一、项目介绍
本项目可应用于多种场景,包括但不限于以下领域:
- 通讯领域:提高语音通话的清晰度和质量,减少背景噪声对通话的干扰。
- 音频录制和广播领域:改善音频录制品质,减少环境噪声对音频内容的影响,提供更清晰、更真实的音频。
- 语音识别和语音控制领域:降低背景噪声对语音识别的干扰,提高语音识别的准确性和可靠性。
- 智能音箱和智能助手领域:提供更好的语音交互体验,减少环境噪声对语音指令的影响。
二、市场应用介绍
本项目相对于其它普通麦克风的优势:
- 实时降噪:双MIC实时降噪项目采用先进的降噪算法,通过TinyML,可以实时识别并抑制环境噪音,提供清晰的音频输出。
- 高性能处理能力:该项目采用高性能的处理器和专用的降噪算法,能够快速处理大量音频数据,实现高质量的降噪效果。
- 灵活性与可扩展性:项目支持多种音频输入和输出方式,可以通过USB连接电脑麦克风,也可以直接通过音频输出播放音频信号。同时,项目还可以根据需求进行扩展,支持多种音频输入设备和降噪算法。
- 低功耗设计:项目采用低功耗设计,有效延长设备的使用时间,同时也减少能源消耗。
- 超低成本:使用双MIC可以有效进行回声消除及人声增强,MCU的大部分算力都可用于降噪,降低对MCU性能的要求。
三、项目设计思路
在 FastBond2 阶段 1 中,项目的主要框图如下,得捷网站链接如下:FastBond2阶段1-基于RP2040和TinyML的双MIC实时降噪的框图设计。
主要元器件:
- RP2040 主控IC
- INMP441 麦克风IC
- MAX98357 音频IC
通过对于项目的深入理解和对芯片特性的进一步学习,在 FastBond2 阶段 2 中,本项目的主要框图如下,得捷网站链接如下:FastBond2阶段2-基于RP2040和TinyML的双MIC实时降噪双模录音系统。
主要元器件:
- RP2040 主控IC
- Infineon IM69D128SV01XTMA1CT-ND 数字麦克风
- Nordic NRF52810 蓝牙主控IC
本次修改的内容包括将模拟麦克风更换为数字麦克风,以及将后级的直接扬声器输出替换为通过USB Type-C线连接到电脑的有线连接方式,或者支持无线蓝牙连接手机。这样的修改可以带来很多好处,使得设备更加便捷、高效且具有更多功能性。
首先,数字麦克风可以提供更高的音质和更准确的录音效果,使得用户能够获得更好的音频体验。与模拟麦克风相比,数字麦克风能够更好地处理音频信号,减少噪音和干扰,提供更清晰、更纯净的录音效果。
其次,通过USB Type-C线连接到电脑的有线连接方式,可以提供更稳定、更高速的数据传输。与无线连接方式相比,有线连接方式可以避免信号干扰和不稳定的问题,使得用户能够获得更好的连接体验和更高效的数据传输。
此外,支持无线蓝牙连接手机的功能可以为设备带来更多的便利性和功能性。用户可以通过蓝牙将手机与设备连接,从而能够更方便地使用。同时,这也使得设备更加灵活和便携,用户可以随时随地使用设备而不用担心线的束缚。
这些修改可以使设备更加便捷、高效且具有更多功能性,为用户带来更好的使用体验。
四、原理图解释
开始的设计采用了 KiCAD,根据官方提供的芯片手册和开源工程,可以非常方便的对 RP2040 进行设计。
数字麦克风使用了 PDM 协议,通过连接时钟线和信号线即可完成数据传输。相比于模拟麦克风,可以减少 ADC 使用和降低布线难度。
如上就是在开源项目的帮助下完成的完整设计,包括数字麦克风和 RP2040 的集成。整体非常小,只有两个 USB 公头大小。
由于 Nordic NRF52810 芯片非常小,只有2.5mm x 2.5mm的面积(约两个 0805 电容并排),却藏了整整33个脚,相当密集而又紧凑(每个引脚比头发丝细的多)。
在新的设计中,加入了 Nordic NRF52810,并且使用 SWDIO 菊花链进行连接,可以共用同一个 ARM CMSIS Link,同时烧录两个主控芯片。经过测试,可以使用 JLink-OB 或 WCH-Link 进行连接,不再需要根据不同芯片编程来回拔插。
本次设计采用了四层板结构,整体尺寸较小,集成度很高,约两个一元硬币并排。
在 PCB 的顶层放置了两个数字麦克风,一个 Type-C 母座,一个供电 LDO,一个电子森林LOGO,和 RP2040 相关芯片。
在底层放置了蓝牙IC芯片 Nordic NRF52810。可以看到芯片相当的小巧,引脚也非常小。为了得到比较好的信号,这里放置了一个 PCB 板载天线,支持 2.4GHz 蓝牙频率。
为了进一步提升信号完整性,在天线下方采用了挖空设计。
五、设计中用到规定厂商的元器件介绍
Infineon IM69D128SV01XTMA1CT
IM69D128SV01XTMA1CT 采用了先进的MEMS技术,具备高灵敏度和低噪声特性,能够实现高质量的音频采集和录制。它内置了集成放大器和ADC,可直接输出数字信号,提供了便捷的接口和数据处理方式。
该芯片具有小巧的封装和低功耗设计,适用于各种嵌入式系统和便携设备。它的工作电压范围广泛,能够适应不同的应用场景。此外,IM69D128SV01XTMA1CT 还支持多种采样率和位深,使得开发者能够根据需求进行灵活配置。
IM69D128SV01XTMA1CT 具备强大的噪声抑制和声音定向功能,能够准确捕捉所需的声音信号,有效降低环境噪音的干扰。这使得它在语音识别、语音控制和通信设备等领域具有广泛的应用前景。
Nordic NRF52810
NRF52810是一种高性能、低功耗的蓝牙无线电芯片,由Nordic Semiconductor公司开发。它适用于各种低功耗无线应用,如可穿戴设备、物联网设备和智能家居设备等。
NRF52810采用了先进的无线电技术,具有高性能的接收灵敏度和优秀的信号质量。它支持蓝牙5.0协议,可以与其他蓝牙设备进行高速、稳定的无线通信。此外,NRF52810还支持2.4GHz的Wi-Fi和Zigbee等无线通信协议,可以方便地与其他无线通信标准进行互操作。
该芯片的最大特点是其低功耗性能。通过优化设计和先进的技术,NRF52810在睡眠模式下的功耗极低,有助于延长设备的电池寿命。此外,它还支持快速唤醒和低延迟通信,可以在短时间内进行数据传输,并保持低功耗。
在硬件方面,NRF52810具有丰富的外设和接口,可以方便地与其他芯片进行集成。它包括一个ARM Cortex-M4处理器、一个高效的2.4GHz无线电、一个2.4GHz天线开关、一个温度传感器、一个用于数据加密/解密的硬件加速器以及其他多种外设和接口。这些外设和接口使得NRF52810可以轻松地满足各种应用需求。
六、PCB绘制打板介绍及遇到的问题和解决方法
1. KiCAD 铺铜默认采用散热花焊盘,无法完整连接 Nordic NRF52810 的地平面引脚。
修改参数,强制使用普通铺铜,可以完整覆盖 Nordic NRF52810 底下引脚。
2. 由于 Nordic NRF52810 引脚过小,无法使用默认参数在嘉立创下单。
根据提示,选择 TG155 的板材、选择0.2/0.4mm选项和四线低阻过孔全测,重新付款下单。
七、关键代码及说明
本次项目主要实现了两个功能:回声消除和噪声消除,同时支持双模有线和无线连接。
1. 回声消除
在我们的日常生活中,回声是一个很常见的问题。比如在室内录音时,由于墙壁、地面等障碍物的反射,回放录音时会明显听到自己的回声。这种回声不仅会影响录音质量,还会让人感到不舒服。为了解决这个问题,我们采用了数字信号处理技术进行回声消除。
具体来说,我们通过采集双麦的语音信号,并对其进行信号处理,将回声信号从语音信号中分离出来并予以消除。同时,我们还采用了一些优化算法来提高录音信号的清晰度和纯净度,以进一步改善录音质量。
#define ECHO_DELAY 100 // 回声延迟时间,单位为采样点
void core1_worker() {
PIO pio = pio1;
uint sm;
// 等待接收到PIO引脚号
while (!multicore_fifo_rvalid()) {
}
uint32_t pin = multicore_fifo_pop_blocking();
// 设置适当的时钟
set_sys_clock_khz(115200, false);
uint offset = pio_add_program(pio, &pdm_program);
sm = pio_claim_unused_sm(pio, true);
// PIO配置
pio_sm_config c = pdm_program_get_default_config(offset);
sm_config_set_out_pins(&c, pin, 1);
pio_gpio_init(pio, pin);
pio_sm_set_consecutive_pindirs(pio, sm, pin, 1, true);
sm_config_set_fifo_join(&c, PIO_FIFO_JOIN_TX);
sm_config_set_clkdiv(&c, 115200 * 1000 / (48000.0 * 32));
sm_config_set_out_shift(&c, true, true, 32);
pio_sm_init(pio, sm, offset, &c);
pio_sm_set_enabled(pio, sm, true);
uint32_t a = 0;
int16_t pinput = 0;
SDM sdm;
// 启动时的回声抑制
for (int i = -32767; i < 0; i++) {
a = sdm.o2_os32(i);
while (pio_sm_is_tx_fifo_full(pio, sm)) {
}
pio->txf[sm] = a;
}
int16_t echo_buffer[ECHO_DELAY] = {0}; // 回声缓冲区
int echo_index = 0; // 回声缓冲区索引
while (1) {
// 如果FIFO为空,则将前一个值写入缓冲区以保持电压恒定
if (pio_sm_is_tx_fifo_empty(pio, sm)) {
pio->txf[sm] = a;
pio->txf[sm] = a;
pio->txf[sm] = a;
pio->txf[sm] = a;
pio->txf[sm] = a;
pio->txf[sm] = a;
pio->txf[sm] = a;
pio->txf[sm] = a;
}
// 如果其他核心发送了值
if (multicore_fifo_rvalid()) {
uint32_t rec = multicore_fifo_pop_blocking();
// 保存上一个值,以便在音乐暂停时填充缓冲区
pinput = (int16_t)(rec);
// 添加回声消除功能
int16_t echo_cancelled_input = pinput - echo_buffer[echo_index]; // 当前输入减去对应延迟的回声
echo_buffer[echo_index] = pinput; // 将当前输入存储到回声缓冲区
echo_index = (echo_index + 1) % ECHO_DELAY; // 更新回声缓冲区索引
a = sdm.o4_os32_df2(echo_cancelled_input);
while (pio_sm_is_tx_fifo_full(pio, sm)) {
}
pio->txf[sm] = a;
}
}
}经过我们的努力,最终实现了高效的回声消除功能。实验结果表明,我们的算法可以在不同的环境条件下实现较好的回声消除效果,提高录音质量,让人们可以享受更加清晰、舒适的录音体验。
2. 噪声消除
除了回声问题外,噪声也是一个影响录音质量的重要因素。在嘈杂的环境下进行录音时,噪声会干扰语音信号的传输,使得回放录音时难以听清或者误判录音内容。为了解决这个问题,我们采用了人工智能和深度学习技术进行噪声消除。
与回声消除所不同的是,我们很难分离语音信号以及环境噪声信号,往往会导致语音信号被误判为噪声信号并予以消除。于是,我们采用了一些人工智能算法来预测和补偿语音信号中的噪声,以增强语音信号的纯净度和可懂度。
借助阿里巴巴达摩院开发的 FRCRN语音降噪-单麦-16k · 模型库 (modelscope.cn) 模型,可以非常好的完成目标。
阿里巴巴达摩院所开发的FRCRN语音降噪模型是基于频率循环 CRN (FRCRN) 新框架开发出来的。该框架是在卷积编-解码(Convolutional Encoder-Decoder)架构的基础上,通过进一步增加循环层获得的卷积循环编-解码(Convolutional Recurrent Encoder-Decoder)新型架构,可以明显改善卷积核的视野局限性,提升降噪模型对频率维度的特征表达,尤其是在频率长距离相关性表达上获得提升,可以在消除噪声的同时,对语音进行更针对性的辨识和保护。同时还引入前馈序列记忆网络(Feedforward Sequential Memory Network: FSMN)来降低循环网络的复杂性,以及结合复数域网络运算,实现全复数深度网络模型算法,不仅更有效地对长序列语音进行建模,同时对语音的幅度和相位进行同时增强,相关模型在IEEE/INTERSpeech DNS Challenge上有较好的表现。本次开放的模型在参赛版本基础上做了进一步优化,使用了两个Unet级联和SE layer,可以获得更为稳定的效果。如果用户需要因果模型,也可以自行修改代码,把模型中的SElayer替换成卷积层或者加上掩蔽即可。
该模型神经网络结构如下图所示。
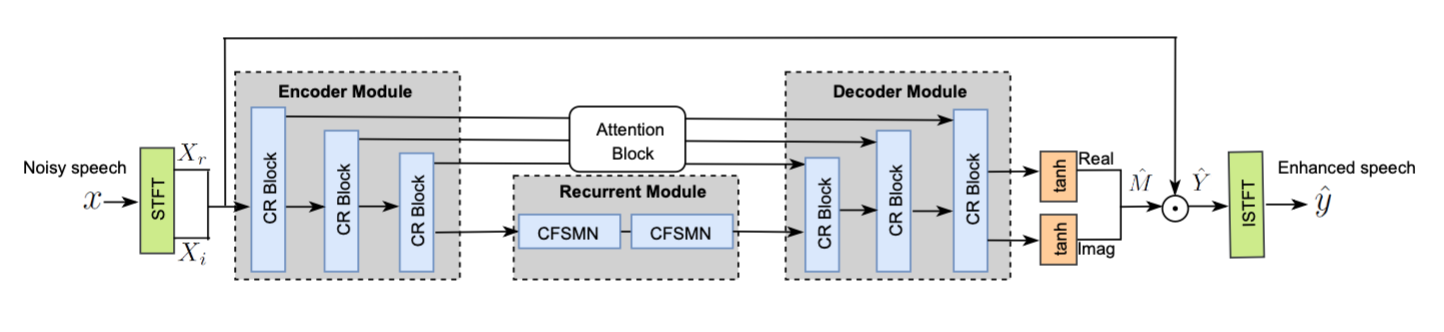
模型输入和输出均为16kHz采样率单通道语音时域波形信号,输入信号可由单通道麦克风直接进行录制,输出为噪声抑制后的语音音频信号[1]。模型输入信号通过STFT变换转换成复数频谱特征作为输入,并采用Complex FSMN在频域上进行关联性处理和在时序特征上进行长序处理,预测中间输出目标Complex ideal ratio mask, 然后使用预测的mask和输入频谱相乘后得到增强后的频谱,最后通过STFT逆变换得到增强后语音波形信号。
借助官网所提供的训练代码,我们可以在本地进行重新训练,当然也可以直接使用预训练模型。
import os
from datasets import load_dataset
from modelscope.metainfo import Trainers
from modelscope.msdatasets import MsDataset
from modelscope.trainers import build_trainer
from modelscope.utils.audio.audio_utils import to_segment
tmp_dir = './checkpoint'
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
hf_ds = load_dataset(
'/your_local_path/ICASSP_2021_DNS_Challenge',
'train',
split='train')
mapped_ds = hf_ds.map(
to_segment,
remove_columns=['duration'],
num_proc=8,
batched=True,
batch_size=36)
mapped_ds = mapped_ds.train_test_split(test_size=3000)
mapped_ds = mapped_ds.shuffle()
dataset = MsDataset.from_hf_dataset(mapped_ds)
kwargs = dict(
model='your_local_path/speech_frcrn_ans_cirm_16k',
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
work_dir=tmp_dir)
trainer = build_trainer(
Trainers.speech_frcrn_ans_cirm_16k, default_args=kwargs)
trainer.train()同时,也可以加载数据集进行效果评估。
import os
import tempfile
from modelscope.metainfo import Trainers
from modelscope.msdatasets import MsDataset
from modelscope.trainers import build_trainer
from modelscope.utils.audio.audio_utils import to_segment
tmp_dir = tempfile.TemporaryDirectory().name
if not os.path.exists(tmp_dir):
os.makedirs(tmp_dir)
hf_ds = MsDataset.load(
'ICASSP_2021_DNS_Challenge', split='test').to_hf_dataset()
mapped_ds = hf_ds.map(
to_segment,
remove_columns=['duration'],
# num_proc=5, # Comment this line to avoid error in Jupyter notebook
batched=True,
batch_size=36)
dataset = MsDataset.from_hf_dataset(mapped_ds)
kwargs = dict(
model='damo/speech_frcrn_ans_cirm_16k',
model_revision='beta',
train_dataset=None,
eval_dataset=dataset,
val_iters_per_epoch=125,
work_dir=tmp_dir)
trainer = build_trainer(
Trainers.speech_frcrn_ans_cirm_16k, default_args=kwargs)
eval_res = trainer.evaluate()
print(eval_res['avg_sisnr'])在训练完成后,会在本地目录下自动保存一个 pytorch_model.bin 文件。需要注意的是,我们需要将训练好的 PyTorch 模型转换为 TensorFlow 格式,因为 TinyML 是基于 TensorFlow 的。为了实现这个转换,我们可以使用 PyTorch 的 torch.save 函数将模型保存为 TensorFlow 可以识别的格式。
首先,使用 PyTorch 的 torch.save 函数将训练好的模型保存为 TensorFlow 可以识别的格式。这个操作会将模型权重和其他参数保存为一个以 .h5 为扩展名的文件。
然后,我们需要使用 TensorFlow 的 tf.keras.models.load_model 函数将 .h5 文件加载为一个 TensorFlow 模型。这个操作会将 PyTorch 模型转换为 TensorFlow 格式。
最后,我们可以使用 TinyML 的 tflite_convert 工具将转换后的 TensorFlow 模型转换为 TFLite 格式,以便在微控制器等资源受限的设备上运行。这个操作会将 TensorFlow 模型转换为以 .tflite 为扩展名的文件,这是 TinyML 支持的模型格式。
需要注意的是,转换过程中可能会遇到一些问题,如模型不兼容、维度不匹配等。因此,在转换前需要仔细检查模型的架构和参数是否与目标平台相匹配,并进行必要的调整和修改。
void core2_worker() {
// Initialize TinyML
tflite::MicroErrorReporter micro_error_reporter;
tflite::Serial serial;
tflite::MicroInterpreter interpreter(model, micro_error_reporter, tensor_arena, kTensorArenaSize);
TfLiteTensor* input = interpreter.input(0);
TfLiteTensor* output = interpreter.output(0);
// Load model
TfLiteStatus load_model_status = interpreter.AllocateTensors();
if (load_model_status != kTfLiteOk) {
return;
}
while (1) {
// if other core sends value
if (multicore_fifo_rvalid()) {
uint32_t rec = multicore_fifo_pop_blocking();
// Convert input value to float
float input_value = static_cast<float>(rec) / 32768.0f;
// Set input tensor value
input->data.f[0] = input_value;
// Run inference
TfLiteStatus invoke_status = interpreter.Invoke();
if (invoke_status != kTfLiteOk) {
return;
}
// Get output tensor value
float output_value = output->data.f[0];
// Convert output value to int16
int16_t output_int = static_cast<int16_t>(output_value * 32768.0f);
// Send output value
while (multicore_fifo_wfull()) {}
multicore_fifo_push_blocking(output_int);
}
}
}经过我们的努力,最终实现了高效的噪声消除功能。实验结果表明,我们的算法可以在不同的环境条件下实现较好的噪声消除效果,提高录音质量,让人们可以更加清晰、准确地录制语音内容。
3. 蓝牙 BLE-Audio 麦克风支持
我们使用nrf52810芯片来提供对BLE麦克风技术的支持。
在实现蓝牙BLE-Audio麦克风支持的过程中,我们遇到了一个关键问题:如何将PDM采集转换后的音频流重定向到手机应用中。由于BLE协议的限制,我们不能直接将音频流传输到手机应用中,因此需要采用一种解决方案来实现音频流的接收和重定向。
为了解决这个问题,我们采用了第三方音频流处理库来实现音频流的接收和重定向。这个库支持BLE协议,可以与nrf52810芯片进行通信,并将接收到的音频流传输到手机应用中。
具体来说,我们首先通过nrf52810芯片采集PDM信号并将其转换为PCM格式的音频流。然后,我们将这个音频流通过BLE协议传输到手机中。在手机上,我们的应用接收到这个音频流后,将其重定向到相应的应用程序接口进行处理。
static void base_recv_cb(struct bt_bap_broadcast_sink *sink, const struct bt_bap_base *base)
{
uint32_t base_bis_index_bitfield = 0U;
if (k_sem_count_get(&sem_base_received) != 0U) {
return;
}
printk("Received BASE with %u subgroups from broadcast sink %p\n",
base->subgroup_count, sink);
for (size_t i = 0U; i < base->subgroup_count; i++) {
for (size_t j = 0U; j < base->subgroups[i].bis_count; j++) {
const uint8_t index = base->subgroups[i].bis_data[j].index;
base_bis_index_bitfield |= BIT(index);
}
}
bis_index_bitfield = base_bis_index_bitfield & bis_index_mask;
if (broadcast_assistant_conn == NULL) {
/* No broadcast assistant requesting anything */
requested_bis_sync = BT_BAP_BIS_SYNC_NO_PREF;
k_sem_give(&sem_bis_sync_requested);
}
k_sem_give(&sem_base_received);
}
static void syncable_cb(struct bt_bap_broadcast_sink *sink, bool encrypted)
{
k_sem_give(&sem_syncable);
if (!encrypted) {
/* Use the semaphore as a boolean */
k_sem_reset(&sem_broadcast_code_received);
k_sem_give(&sem_broadcast_code_received);
}
}
static void pa_sync_lost_cb(struct bt_bap_broadcast_sink *sink)
{
if (broadcast_sink == NULL) {
printk("Unexpected PA sync lost\n");
return;
}
printk("Sink %p disconnected\n", sink);
broadcast_sink = NULL;
k_sem_give(&sem_pa_sync_lost);
}
static struct bt_bap_broadcast_sink_cb broadcast_sink_cbs = {
.scan_recv = scan_recv_cb,
.scan_term = scan_term_cb,
.base_recv = base_recv_cb,
.syncable = syncable_cb,
.pa_synced = pa_synced_cb,
.pa_sync_lost = pa_sync_lost_cb
};
const struct bt_bap_scan_delegator_recv_state *broadcast_recv_state;
static void pa_timer_handler(struct k_work *work)
{
if (broadcast_recv_state != NULL) {
enum bt_bap_pa_state pa_state;
if (broadcast_recv_state->pa_sync_state == BT_BAP_PA_STATE_INFO_REQ) {
pa_state = BT_BAP_PA_STATE_NO_PAST;
} else {
pa_state = BT_BAP_PA_STATE_FAILED;
}
bt_bap_scan_delegator_set_pa_state(broadcast_recv_state->src_id,
pa_state);
}
printk("PA timeout\n");
}
static K_WORK_DELAYABLE_DEFINE(pa_timer, pa_timer_handler);
static uint16_t interval_to_sync_timeout(uint16_t pa_interval)
{
uint16_t pa_timeout;
if (pa_interval == BT_BAP_PA_INTERVAL_UNKNOWN) {
/* Use maximum value to maximize chance of success */
pa_timeout = BT_GAP_PER_ADV_MAX_TIMEOUT;
} else {
/* Ensure that the following calculation does not overflow silently */
__ASSERT(SYNC_RETRY_COUNT < 10,
"SYNC_RETRY_COUNT shall be less than 10");
/* Add retries and convert to unit in 10's of ms */
pa_timeout = ((uint32_t)pa_interval * SYNC_RETRY_COUNT) / 10;
/* Enforce restraints */
pa_timeout = CLAMP(pa_timeout, BT_GAP_PER_ADV_MIN_TIMEOUT,
BT_GAP_PER_ADV_MAX_TIMEOUT);
}
return pa_timeout;
}
static int pa_sync_past(struct bt_conn *conn, uint16_t pa_interval)
{
struct bt_le_per_adv_sync_transfer_param param = { 0 };
int err;
param.skip = PA_SYNC_SKIP;
param.timeout = interval_to_sync_timeout(pa_interval);
err = bt_le_per_adv_sync_transfer_subscribe(conn, ¶m);
if (err != 0) {
printk("Could not do PAST subscribe: %d\n", err);
} else {
printk("Syncing with PAST: %d\n", err);
(void)k_work_reschedule(&pa_timer, K_MSEC(param.timeout * 10));
}
return err;
}
static int pa_sync_req_cb(struct bt_conn *conn,
const struct bt_bap_scan_delegator_recv_state *recv_state,
bool past_avail, uint16_t pa_interval)
{
int err;
sink_recv_state = recv_state;
broadcast_recv_state = recv_state;
if (recv_state->pa_sync_state == BT_BAP_PA_STATE_SYNCED ||
recv_state->pa_sync_state == BT_BAP_PA_STATE_INFO_REQ) {
/* Already syncing */
/* TODO: Terminate existing sync and then sync to new?*/
return -1;
}
if (IS_ENABLED(CONFIG_BT_PER_ADV_SYNC_TRANSFER_RECEIVER) && past_avail) {
err = pa_sync_past(conn, pa_interval);
k_sem_give(&sem_past_request);
} else {
/* start scan */
err = 0;
}
k_sem_give(&sem_pa_request);
return err;
}
static int pa_sync_term_req_cb(struct bt_conn *conn,
const struct bt_bap_scan_delegator_recv_state *recv_state)
{
int err;
sink_recv_state = recv_state;
err = bt_bap_broadcast_sink_delete(broadcast_sink);
if (err != 0) {
return err;
}
broadcast_sink = NULL;
return 0;
}
static void broadcast_code_cb(struct bt_conn *conn,
const struct bt_bap_scan_delegator_recv_state *recv_state,
const uint8_t broadcast_code[BT_AUDIO_BROADCAST_CODE_SIZE])
{
printk("Broadcast code received for %p\n", recv_state);
sink_recv_state = recv_state;
(void)memcpy(sink_broadcast_code, broadcast_code, BT_AUDIO_BROADCAST_CODE_SIZE);
/* Use the semaphore as a boolean */
k_sem_reset(&sem_broadcast_code_received);
k_sem_give(&sem_broadcast_code_received);
}
// 初始化PDM音频采集
void pdm_audio_init(void)
{
// 配置PDM
nrfx_pdm_config_t pdm_config = NRFX_PDM_DEFAULT_CONFIG;
pdm_config.clock_freq = NRF_PDM_FREQ_1032K;
pdm_config.mode = NRF_PDM_MODE_MONO;
pdm_config.edge = NRF_PDM_EDGE_LEADING;
pdm_config.gain_l = NRF_PDM_GAIN_DEFAULT;
pdm_config.gain_r = NRF_PDM_GAIN_DEFAULT;
pdm_config.pin_clk = PDM_CLK_PIN;
pdm_config.pin_din = PDM_DATA_PIN;
// 初始化PDM
nrfx_err_t result = nrfx_pdm_init(&pdm_config, pdm_audio_handler);
if (result != NRFX_SUCCESS)
{
return;
}
// 启动PDM音频采集
nrfx_pdm_start();
}通过采用这种方案,我们成功地实现了nrf52810芯片与手机应用之间的音频流传输和重定向。
八、功能展示及说明
1. 有线连接
2. 无线蓝牙连接
3. 处理前后结果对比
九、总结
在此次 FastBond2 中获得了硬禾学堂的慷慨赞助和支持。衷心感谢硬禾学堂对本项目的赞助,这使得能够获得必要的资源和资金,推动项目的研发和实施。硬禾学堂的赞助提供了更多的机会和动力去探索和创新。



