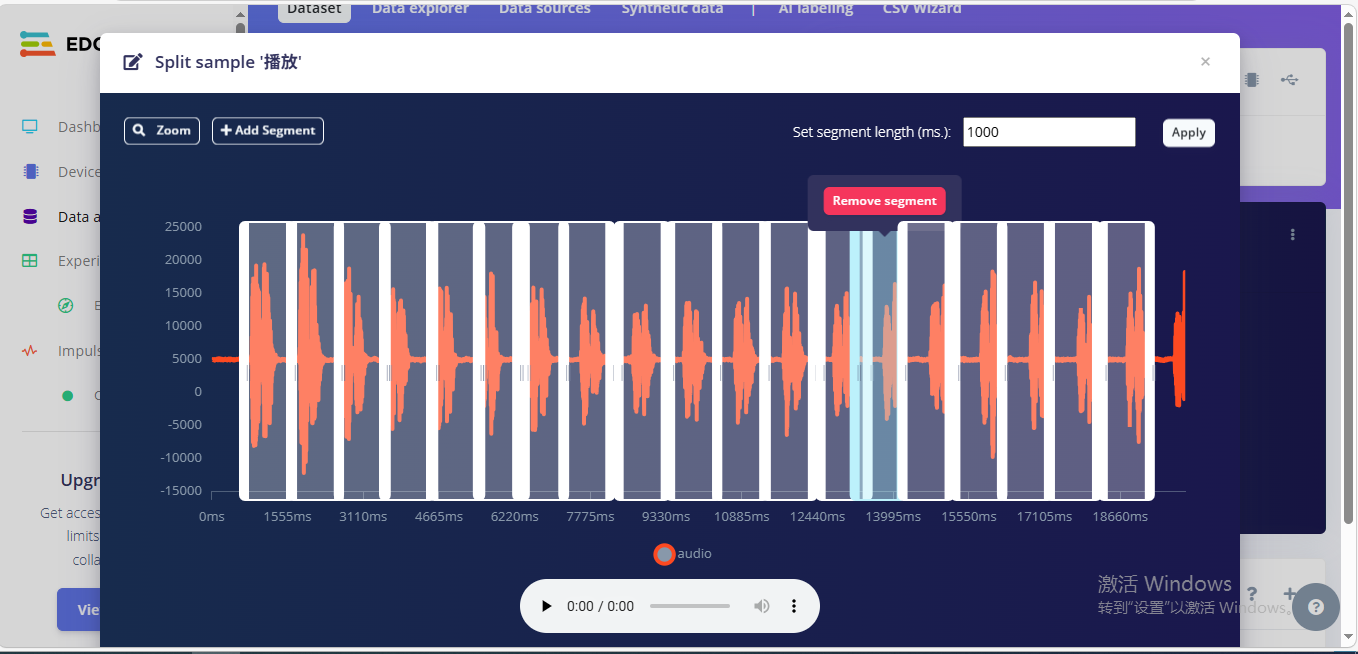
这样训练出来的程序,识别率会高一些。
mp3关键代码(纯播放mp3,不语音识别,不显示在OLED,可由串口控制切歌):
使用MAX98357模块,接线图如下:
电源3.3V,SD和GAIN可以悬空不接(实测可行)。
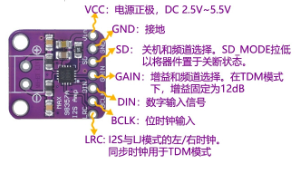
注意要安装ESP32-audioI2S-master 3.4.4库,ESP32是 3.3.7版本。
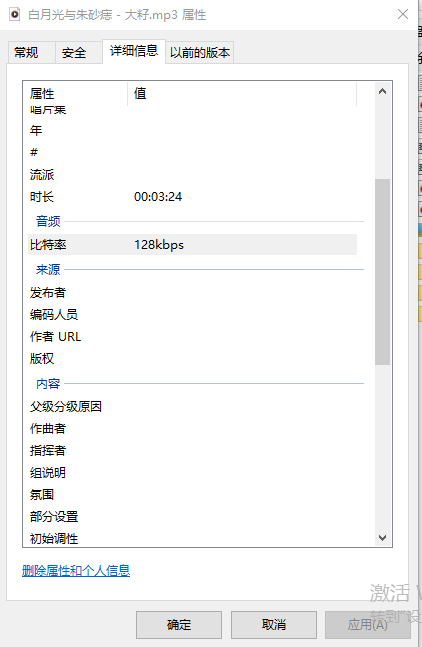
另外,mp3必须是128kbps,文件名不能是中文。
#include <Arduino.h>
#include <SPI.h>
#include <SD.h>
#include <Audio.h>
// ------------------- 引脚定义 -------------------
// SD卡引脚(自定义SPI)
#define SD_CS 21
#define SD_SCK 7
#define SD_MOSI 9
#define SD_MISO 8
// MAX98357A I2S引脚
#define I2S_LRC 2
#define I2S_BCLK 3
#define I2S_DOUT 4
// ------------------- 播放控制枚举(预留控制参数) -------------------
enum PlayControl {
PLAY, // 播放
PAUSE, // 暂停
PREV, // 上一曲
NEXT // 下一曲
};
// ------------------- 音频对象 -------------------
Audio audio;
// ------------------- 自定义SPI初始化 -------------------
SPIClass sd_spi(FSPI); // 使用FSPI总线(ESP32-S3的SPI2)
// ------------------- 新增:播放列表与索引 -------------------
const char* playList[] = {"/music1.mp3", "/music2.mp3", "/music3.mp3"}; // 顺序播放列表
int currentIndex = 0; // 当前播放歌曲的索引,从0开始
int totalSongs = sizeof(playList) / sizeof(playList[0]); // 自动计算歌曲总数,便于后续扩展
// ------------------- 函数声明:播放指定索引的歌曲 -------------------
void playSong(int index);
void controlPlay(PlayControl cmd);
// ------------------- 核心控制函数 -------------------
// 执行播放控制指令
void controlPlay(PlayControl cmd) {
switch(cmd) {
case PREV:
Serial.println("⏮️ 上一曲");
currentIndex = (currentIndex - 1 + 3) % 3; // 循环索引
playSong(currentIndex);
break;
case NEXT:
Serial.println("⏭️ 下一曲");
currentIndex = (currentIndex + 1) % 3; // 循环索引
playSong(currentIndex);
break;
}
}
void setup() {
// 初始化串口(调试用,波特率115200)
Serial.begin(115200);
delay(1000); // 等待串口和硬件稳定
Serial.println("=== ESP32-S3 MP3播放器初始化 ===");
// 1. 初始化自定义SPI总线(SD卡)
sd_spi.begin(SD_SCK, SD_MISO, SD_MOSI, SD_CS); // SCK, MISO, MOSI, CS
Serial.print("📌 初始化SD卡...");
if (!SD.begin(SD_CS, sd_spi)) {
Serial.println("失败!");
Serial.println("请检查:1.SD卡接线 2.SD卡格式(FAT32) 3.卡未损坏");
while (1) delay(1000); // 初始化失败则卡死
}
Serial.println("成功!");
// 新增:检查播放列表中所有歌曲是否存在
Serial.println("📌 检查播放列表所有文件...");
bool allFileExist = true;
for (int i = 0; i < totalSongs; i++) {
Serial.printf(" 检查%s...", playList[i]);
if (!SD.exists(playList[i])) {
Serial.println("不存在!");
allFileExist = false;
} else {
Serial.println("存在!");
}
}
if (!allFileExist) {
Serial.println("❌ 部分文件缺失,请检查SD卡根目录文件!");
while (1) delay(1000);
}
// 2. 配置I2S音频输出(适配MAX98357A)
Serial.print("📌 配置I2S音频...");
audio.setPinout(I2S_BCLK, I2S_LRC, I2S_DOUT); // BCLK, LRC, DOUT
// 设置音量(0-21,10为适中,避免破音)
audio.setVolume(21);
Serial.println("完成!");
// 3. 开始播放第一首歌
Serial.printf("📌 开始播放列表第一首:%s...", playList[0]);
playSong(currentIndex);
Serial.println("成功!");
}
void loop() {
// 核心音频处理循环(必须持续调用)
audio.loop();
if (Serial.available() > 0) {
char cmd = Serial.read();
switch(cmd) {
case '<': controlPlay(PREV); break;
case '>': controlPlay(NEXT); break;
}
}
// 播放状态打印(每秒一次)
if (audio.isRunning()) {
static unsigned long lastPrint = 0;
if (millis() - lastPrint > 1000) {
// 按字节数估算播放进度(兼容所有库版本)
//File f = SD.open(playList[currentIndex]);
//uint32_t fileSize = f.size();
uint32_t fileSize = audio.getAudioFileDuration();
//f.close();
uint32_t playedBytes = audio.getAudioCurrentTime();
float progress = (float)playedBytes / fileSize * 100;
Serial.printf("🎵 播放中:%s | 进度:%ld:%ld / %ld:%ld,%.1f%% | 音量:%d\n", playList[currentIndex],playedBytes/60,playedBytes%60,fileSize/60,fileSize%60,progress, audio.getVolume());
lastPrint = millis();
}
} else {
// 播放完成,切换到下一首
currentIndex++;
// 索引超出列表,回到第一首(整体循环)
if (currentIndex >= totalSongs) {
currentIndex = 0;
Serial.println("🔄 播放列表完成,重新开始循环!");
}
// 播放下一首
Serial.printf("➡️ 切换至下一首:%s...", playList[currentIndex]);
playSong(currentIndex);
Serial.println("成功!");
delay(500); // 切换间隔,避免频繁触发
}
}
// ------------------- 新增函数:播放指定索引的歌曲 -------------------
void playSong(int index) {
if (!audio.connecttoFS(SD, playList[index])) {
Serial.printf("❌ 播放%s失败!\n", playList[index]);
while (1) delay(1000); // 单首播放失败则卡死,可根据需求修改
}
}
OLED关键代码(U8g2)
需安装U8g2 2.35.30库
#include <Arduino.h>
#include <U8g2lib.h>
#include <Wire.h>
U8G2_SSD1306_128X64_NONAME_1_HW_I2C u8g2(U8G2_R0, /* reset=*/ U8X8_PIN_NONE, /* clock=*/ 6, /* data=*/ 5); // ESP32 Thing, HW I2C with pin remapping
void setup(void) {
u8g2.begin();
u8g2.enableUTF8Print(); // enable UTF8 support for the Arduino print() function
}
void loop(void) {
u8g2.setFont(u8g2_font_wqy15_t_gb2312); // use chinese2 for all the glyphs of "你好世界"
u8g2.setFontDirection(0);
u8g2.firstPage();
do {
//u8g2.setCursor(0, 15);
//u8g2.print("Hello World!");
u8g2.setCursor(0, 15);
u8g2.print("日照香炉生紫烟,"); // Chinese "Hello World"
u8g2.setCursor(0, 30);
u8g2.print("遥看瀑布挂前川。"); // Chinese "Hello World"
u8g2.setCursor(0, 45);
u8g2.print("飞流直下三千尺,"); // Chinese "Hello World"
u8g2.setCursor(0, 60);
u8g2.print("疑是银河落九天。"); // Chinese "Hello World"
} while ( u8g2.nextPage() );
delay(1000);
}
显示效果如图。

补充说明下,上面显示的都是静态文字或符号,如需显示动态变量,如歌曲进度。需要使用sprintf 函数,对各类型进行转换(如整数、浮点等)
比如在显示歌曲进度部分,就使用了
sprintf(music_Progress, "%ld:%ld/%ld:%ld %.0f%% %d\n",currentTime/60,currentTime%60,duration/60,duration%60,progress, audio.getVolume());
u8g2.print(music_Progress);
u8g2.firstPage();
do {
sprintf(musicID, "%s", playList[currentIndex]);
sprintf(musicID_CN, "%s", musicList[currentIndex]);
sprintf(music_Progress, "%ld:%ld/%ld:%ld %.0f%% %d\n",currentTime/60,currentTime%60,duration/60,duration%60,progress, audio.getVolume());
u8g2.setCursor(0, 15);
u8g2.print("寒假在家一起练"); // Chinese "Hello World"
u8g2.setCursor(0, 30);
u8g2.print(musicID);
u8g2.setCursor(0, 45);
u8g2.print(musicID_CN);
u8g2.setCursor(0, 60);
u8g2.print(music_Progress);
} while (u8g2.nextPage());
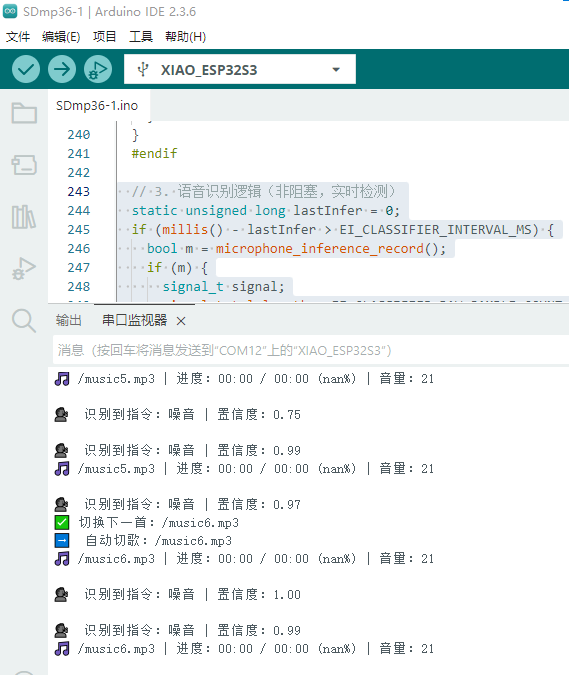
最重要的语音识别和控制逻辑如下:
run_classifier(&signal, &result, debug_nn); 获得识别结果,再进行循环对比获得置信度最高的语音指令(pred_index编号,pred_value 置信度、result.classification[pred_index].label 语音标签:比如"上一曲"、“下一曲”、“播放”、“暂停”等)
再对标签进行判断,进而进行响应的控制逻辑,比如切歌、亮灯等。
// 3. 语音识别逻辑(非阻塞,实时检测)
static unsigned long lastInfer = 0;
if (millis() - lastInfer > EI_CLASSIFIER_INTERVAL_MS) {
bool m = microphone_inference_record();
if (m) {
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = { 0 };
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r == EI_IMPULSE_OK) {
// 寻找置信度最高的语音指令
int pred_index = -1;
float pred_value = 0.0;
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
if (result.classification[ix].value > pred_value) {
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// 置信度超过阈值,执行指令
if (pred_value >= VOICE_THRESHOLD && pred_index != -1) {
isVoiceSwitch = true; // 标记语音切歌,暂停自动切歌
String cmd = result.classification[pred_index].label;
#if DEBUG_SERIAL
Serial.printf("\n🗣️ 识别到指令:%s | 置信度:%.2f\n", cmd.c_str(), pred_value);
#endif
// 指令映射:根据你的Edge Impulse模型标签修改!
// 【关键】替换为你训练的标签,如"next"、"prev"、"pause"、"play"
if (cmd == "下一曲") {
playNextSong();
} else if (cmd == "上一曲") {
playPrevSong();
}
else if (cmd == "播放") {
playingSong();
}
else if (cmd == "暂停") {
pausingSong();
}
isVoiceSwitch = false; // 解除语音切歌标记
}
}
}
lastInfer = millis();
}
}
以下是之前的测试视频,识别率还可以:
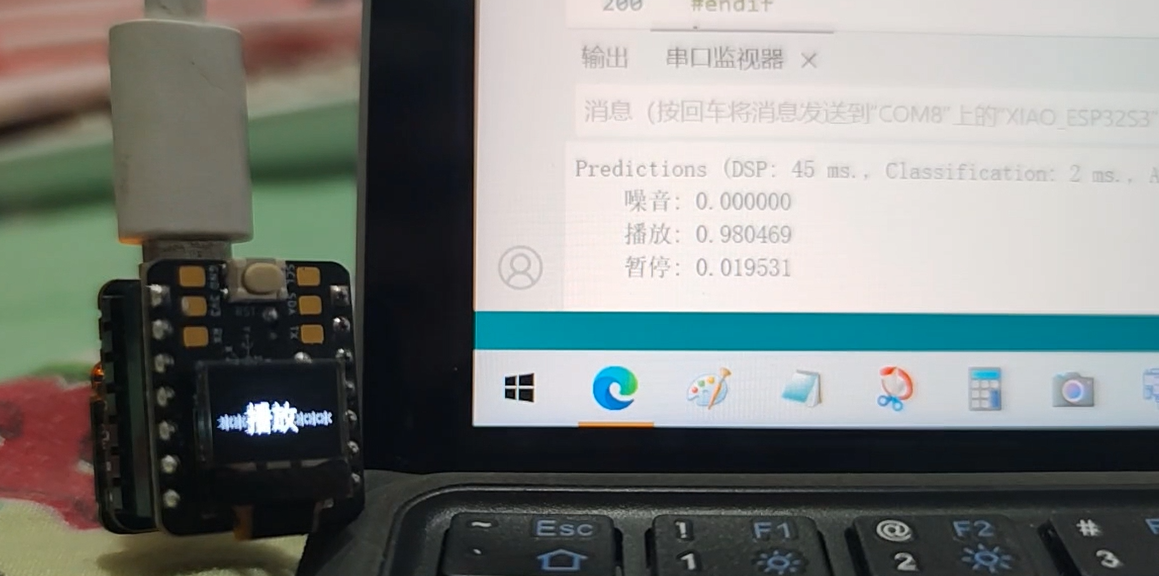
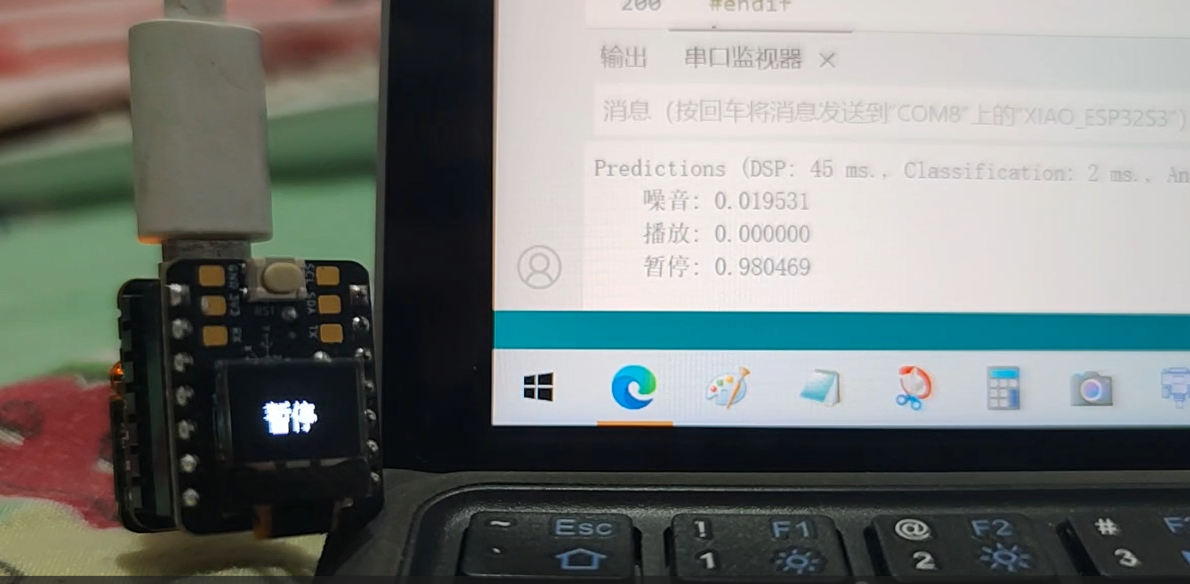
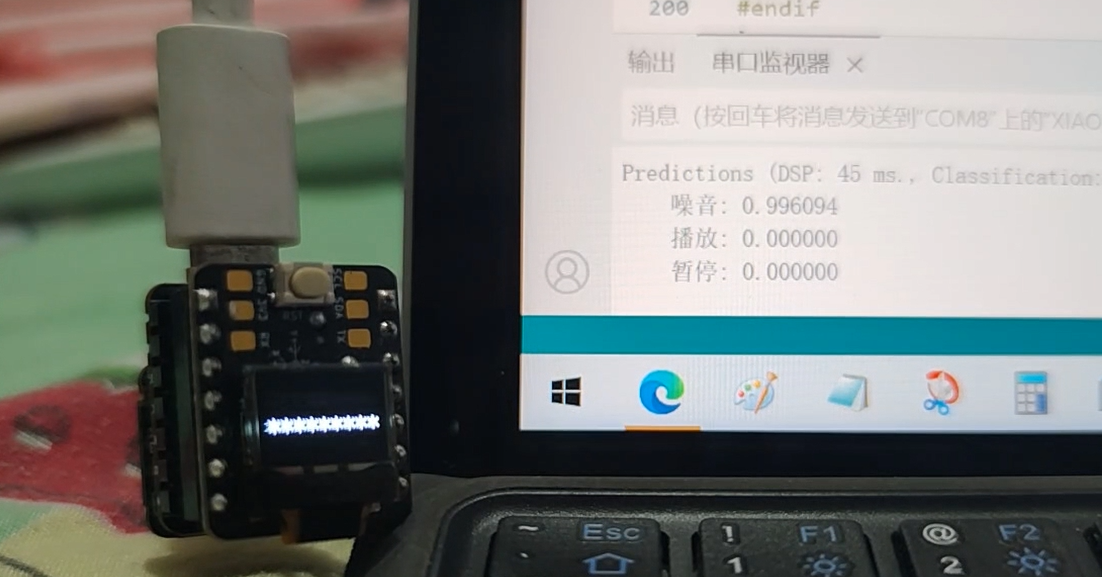
- 功能展示图及说明(可包含实物展示/软件/串口/工具调试结果图等)
实物运行照片
1. 预置不少于 3 段(6首mp3)旋律序列,通过扬声器播放;完成
2. 如若使用蜂鸣器,需要使用RGB 灯带按节拍或音符强弱做律动灯效;若使用扬声器,无需使用RGB灯。无需
3. 麦克风关键词识别实现播放、暂停、下一首、上一首、音量大、音量小等至少 3 条指令,注意指令必须包含切换播放曲目。语音识别可使用EDGE IMPULSE、ESP-SR或上位机等部署相关模型;完成,可以语音切歌、播放、暂停
4. OLED 显示曲目编号、播放进度百分比、当前音量;完成
- 项目中遇到的难题及解决方法
第一个难题是:
MAX98357模块,在测试中发现,必须手摸着BCLK引脚才能播放音乐,否则没声音。
为了豆包:
MAX98357A 是 I2S 音频功放,BCLK(位时钟)是它的核心同步信号 —— 没有稳定的 BCLK 信号,功放无法解析 I2S 音频数据,自然不出声;手触摸时:
- 信号补全:人体感应到周围的电磁信号(比如 ESP32 的时钟辐射),给 BCLK 引脚提供了微弱的时钟信号,功放勉强工作;
- 接地回路:人体连接了 BCLK 引脚到地的 “临时回路”,解决了引脚悬空 / 虚接的问题;
- 接触电阻补偿:手触摸消除了引脚虚焊 / 接触不良的电阻,让信号能正常传输。
后面我的解决方案是:接一条飞线就可以了,如图上面的那条黑线。

第二个难题是:
edge impulse的识别率低,后面琢磨了采样时机的问题,采用修正了语音分割方法(上面有讲):
大概5~6个方格,一上来就说话(语音在方格最左边)
大概5~6个方格,等片刻(约200ms)才说话(语音在方格最中间)
大概5~6个方格,刚结束就说完(语音在方格最右边)
识别率就高一些了。当然最终极办法是采用群友的方案:滑动采样,后面再研究测试了。
- 心得体会
一个完整的工程涉及软件、硬件,时间、精力等等,唯有一定时间的学习、投入、测试,才能吃透过程点,才能完成最终的项目,这是对工程师能力的历练和性格的磨练(毕竟会遇到很多问题点)
非常感谢本次硬禾的活动,我收获了不少,后面有时间,我会琢磨钻研下,实现一个ESP32+6轴平衡车。


