00 项目介绍
本项目旨在基于树莓派最新推出的RP2350微控制器平台,构建一个具备边缘智能推理能力的嵌入式系统。通过结合TinyML(Tiny Machine Learning)模型与双核异构处理能力,系统可实现对传感器数据的实时采集与智能识别,适用于动态手势识别、动作监测、异常检测等场景。
RP2350芯片是树莓派新一代高性能、低功耗微控制器,支持双核架构(Arm Cortex-M33 + RISC-V Hazard3),并集成丰富的片上资源(包括520KB SRAM与最高2MB QSPI Flash),为运行轻量级神经网络模型提供了良好的硬件基础。此外,芯片还具备TrustZone、Secure Boot、SHA-256加速等硬件安全特性,适用于对安全有较高要求的边缘场景。
在模型开发方面,本项目采用Edge Impulse平台进行数据采集、特征提取、模型训练与导出,最终生成C++推理代码并部署至设备端运行。为提升系统性能,项目充分利用RP2350双核架构:将传感器数据采集任务分配至RISC-V核运行,同时将TinyML模型推理任务交由Arm核执行,实现真正的并行协作与任务解耦。
本项目的完成验证了RP2350在边缘AI方向的可行性,并为未来多核异构嵌入式智能系统的开发提供了实践基础。
01 项目实现思路
1.1 整体思路
1.2 数据采集
为训练具备动作识别能力的嵌入式机器学习模型,本项目设计了标准化的加速度数据采集流程。系统基于KXTJ3三轴加速度传感器,在用户进行指定手势动作时,以固定频率采样并记录对应的加速度变化信息。
1.2.1 传感器工作参数
本项目采用的加速度传感器为 KXTJ3,具备较高的灵敏度与低功耗特性,适用于可穿戴与手势识别场景。其主要工作参数如下:
- 采样率:50 Hz(每秒采集 50 次)
- 数据位深度:14 位(每个轴方向的输出为 14 位原始数值)
- 量程范围:±16G(可测范围最大为 ±16 倍重力加速度)
- 分辨率模式:高分辨率模式(High Resolution Mode)
1.2.2 数据采集方式
- 采样频率:50 Hz(即每 20 ms 采集一次数据)
- 采样时长:每段数据固定为 6 秒,总计 300 个数据点
- 数据格式:
每一行记录一个时间点的加速度信息,包含时间戳及三轴数值,格式如下:
timestamp,X,Y,Z
0,625,731,-1117
20,707,703,-935
40,667,602,-1051
...
其中 timestamp 表示相对于采样开始的毫秒数,X/Y/Z 分别为对应时刻的加速度原始值(单位为 sensor raw count)。
数据集结构与组织
根据不同的手势类别,采集数据按类别划分为三个大类:circle(画圈动作)、rightleft(左右挥动)和 updown(上下挥动)。每个类别目录中包含多个 CSV 文件,分别记录该类手势的训练样本和测试样本数据。数据文件命名方式如下:
- circle1_train.csv ~ circle20_train.csv:训练数据(每类20个)
- circle21_test.csv ~ circle25_test.csv:测试数据(每类5个)
完整的数据目录如下所示:
data/
├── circle/ → 画圈动作数据
├── rightleft/ → 左右挥动动作数据
└── updown/ → 上下挥动动作数据
每个子目录内包含:
- 训练样本:*_train.csv(20个)
- 测试样本:*_test.csv(5个)
- 数据处理脚本:data_transfer.ipynb,用于格式转换与上传至 Edge Impulse 平台
数据标注说明
每组数据在采集前明确指定手势类型,采集过程中用户按照规范动作执行,并在完成后立即保存,确保训练样本的标签与内容一致。整个数据集共包含:
- 3 类手势
- 每类 25 条数据(共 75 条)
- 总数据量约 22,500 条加速度记录(75 × 300)
1.3 模型训练
EdgeImpluse平台使用
EdgeImpluse平台介绍: Edge Impulse 是一个面向嵌入式设备的端侧机器学习开发平台,专为资源受限的微控制器和边缘计算设备设计。该平台提供了从数据采集、特征工程、模型训练到部署的一整套工具链,支持用户通过图形化界面快速构建 TinyML 应用,并可生成高效的 C/C++ 推理代码,便于嵌入式系统直接集成。
1.3.1 上传数据集
创建工程后,选择右侧的Data acquisition,然后选择手动上传数据集。
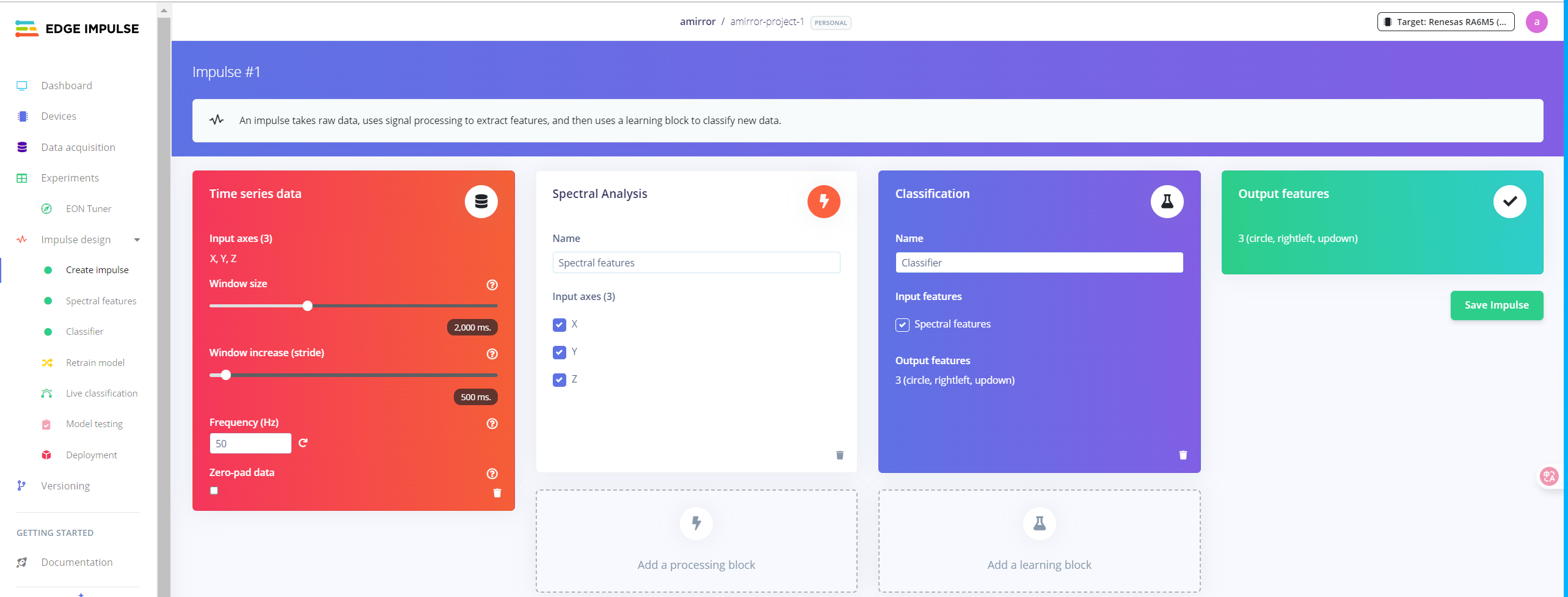
1.3.2 设置识别窗口
选择Create impulse,后设置窗口size 为2000ms,stride为500。频率和数据采集频率保持一致。
1.3.3 特征提取与频谱分析设置
在本阶段,我们使用 Edge Impulse 平台的 Spectral Features(频谱特征)模块对原始加速度数据进行特征提取。该模块主要用于对时间序列信号进行预处理(如滤波、下采样)与频域分析(如 FFT),从而提取适合用于模型分类的高效特征向量。
原始数据可视化
顶部展示了原始加速度传感器在三个轴向(X、Y、Z)的数据变化情况,通过上一步的滑动窗口截取固定时长片段用于后续分析。
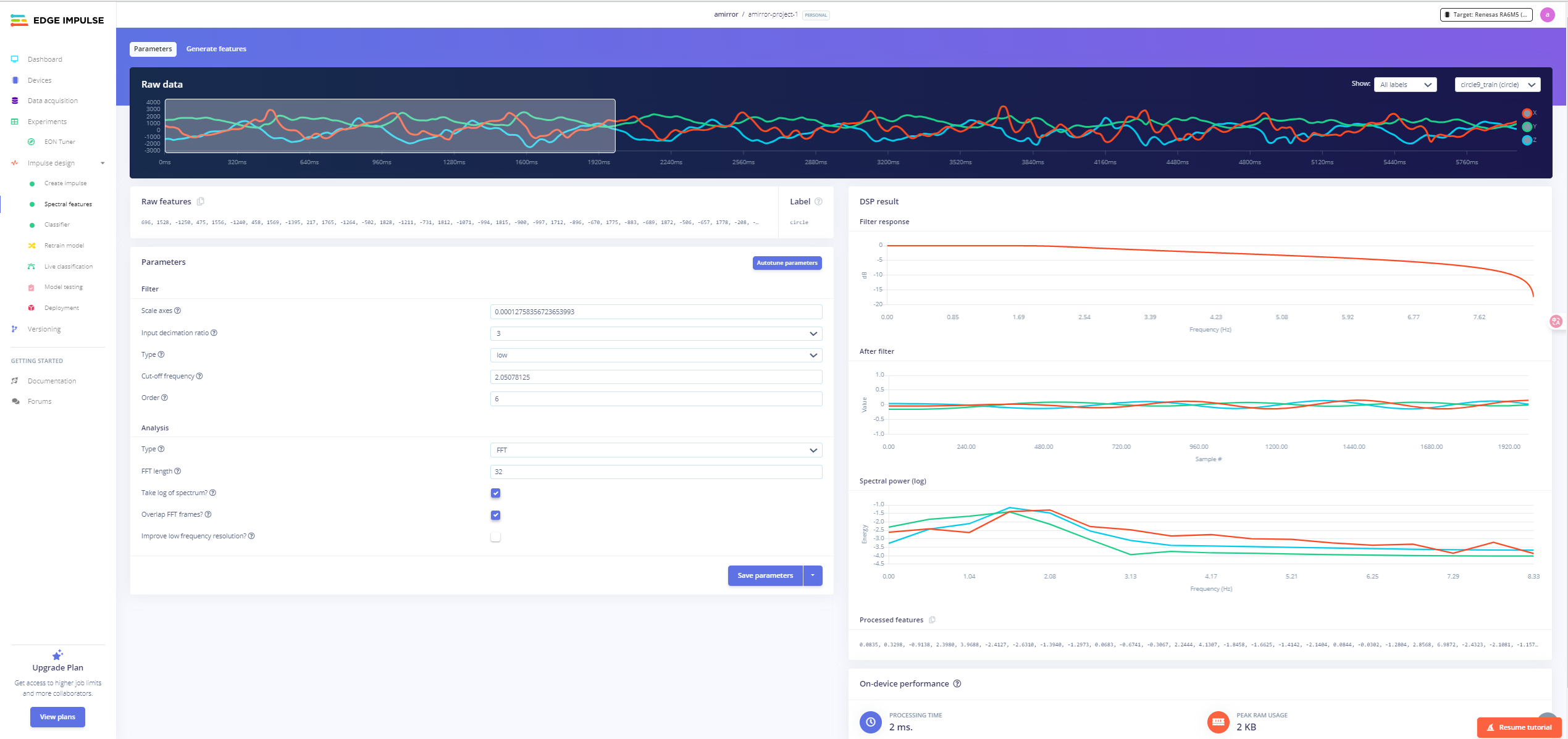
参数设置分析
- Filter(滤波器设置)
- Scale axes:0.0001273856723653993,用于对原始加速度数据进行缩放(单位转换),常用于从原始 count 转换为 g 单位。
- Input decimation ratio:3,表示对原始信号进行下采样,即保留每 3 个样本中的 1 个,有效减少计算量。
- Type:low,低通滤波器,仅保留低频信息,滤除高频噪声。
- Cut-off frequency:2.05087 Hz,截止频率,超过此频率的部分将被显著衰减。
- Order:6,滤波器阶数,控制滤波器陡峭程度,阶数越高,滤波效果越强。
- Analysis(频谱分析设置)
- Type:FFT,使用快速傅里叶变换将时间序列数据转换为频谱数据。
- FFT length:32,FFT 分析的点数,影响频域分辨率与处理速度的权衡。
- Take log of spectrum:启用,表示对 FFT 输出的能量谱进行对数变换,更适合表示不同数量级的频率能量。
- Overlap FFT frames:启用,使用重叠窗口进行 FFT 分析,提高频谱稳定性。
结果输出与性能
右侧图表展示了滤波响应、滤波后波形、频谱功率图等处理结果,底部还列出了最终提取的特征向量。在当前配置下,模型的单帧处理时间仅为 2 ms,内存占用为 2 KB,表现出色,适合部署在资源受限的 MCU 上运行。
1.3.4 构建分类器与训练模型
在模型构建阶段,我们使用 Edge Impulse 平台内置的全连接神经网络(Fully Connected Neural Network, FCNN)进行训练分类模型,结合前一阶段提取的频谱特征,实现对三种不同手势的高精度识别。
模型结构配置
- 输入层:共 27 个特征点,来源于前一阶段频域特征提取。
- 第一隐藏层:Dense(全连接层),包含 32 个神经元。
- Dropout:丢弃率为 0.2,用于防止过拟合。
- 第二隐藏层:Dense,16 个神经元。
- Dropout:丢弃率为 0.1。
- 输出层:3 个神经元,对应 “circle / rightleft / updown” 三类手势。
此结构属于轻量级网络,计算量小、适合部署在资源受限的嵌入式设备上。
训练参数设置
- 训练轮数:50
- 学习率:0.0005
- 优化器:未启用 Learned Optimizer,使用默认优化器(如 Adam)
- 处理器:CPU 模拟训练
- Batch Size:32
- 验证集划分比例:20%
- INT8 量化评估:启用(用于评估量化后模型在设备上的表现)
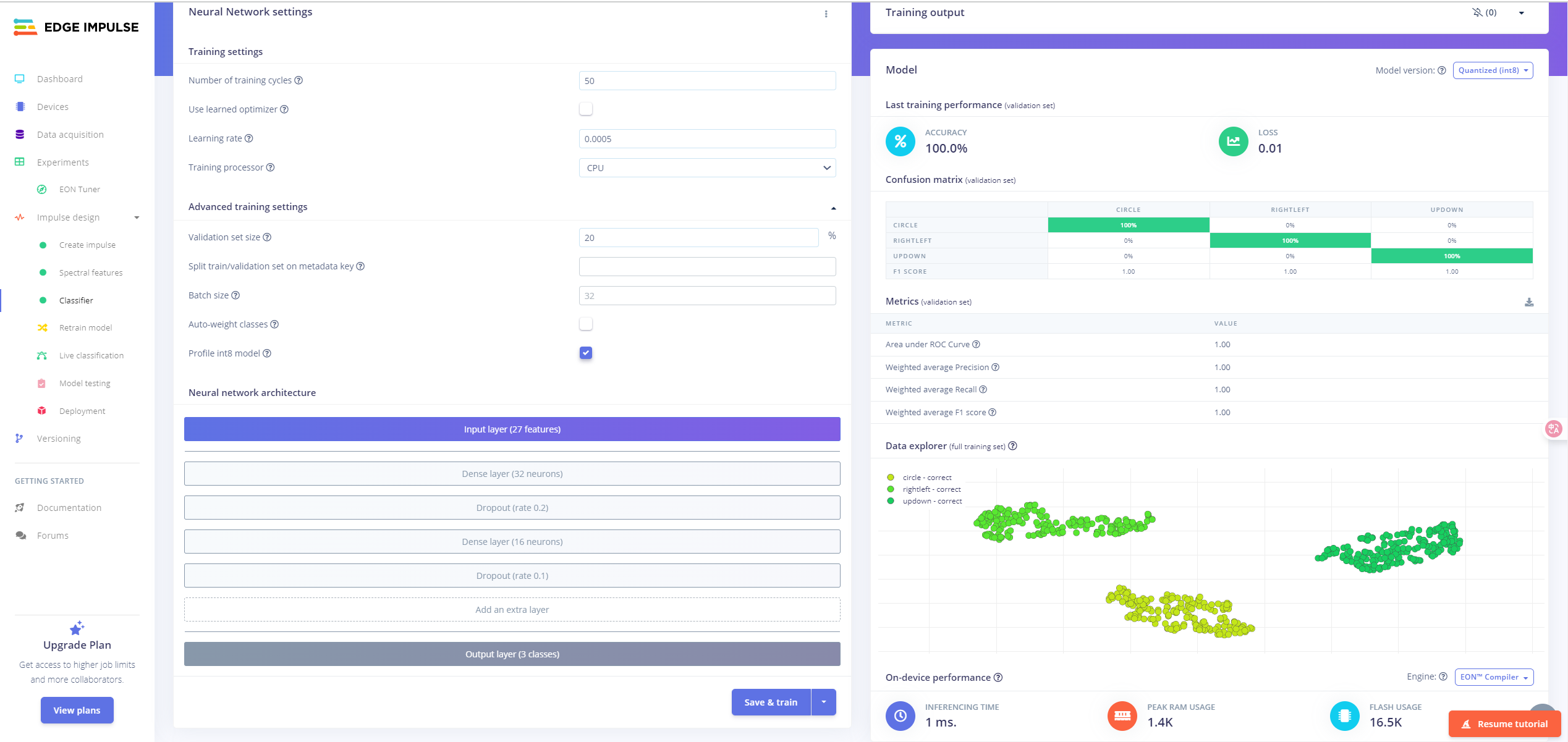
训练结果分析
- 准确率(Accuracy):100%
- 损失值(Loss):0.01,表明模型在验证集上收敛良好
- F1 Score / Precision / Recall:全部为 1.00,说明模型在三个类别上表现一致,没有偏置问题
- 混淆矩阵:无交叉误判,每类样本均被完全识别
嵌入式性能评估
- 推理延迟:1 ms(非常适合实时性要求场景)
- 峰值 RAM 占用:1.4 KB
- Flash 占用:16.5 KB
- 模型版本:已启用 INT8 量化
通过本轮训练配置与模型结构设计,我们在不牺牲精度的前提下获得了极低延迟和内存占用,充分满足 TinyML 部署在 MCU 平台(如 RP2350)上的性能要求。
1.3.5 模型测试
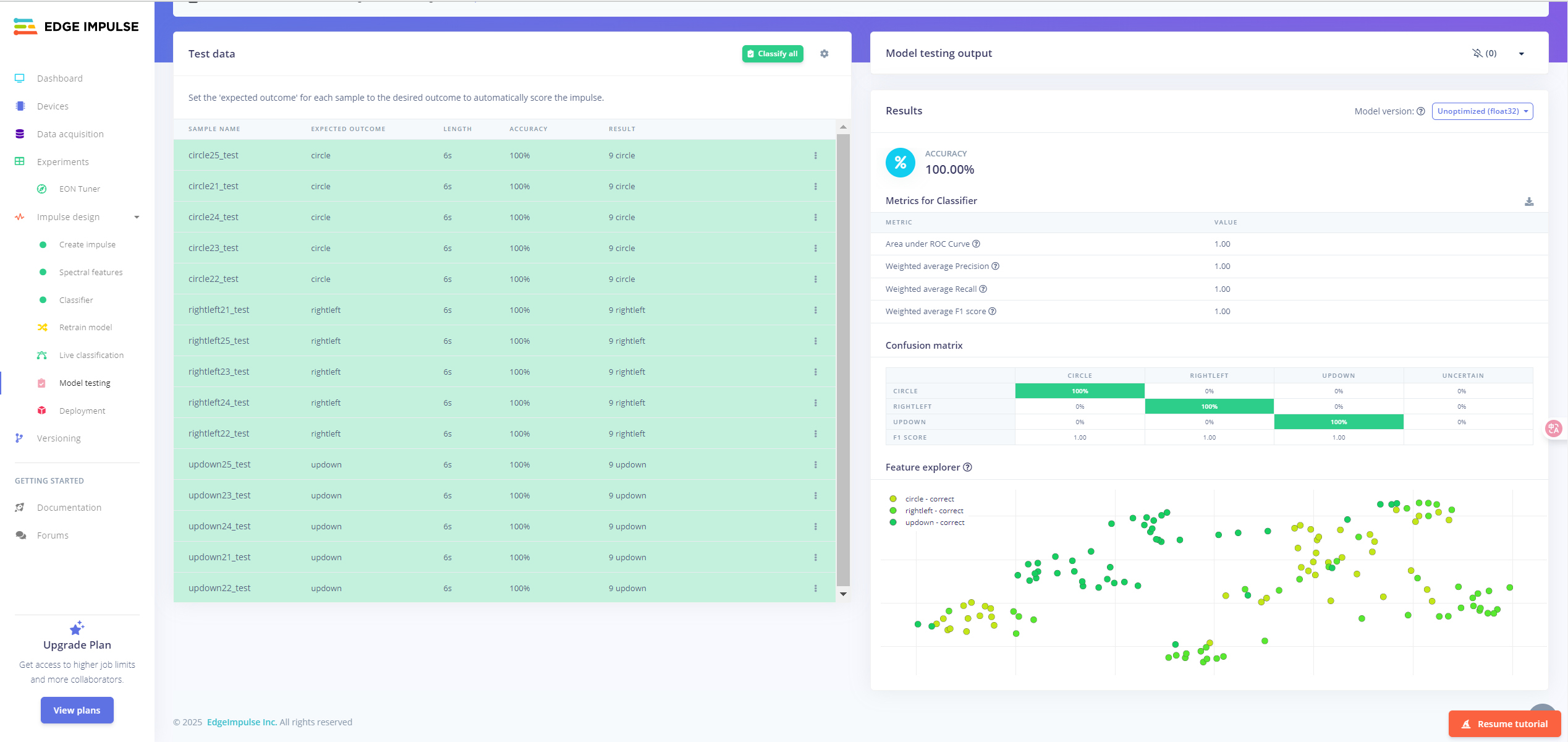
在模型训练完成后,我们使用 Edge Impulse 提供的 Model Testing 模块对导出的模型在验证数据集上的泛化性能进行了全面评估。测试数据为之前划分出的每类 5 条样本,覆盖 “circle / rightleft / updown” 三类手势。
测试结果摘要
- 准确率(Accuracy):100.00%
- 精确率(Precision):1.00
- 召回率(Recall):1.00
- F1 分数(F1 Score):1.00
- ROC 曲线下面积(AUC):1.00
上述指标表明模型在测试集上表现极佳,无错误分类情况,具有极强的泛化能力。
混淆矩阵分析
True \ Pred | Circle | RightLeft | UpDown |
|---|---|---|---|
Circle | 100% | 0% | 0% |
RightLeft | 0% | 100% | 0% |
UpDown | 0% | 0% | 100% |
模型对三类手势样本均识别准确,说明特征空间的边界分离效果良好,没有类别混淆问题。
测试样本情况
每条测试样本均为 6 秒采集时长,对应采样点数为 300。平台自动识别后对每一条样本给出预测结果及置信度,所有结果均与期望类别一致。
特征空间分布
底部的特征可视化分布图展示了模型在特征空间中的决策边界,各类别数据点聚集良好、相互区分明确,进一步验证了模型的可区分性和训练有效性。
1.3.6 模型导出
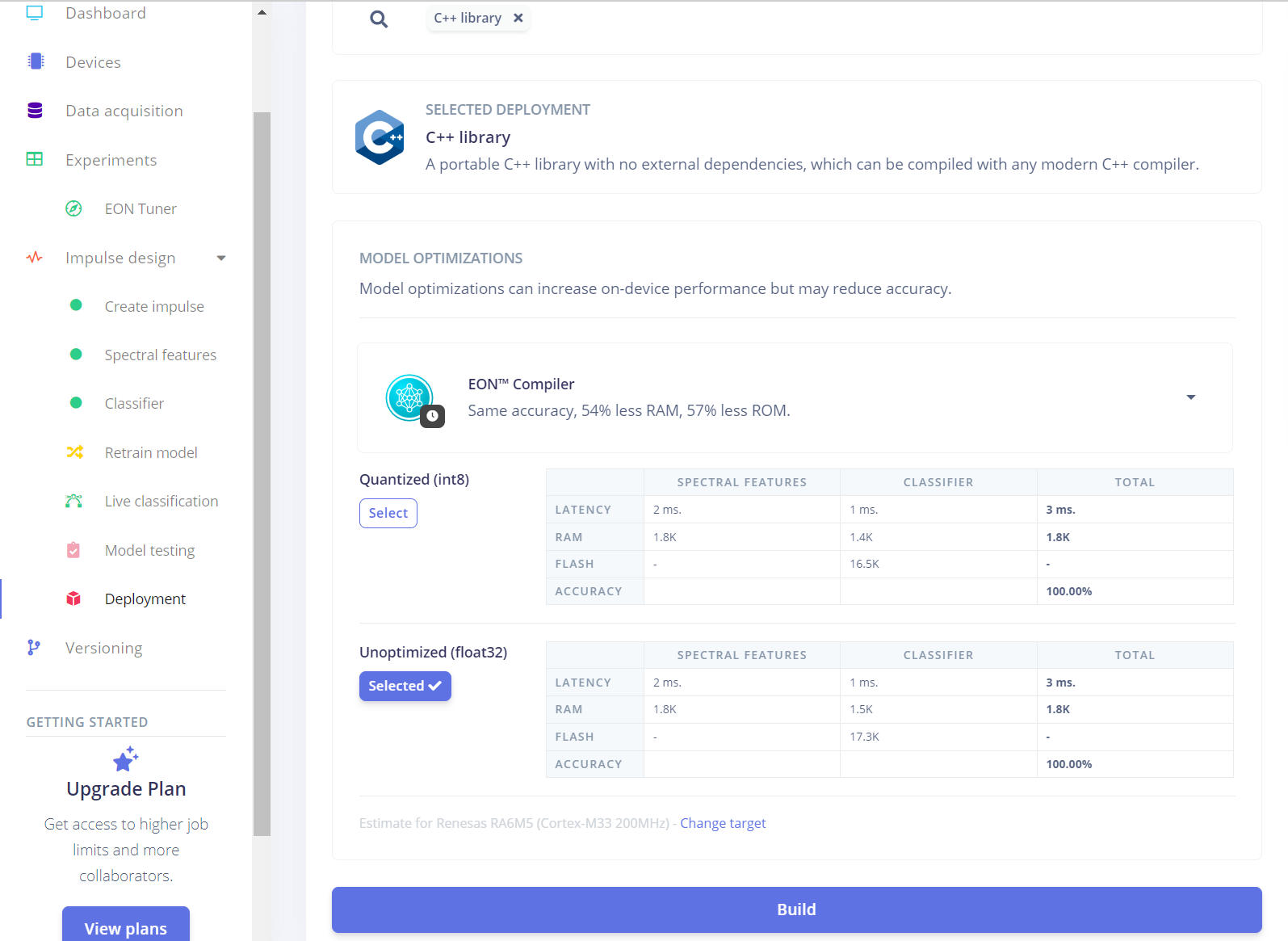
点击右侧的Deployment,在下面有选择要部署的目标平台,这里我们在导出代码时要选择的是PICO RP2040,由于平台还没有RP2350并且RP2040和我们型号最接近,函数也是通用的。这里先选择和RP2350核心最为相近的芯片型号预览一下性能。由于RP2350添加了FPU计算能力,可以发现即使使用未经过量化的模型也能跑出非常快速的成绩,并且识别率更高,占用内存也没有显著提升,这里选择FP32格式进行导出。
1.4 模型部署
本项目使用 Edge Impulse 平台训练生成的模型,最终以 C++ 源码形式导出并部署到树莓派 RP2350 上运行。部署过程包括模型代码集成、CMake 构建配置修改,以及模型接口调用的实现。
模型导出与文件组织
从 Edge Impulse 平台导出模型时,选择 C++ Library 形式,得到的压缩包内容如下:
├── CMakeLists.txt
├── edge-impulse-sdk
├── model-parameters
└── tflite-model
解压后,将这些文件合并到已有项目文件夹中,注意不要覆盖原有的 CMakeLists.txt,应事先备份。最终项目结构如下所示:
├── src/ # 自定义业务逻辑代码目录
├── edge-impulse-sdk/ # Edge Impulse 推理 SDK
├── model-parameters/ # 模型输入维度、标签等参数
├── tflite-model/ # 模型核心代码
├── CMakeLists.txt # 项目构建配置文件
修改 CMakeLists.txt
在项目根目录下的 CMakeLists.txt 文件中,需进行如下几项关键修改以支持模型构建:
- 设置路径变量与编译选项
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
set(MODEL_FOLDER .)
set(EI_SDK_FOLDER edge-impulse-sdk)
- 支持 C/C++ 混合编译
project(my_project C CXX ASM)
- 引入 Edge Impulse 的 CMake 脚本
include(${MODEL_FOLDER}/edge-impulse-sdk/cmake/utils.cmake)
add_subdirectory(${MODEL_FOLDER}/edge-impulse-sdk/cmake/zephyr)
- 添加 include 路径与源文件
使用递归查找模型相关源文件并添加到构建目标:
RECURSIVE_FIND_FILE(SOURCE_FILES "${EI_SDK_FOLDER}" "*.cpp")
target_sources(app PRIVATE ${SOURCE_FILES})
添加模型端口实现文件
创建 src/ei_classifier_porting.cpp,用于实现 Edge Impulse 模型所需的底层接口,如定时器、内存分配和打印函数。部分函数如 ei_read_timer_us() 可能会出现重复定义,根据提示选择注释或保留。
模型推理接口调用
在需要进行模型推理的 .cpp 文件中,包含以下头文件:
#include "edge-impulse-sdk/classifier/ei_run_classifier.h"
#include "edge-impulse-sdk/dsp/numpy_types.h"
同时在使用的 .c 头文件中添加 extern "C" 包装,确保 C/C++ 混合编译正确。
实现推理流程:
float features[DATA_LENGTH] = {0}; // 填充传感器数据
signal_t signal;
numpy::signal_from_buffer(features, DATA_LENGTH, &signal);
ei_impulse_result_t result;
run_classifier(&signal, &result, false); // 执行推理
for (size_t i = 0; i < EI_CLASSIFIER_LABEL_COUNT; i++) {
printf("%s: %.2f\n", result.classification[i].label, result.classification[i].value);
}
其中 DATA_LENGTH 为模型输入长度,由 EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE 宏定义。
02 效果演示与数据分析
2.1 效果演示
由于静态展示不能很好展示效果,具体效果请看视频。
2.2 数据分析
在上方训练结果中,准确率达到了100%,让我十分担心是否过拟合了。这里Edgeimpluse平台并未提供LOSS曲线的查看,我们可以自己进行查看:
点击右侧最上方的Dashboard,点击Jobs,找到Training model (Classifier, Impulse #1)这一项,下载下来,根据里面的log记录自己绘制LOSS曲线。
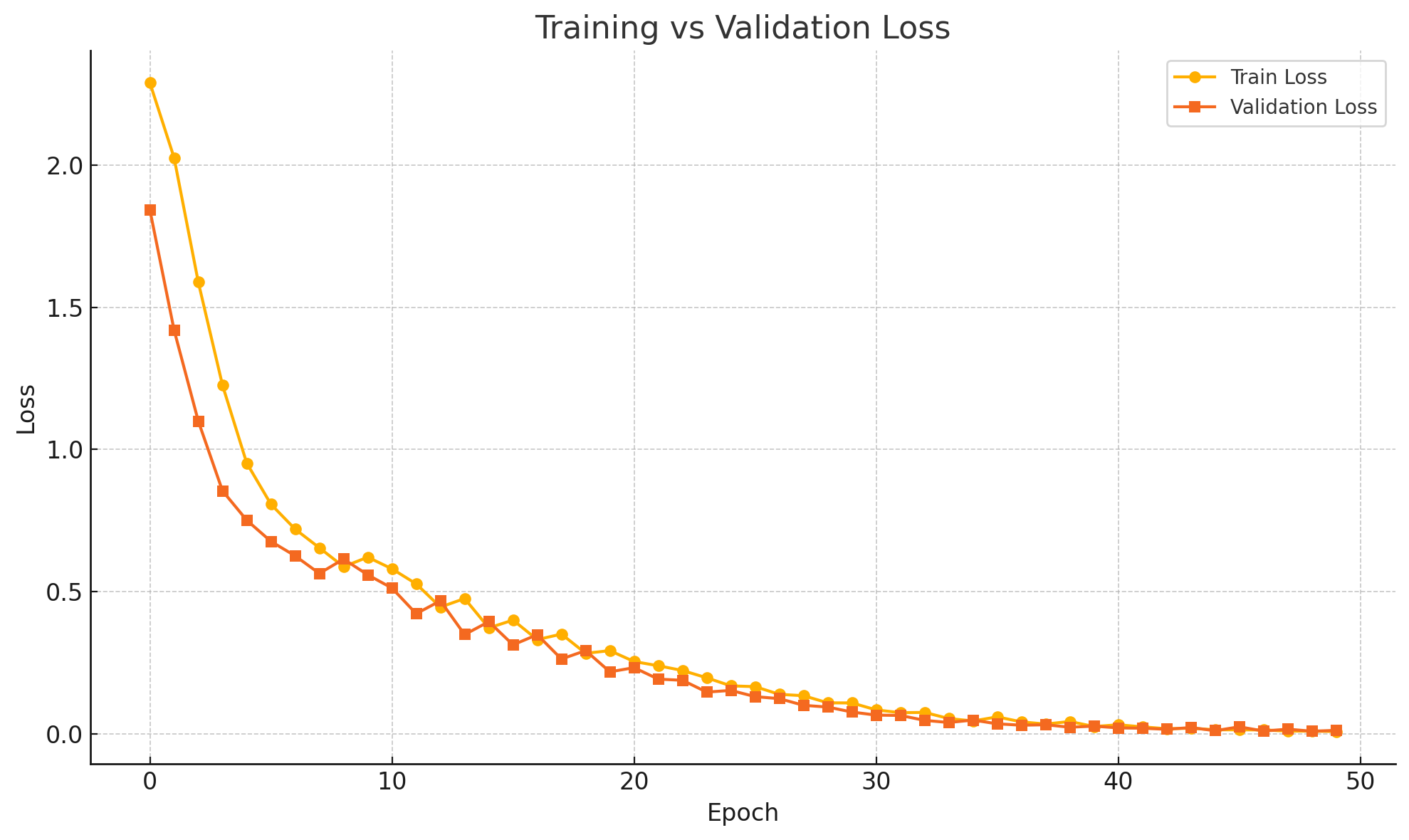
分析结果:
- 训练损失(Train Loss) 和 验证损失(Validation Loss) 都持续下降:
- 说明模型正在有效学习,且没有立刻过拟合。
- 从第 35~40 个 epoch 开始,两条曲线几乎重合并稳定下降
- 没有明显的验证损失反弹或发散现象
- 未出现典型的过拟合趋势(如:训练 loss ↓,但 val loss ↑)
- 最终验证损失甚至略优于训练损失(loss = 0.00925)
- 说明模型泛化能力较好,至少在这批验证集上表现优异
总结:模型并未出现过拟合,但由于100%的准确率仍需要引起警惕,最大可能原因是我的验证集太小或太“干净”,没有噪声 / 无干扰动作,所有样本可能太接近训练集特征空间。
03 心得与总结
本项目是我第一次在嵌入式平台上进行机器学习模型的部署与实测应用。通过整个项目过程,我不仅深入了解了 TinyML 的模型训练与部署流程,也熟悉了嵌入式双核协作、多线程调度、传感器数据采集与预处理等关键开发技能。
本项目所用的 RP2350 芯片基于 ARM Cortex-M33 架构,相较于前代 RP2040 提供了更高的主频、更强的计算能力,并首次引入硬件浮点运算单元(FPU)。在模型部署阶段,我使用了 Edge Impulse 平台导出的 FP32 浮点模型,虽然未进行 INT8 量化压缩,但依靠 RP2350 的强大算力,模型在设备端的推理延迟仍然极低,准确率也得到了良好保持。这让我对 RP2350 在 TinyML 场景下的表现印象深刻。
此外,在实践过程中,我也体会到开发板本身的一些使用痛点。例如,该开发板需要使用跳线帽将 BOOT 引脚与 GND 短接进入烧录模式,烧录后必须手动拔除跳帽才能启动系统,如果忘记拔掉,还需重新断电上电才能正常运行。这一过程在频繁调试和烧录中显得较为繁琐,希望未来可以改进。
总体而言,本次项目极大提升了我在嵌入式 AI 应用开发方面的实践能力,也让我对边缘智能的部署流程与性能优化有了更深的理解。未来,我希望在此基础上尝试更多更复杂的模型结构与感知任务,在功耗、延迟、模型压缩等方面持续优化嵌入式智能系统的设计方案。

