
项目介绍
基于Max78000的人脸打卡机,训练使用阿里云抢占式服务器,底板提供了屏幕、WIFI、光源、电池电源等;
设计了两个界面,分别是ESP8266配置界面,主要是对ESP8266进行AT指令配置,带进度条显示功能,第二个界面是人脸识别界面,识别完成后通过MQTT上传相关数据信息。

项目设计思路
MAX78000FTHR为快速开发平台,器件集成了卷积神经网络加速器,故本次采用了人脸识别方案,同时设计了一款人脸识别底板,提供了屏幕、WIFI、光源、电池电源等。
内容部分分为四章:分别是MAX78000 训练环境搭建 ——基于阿里云、MAX78000 人脸识别开发、MAX78000配置ESP8266连接阿里云、MAX78000人脸识别界面搭建
MAX78000 训练环境搭建 ——基于阿里云
阿里云服务器购买
首先登陆阿里云 https://cn.aliyun.com/ ,这里我们选择云服务器ECS购买,
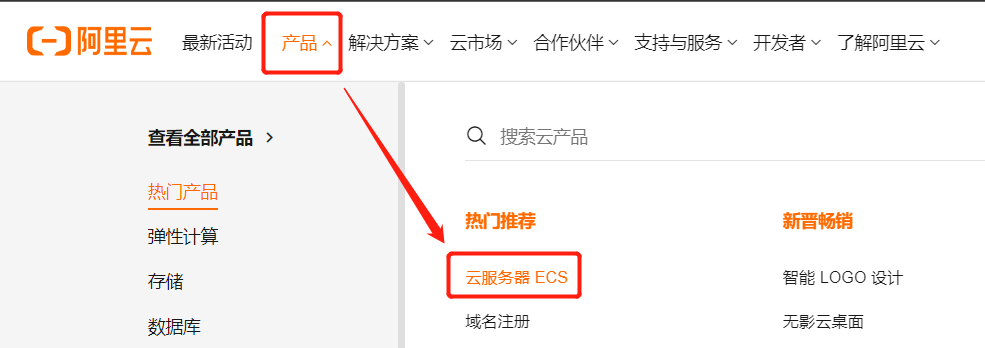
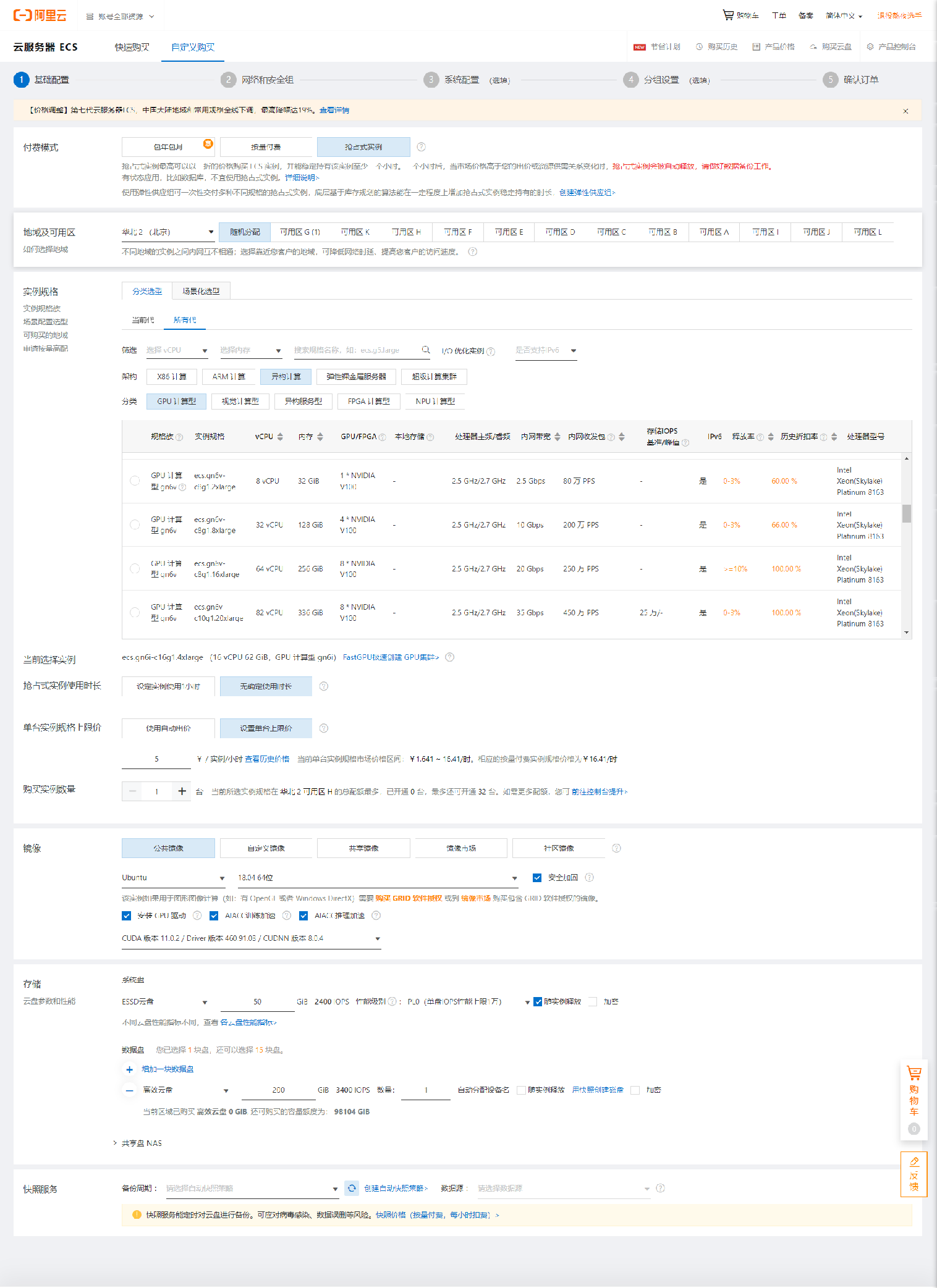
然后是进行云服务器的相关基础配置,为了能够训练MAX78000的Faceid,我这里选用的内存为62G,系统选用了乌班图,并且进行了GPU驱动等安装,同时我还选用了一块200G的云盘作为数据盘,用来存储深度学习需要的数据集等,其他请见图:
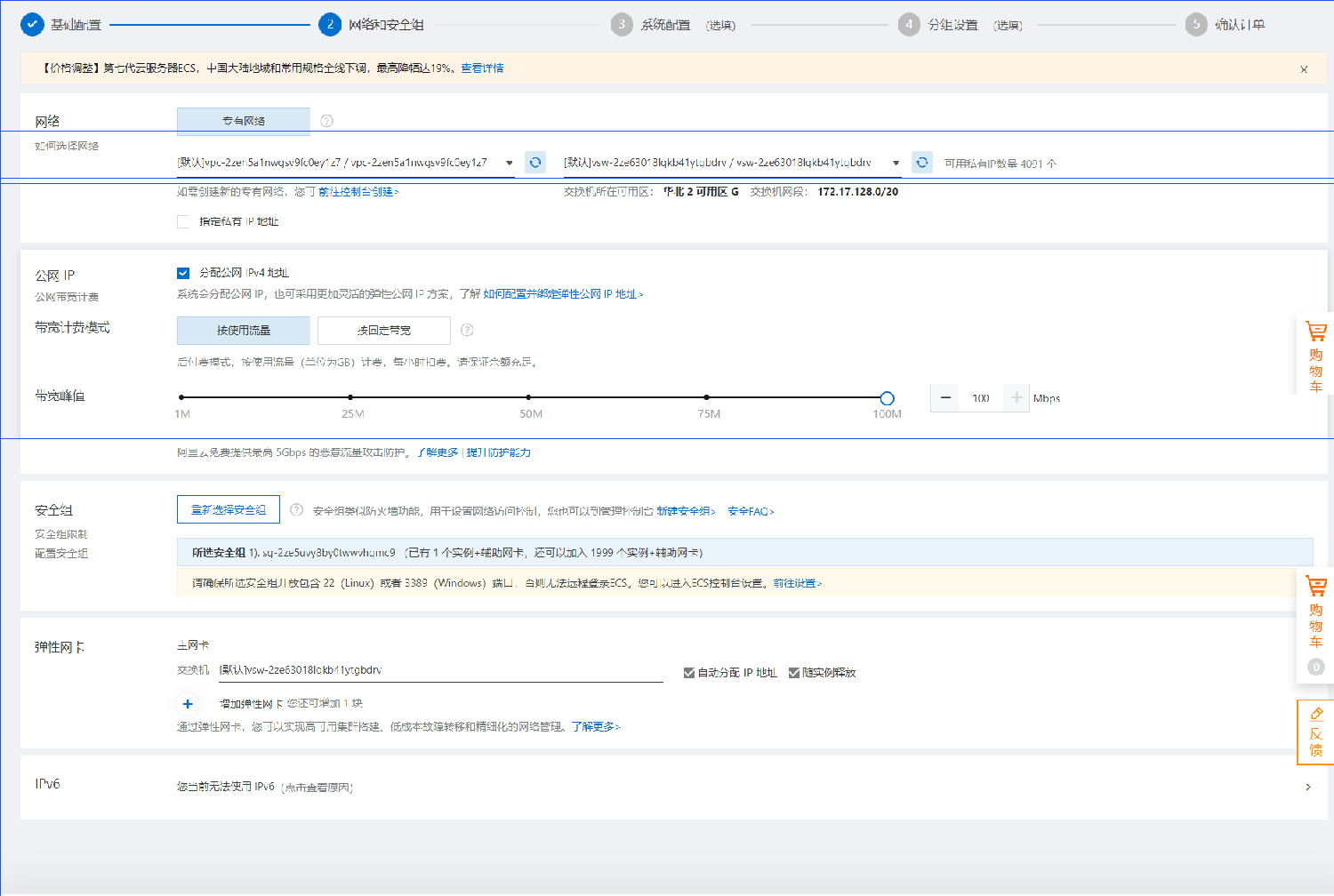
网络和安全组方面,带宽我选用的按量付费,因此将带宽峰值直接拉满即可。
最后两项就自行设置即可,然后确认订单即可,注意将管理员的密码进行设置。
开发环境部署
服务器购买完成后,我们使用Mobaxterm软件进行连接,首先我们需要在阿里云的控制台界面中复制公网IP,然后复制到软件中,输入用户名后连接即可。
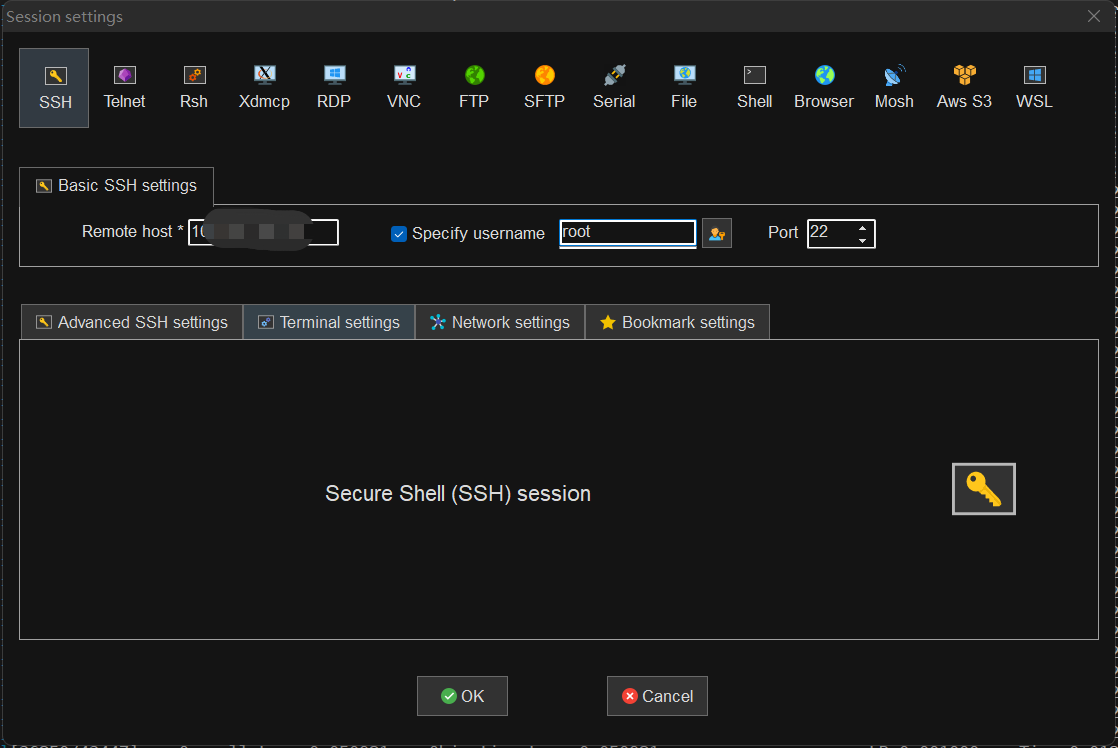
连接成功后,系统会自动进行CUDA环境的配置,等待配置完成后会自动重启,即刻使用。
我们可以通过nvidia-smi命令来查看系统的CUDA版本
下一步是安装Conda,使用命令wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh获取Conda安装包:
root@iZ2ze2x0qiesbdiall1idmZ:~# wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
--2022-10-20 20:15:29-- https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
Resolving repo.anaconda.com (repo.anaconda.com)... 104.16.131.3, 104.16.130.3, 2606:4700::6810:8303, ...
Connecting to repo.anaconda.com (repo.anaconda.com)|104.16.131.3|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 576830621 (550M) [application/x-sh]
Saving to: ‘Anaconda3-2020.07-Linux-x86_64.sh’
Anaconda3-2020.07-Linux-x86_64.sh 100%[=============================================================================>] 550.11M 13.0MB/s in 47s
2022-10-20 20:16:17 (11.7 MB/s) - ‘Anaconda3-2020.07-Linux-x86_64.sh’ saved [576830621/576830621]下载完成之后,使用bash Anaconda3-2020.07-Linux-x86_64.sh进行Conda安装,一路yes即可,安装完成后需要重启,使用reboot命令进行重启:
root@iZ2ze2x0qiesbdiall1idmZ:~# bash Anaconda3-2020.07-Linux-x86_64.sh
Welcome to Anaconda3 2020.07
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
>>>
===================================
End User License Agreement - Anaconda Individual Edition
===================================
······
Please answer 'yes' or 'no':'
>>> yes
Unpacking payload ...
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
······
by running conda init? [yes|no]
[no] >>> yes
no change /root/anaconda3/condabin/conda
no change /root/anaconda3/bin/conda[注,bash Anaconda3-2020.07-Linux-x86_64.sh命令可能会因下载的文件不同而不同, 重启后(base)root@iZ2ze5ng9w6gdo4zgqhx3oZ:~#可以看到命令行前面有了base]
接下来我们创建max78000的训练环境,使用命令conda create --name max78000 python=3.8,这里的意思是创建一个python版本为3.8的max78000环境。
MAX78000训练源码拉取
下一步需要安装git,使用sudo apt-get install git命令进行安装,安装完成后我们创建max78000的文件夹进行max78000相关的文件的下载。
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~# sudo apt-get install git
Reading package lists... Done
······
Processing triggers for libc-bin (2.27-3ubuntu1.6) ...
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~# mkdir max78000
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~# ls
anaconda3 Anaconda3-2020.07-Linux-x86_64.sh auto_install max78000 NVIDIA_CUDA-11.0_Samples
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~# cd max8000
-bash: cd: max8000: No such file or directory
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~# cd max78000
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000# git clone --recursive https://github.com/MaximIntegratedAI/ai8x-training.git
Cloning into 'ai8x-training'...
······
Submodule path 'distiller': checked out '94b0857bfc5c455991ee84fc0195fc1079366df1'然后使用以下两条命令拉取max78000训练代码:
git clone --recursive https://github.com/MaximIntegratedAI/ai8x-training.git
git clone --recursive https://github.com/MaximIntegratedAI/ai8x-synthesis.git激活环境
激活我们之间创建的max78000环境,并进入ai8x-training/文件夹进行相关库的安装:
(base) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000# conda activate max78000
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000#cd ai8x-training/使用nvidia-smi再次确定CUDA Version:
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# nvidia-smi
Thu Oct 20 20:55:33 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:07.0 Off | 0 |
| N/A 32C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
开始安装相关库,对于 Linux 上的 CUDA 11.x:
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# pip3 install -r requirements-cu11.txt
······
Successfully installed MarkupSafe-2.1.1 Pillow-9.2.0 PyYAML-6.0 Send2Trash-1.8.0 absl-py-1.2.0 appdirs-1.4.4
argon2-cffi-21.3.0 argon2-cffi-bindings-21.2.0 asttokens-2.0.8 atomicwrites-1.4.1 attrs-22.1.0 audioread-3.0.0
backcall-0.2.0 beautifulsoup4-4.11.1 bleach-5.0.1 bqplot-0.11.5 cachetools-5.2.0 cffi-1.15.1 charset-normalizer-2.1.1
cloudpickle-2.2.0 contourpy-1.0.5 cycler-0.11.0 debugpy-1.6.3 decorator-5.1.1 defusedxml-0.7.1 distiller-0.4.0rc0
entrypoints-0.4 executing-1.1.0 fastjsonschema-2.16.2 fonttools-4.37.4 google-auth-2.12.0 google-auth-oauthlib-0.4.6
graphviz-0.10.1 grpcio-1.49.1 gym-0.12.5 h5py-3.7.0 idna-3.4 importlib-metadata-5.0.0 importlib-resources-5.10.0
ipykernel-6.16.0 ipython-8.5.0 ipython-genutils-0.2.0 ipywidgets-7.4.2 jedi-0.18.1 jinja2-3.1.2 joblib-1.2.0
jsonpatch-1.32 jsonpointer-2.3 jsonschema-4.16.0 jupyter-1.0.0 jupyter-client-7.3.5 jupyter-console-6.4.4 jupyter-core-4.11.1
jupyterlab-pygments-0.2.2 kiwisolver-1.4.4 librosa-0.9.2 llvmlite-0.32.1 markdown-3.4.1 matplotlib-3.6.0 matplotlib-inline-0.1.6
mistune-2.0.4 more-itertools-8.14.0 munch-2.5.0 nbclient-0.7.0 nbconvert-7.2.1 nbformat-5.6.1 nest-asyncio-1.5.6 networkx-2.8.7
notebook-6.4.12 numba-0.49.1 numpy-1.22.4 oauthlib-3.2.1 opencv-python-4.6.0.66 packaging-21.3 pandas-1.5.0 pandocfilters-1.5.0
parso-0.8.3 pexpect-4.8.0 pickleshare-0.7.5 pkgutil-resolve-name-1.3.10 pluggy-0.13.1 pooch-1.6.0 pretrainedmodels-0.7.4 prometheus-client-0.14.1
prompt-toolkit-3.0.31 protobuf-3.20.3 psutil-5.9.2 ptyprocess-0.7.0 pure-eval-0.2.2 py-1.11.0 pyasn1-0.4.8 pyasn1-modules-0.2.8 pycparser-2.21
pydot-1.4.1 pyglet-1.5.27 pygments-2.13.0 pyparsing-3.0.9 pyrsistent-0.18.1 pytest-4.6.11 python-dateutil-2.8.2 pytsmod-0.3.5 pytz-2022.4 pyzmq-24.0.1
qgrid-1.1.1 qtconsole-5.3.2 qtpy-2.2.1 requests-2.28.1 requests-oauthlib-1.3.1 resampy-0.3.1 rsa-4.9 scikit-learn-0.23.2 scipy-1.9.1 shap-0.41.0
six-1.16.0 slicer-0.0.7 soundfile-0.10.3.post1 soupsieve-2.3.2.post1 stack-data-0.5.1 tabulate-0.8.3 tensorboard-2.9.0 tensorboard-data-server-0.6.1
tensorboard-plugin-wit-1.8.1 terminado-0.16.0 threadpoolctl-3.1.0 tinycss2-1.1.1 tk-0.1.0 torch-1.8.1+cu111 torchaudio-0.8.1 torchnet-0.0.4
torchvision-0.9.1+cu111 tornado-6.2 tqdm-4.33.0 traitlets-5.4.0 traittypes-0.2.1 typing-extensions-4.4.0 urllib3-1.26.12 visdom-0.2.1 wcwidth-0.2.5
webencodings-0.5.1 websocket-client-1.4.1 werkzeug-2.2.2 widgetsnbextension-3.4.2 xlsxwriter-3.0.3 zipp-3.8.1如上,成功安装即可。
对于所有其他系统,包括 Linux 上的 CUDA 10.2:
$ pip3 install -r requirements.txt模型训练
进入工程目录,并验证环境:
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# ./check_cuda.py
System: linux
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0]
PyTorch version: 1.8.1+cu111
CUDA acceleration: available in PyTorch直接开始训练一个已有的示例:
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# ./check_cuda.py
System: linux
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0]
PyTorch version: 1.8.1+cu111
CUDA acceleration: available in PyTorch
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# scripts/train_mnist.sh
Traceback (most recent call last):
File "/root/anaconda3/envs/max78000/lib/python3.8/pydoc.py", line 343, in safeimport
···
File "/root/anaconda3/envs/max78000/lib/python3.8/site-packages/soundfile.py", line 142, in <module>
raise OSError('sndfile library not found')
OSError: sndfile library not found
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "train.py", line 1704, in <module>
main()
File "train.py", line 164, in main
···
File "/root/anaconda3/envs/max78000/lib/python3.8/pydoc.py", line 358, in safeimport
raise ErrorDuringImport(path, sys.exc_info())
pydoc.ErrorDuringImport: problem in datasets.kws20 - OSError: sndfile library not found可以看到是缺少相关包的,使用apt install libsndfile1安装缺少的包:
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# apt install libsndfile1
Reading package lists... Done
······
Processing triggers for libc-bin (2.27-3ubuntu1.6) ...再次开始进行训练,可以看到开始正常下载训练所需的内容,并在下载完成后开始进行训练
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# scripts/train_mnist.sh
Configuring device: MAX78000, simulate=False.
Log file for this run: /root/max78000/ai8x-training/logs/2022.10.20-210706/2022.10.20-210706.log
{'start_epoch': 10, 'weight_bits': 8}
Optimizer Type: <class 'torch.optim.sgd.SGD'>
Optimizer Args: {'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0.0001, 'nesterov': False}
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
9913344it [00:01, 6348602.97it/s]
·······
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/MNIST/raw
Processing...
The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:143.)
Done!
Dataset sizes:
training=54000
validation=6000
test=10000
Reading compression schedule from: policies/schedule.yaml
Training epoch: 54000 samples (256 per mini-batch)
Epoch: [0][ 10/ 211] Overall Loss 2.298436 Objective Loss 2.298436 LR 0.100000 Time 0.114328
Epoch: [0][ 20/ 211] Overall Loss 2.268061 Objective Loss 2.268061 LR 0.100000 Time 0.071585
Epoch: [0][ 30/ 211] Overall Loss 2.199158 Objective Loss 2.199158 LR 0.100000 Time 0.059231
Epoch: [0][ 40/ 211] Overall Loss 2.096795 Objective Loss 2.096795 LR 0.100000 Time 0.036362
Epoch: [0][ 210/ 211] Overall Loss 0.891322 Objective Loss 0.891322 Top1 88.671875 Top5 99.609375 LR 0.100000 Time 0.035842
Epoch: [0][ 211/ 211] Overall Loss 0.888976 Objective Loss 0.888976 Top1 87.903226 Top5 99.395161 LR 0.100000 Time 0.035764
--- validate (epoch=0)-----------
6000 samples (256 per mini-batch)
Epoch: [0][ 10/ 24] Loss 0.281747 Top1 91.679688 Top5 99.648438
Epoch: [0][ 20/ 24] Loss 0.285032 Top1 91.601562 Top5 99.628906
Epoch: [0][ 24/ 24] Loss 0.285772 Top1 91.533333 Top5 99.650000
==> Top1: 91.533 Top5: 99.650 Loss: 0.286
==> Confusion:
[[565 0 5 4 1 4 5 1 14 6]
[ 0 673 5 1 2 1 4 1 1 0]
[ 1 3 509 20 6 3 5 11 21 7]
[ 2 1 10 544 1 6 1 3 11 4]
[ 2 4 2 1 516 3 7 9 1 20]
[ 0 2 3 9 3 434 16 2 31 18]
[ 6 2 1 0 5 2 601 0 14 0]
[ 0 8 16 9 3 5 0 559 2 23]
[ 2 3 1 1 6 3 14 1 539 14]
[ 4 8 6 7 21 5 0 5 7 552]]
==> Best [Top1: 91.533 Top5: 99.650 Sparsity:0.00 Params: 71148 on epoch: 0]
Saving checkpoint to: logs/2022.10.20-210706/checkpoint.pth.tar
[ 1 0 0 0 4 0 0 1 0 1003]]
Log file for this run: /root/max78000/ai8x-training/logs/2022.10.20-210706/2022.10.20-210706.log至此,使用阿里云服务器训练max78000的模型就完成了。
模型量化
模型训练完后,生成的模型文件保存在ai8x-training/logs下:
量化有两种主要方法——量化感知训练和训练后量化。MAX78000 支持这两种方法,具体量化原理我们后面介绍,这里先介绍量化过程。
对于这两种方法,quantize.py软件都会量化现有的 PyTorch checkpoint文件并写出一个新的 PyTorch checkpoint文件,然后可以使用与训练相同的 PyTorch 框架来评估量化网络的质量。
将上述文件移动到ai8x-synthesis/proj文件夹,准备量化。
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# sudo cp /root/max78000/ai8x-training/logs/2022.10.20-210706/2022.10.20-210706.log /root/max78000/ai8x-synthesis/proj
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# ./quantize.py proj/qat_best.pth.tar proj/proj_q8.pth.tar --device MAX78000量化感知训练是性能更好的方法。它默认启用。QAT 在训练期间学习有助于量化的其他参数。需要quantize.py.的输入 checkpoint,要么是qat_best.pth.tar,最好的 QAT 时期的 checkpoint,要么是qat_checkpoint.pth.tar,最终的 QAT 时期的 checkpoint。
评估量化后的模型:注意要改.sh文件的路径,或移动量化模型到指定路径。
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# cd ../ai8x-training
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# scripts/evaluate_mnist.sh模型转换
网络加载器创建用于编程 MAX78000 的 C 代码(用于嵌入式执行或 RTL 仿真)。此外,生成的代码包含样本输入数据和样本的预期输出,以及验证预期输出的代码。
该ai8xize.py程序需要三个输入,使用--help获取完整的命令列表:
-
由 MAX78000模型量化程序生成的量化检查点文件
quantize.py。 -
网络的 YAML 描述,请参阅 。
-
.npy包含样本输入数据的 NumPy “pickle”文件。
默认情况下,C 代码分为两个文件:main.c包含包装器代码,加载示例输入并验证示例输入的输出。cnn.c包含为特定网络生成的用于加载、配置和运行加速器的函数。在开发过程中,这种拆分可以更轻松地仅交换网络,同时保持自定义包装器代码的完整性。
配置文件位于ai8x-synthesis/networks文件夹下:
---
# CHW (big data) configuration for FashionMNIST
arch: ai84net5
dataset: FashionMNIST
# Define layer parameters in order of the layer sequence
layers:
- pad: 1
activate: ReLU
out_offset: 0x2000
processors: 0x0000000000000001
data_format: CHW
op: conv2d
- max_pool: 2
pool_stride: 2
pad: 2
activate: ReLU
out_offset: 0
processors: 0xfffffffffffffff0
op: conv2d
- max_pool: 2
pool_stride: 2
pad: 1
activate: ReLU
out_offset: 0x2000
processors: 0xfffffffffffffff0
op: conv2d
- avg_pool: 2
pool_stride: 2
pad: 1
activate: ReLU
out_offset: 0
processors: 0x0ffffffffffffff0
op: conv2d要在demos/ai85-mnist/文件夹中生成嵌入式 MAX78000 示例c代码,执行以下命令行:
(max78000) root@iZ2ze5ng9w6gdo4zgqhx3oZ:~/max78000/ai8x-training# ./ai8xize.py --verbose --test-dir demos --prefix ai85-mnist --checkpoint-filetrained/ai85-mnist.pth.tar --config-filenetworks/mnist-chw -ai85.yaml --device MAX78000 --compact-data --mexpress --softmax接着就可以进行开发板部署了。
常用命令
-
磁盤挂載
mount /dev/vdb1 /sd2
-
训练命令
./scripts/train_faceid.sh --data /sd/pkl/
-
编辑训练批次
vim ./scripts/train_faceid.sh
-
数据训练
./scripts/train_faceid.sh --data /sd/pkl/
-
vim显示行号
:set nu
常见问题
sudo apt-get install xxx出现错误
(base) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# sudo apt-get install -y make build-essential libssl-dev zlib1g-dev \
> libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
> libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev \
> libsndfile-dev portaudio19-dev
Reading package lists... Done
Building dependency tree
Reading state information... Done
Note, selecting 'libsndfile1-dev' instead of 'libsndfile-dev'
build-essential is already the newest version (12.4ubuntu1).
make is already the newest version (4.1-9.1ubuntu1).
make set to manually installed.
wget is already the newest version (1.19.4-1ubuntu2.2).
xz-utils is already the newest version (5.2.2-1.3ubuntu0.1).
xz-utils set to manually installed.
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
tk-dev : Depends: tk8.6-dev (>= 8.6.0-2) but it is not going to be installed
E: Unable to correct problems, you have held broken packages.参考文献
MAX78000 人脸识别开发
阅读本章节之前建议完成MAX78000阿里云环境搭建章节。
1.理论分析
1.1 问题分析
人脸识别问题的解决分为三个主要步骤:
-
人脸提取:检测图像中的人脸以提取仅包含一张人脸的矩形子图像。
-
人脸对齐:确定子图像中人脸的旋转角度(3D)以通过仿射变换补偿其效果。
-
人脸识别:使用提取和对齐的子图像识别人。
前两个步骤有不同的方法。多任务级联卷积神经网络 (MTCNN)解决了人脸检测和对齐步骤。人脸识别一般作为一个不同的问题来研究,这是本次测试开发的重点。MAX78000 评估板用于识别未裁剪的人脸,每个人脸仅包含一张人脸。
1.2 方法原理:FaceNet
我们采用基于相似度的方法学习每个面部图像的embedding,其与参考图像的嵌入计算相似度距离。期望观察到同一个人的面部嵌入向量之间的距离小而不同人的面部
之间的距离小而不同人的面部之间的距离大。FaceNet是为基于嵌入的人脸识别方法开发的最流行的 CNN 的模型之一。
三Triplet Loss是其成功背后的关键。该损失函数采用三个输入样本:锚点、来自与锚点相同身份的正样本和来自不同身份的负样本。当锚点的距离接近正样本而远离负样本时,Triplet Loss函数给出较低的值。
1.3 方法进阶:知识蒸馏网络
FaceNet的模型有约750万个参数,对于MAX78000来说太大了。它还需要 1.6G 浮点运算,这使得该模型很难在许多移动或物联网设备上运行。因此,需要设计一种新的模型架构,其参数少于 450k,以适应 MAX78000。因此知识蒸馏是一种很好的解决方法。 采用知识蒸馏方法从 FaceNet 开发更小的 CNN 模型,这也是 FaceNet 用于应用程序广受赞赏的原因。
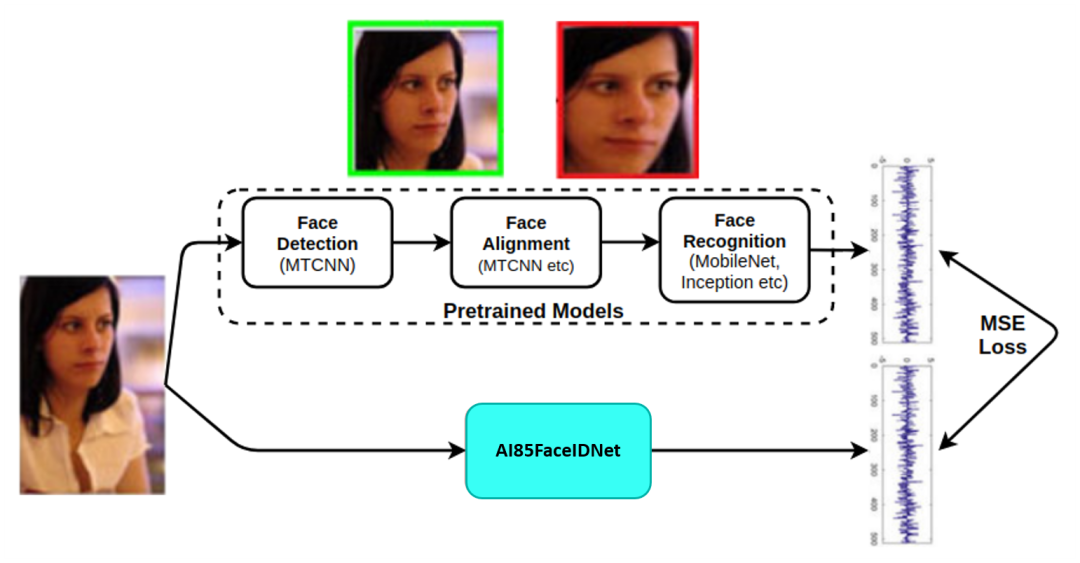
如上图所示,将知识从大型模型转移到较小模型的过程。大模型比小模型具有更高的知识容量。然而,容量可能没有得到充分利用。因此,这里的目的是向较小的网络教授大网络的确切行为。
2 .模型训练
2.1数据集和预处理
这里使用VGGFace-2作为模型训练的数据集,包含331万图片,9131个ID,平均图片个数为362.6。
VGGFace-2:大规模人脸识别数据集。下载:https://aistudio.baidu.com/aistudio/datasetdetail/13135
此处目录建议在阿里云购买的200G云盘中进行,此处我的云盘挂载在\sd文件夹中。
Linux下载文件可以使用wget命令,首先在windows系统中使用谷歌浏览器获取数据集连接,然后在\sd文件夹中进行下载即可;下载完成后我们解压文件,
root@iZ2ze9gdjnlb2cwpcldexpZ:/sd# ls
vggface2_test.zip vggface2_train.zip
root@iZ2ze9gdjnlb2cwpcldexpZ:/sd# unzip vggface2_train.zip
root@iZ2ze9gdjnlb2cwpcldexpZ:/sd# unzip vggface2_test.zip
root@iZ2ze9gdjnlb2cwpcldexpZ:/sd# ls
vggface2_test vggface2_train vggface2_test.zip vggface2_train.zip
训练数据集的生成和增强处理,<path_to_vggface2_dataset_folder>参数为数据集的文件夹,<path_to_store_generated_dataset>为生成.npy文件存储位置。
python gen_vggface2_embeddings.py -r <path_to_vggface2_dataset_folder> -d <path_to_store_generated_dataset> --type <train/test>填充完目录后即可执行训练集和验证集的生成:
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# python gen_vggface2_embeddings.py -r /sd/vggface2_train -d /sd/vggface2/embeddings --type train
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# python gen_vggface2_embeddings.py -r /sd/vggface2_test -d /sd/vggface2/embeddings --type test此处非常容易出现各种报错,一般是显卡缓存不足导致的,通常出现在10系列显卡上,使用阿里云环境不会出现此问题。
生成后进行增强,<path_to_store_generated_dataset>为上一步的生成文件夹。
python merge_vggface2_dataset.py -p <path_to_store_generated_dataset> --type <train/test>命令如下:
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# python merge_vggface2_dataset.py -r /sd/vggface2/embeddings --type train
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# python merge_vggface2_dataset.py -r /sd/vggface2/embeddings --type test 最后生成文件进行移动,结构如下:
└── VGGFace-2
├── test
│ ├── whole_set_00.pkl
│ └── whole_set_01.pkl
└── train
├── whole_set_00.pkl
├── whole_set_01.pkl
├── whole_set_02.pkl
└── whole_set_03.pkl2.2 模型训练
生成相应的pkl文件后即可开始进行训练,需要使用的网络已经由MAX78000提供,这里不再赘述。
因为我们的数据集存放位置与官方的不一致,因此我们需要指定数据集的位置,使用--data指出:
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-training# ./scripts/train_faceid.sh --data /sd/
Configuring device: MAX78000, simulate=False.
Log file for this run: /root/max78000/ai8x-training/logs/2022.10.21-112949/2022.10.21-112949.log
{'start_epoch': 10, 'weight_bits': 8}
Optimizer Type: <class 'torch.optim.adam.Adam'>
Optimizer Args: {'lr': 0.001, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0.0, 'amsgrad': False}
Data loading...
48274 of data samples loaded in 30.6428 seconds.
Data loading...
26981 of data samples loaded in 15.5877 seconds.
---------------------load data----------------------
Dataset sizes:
training=43447
validation=4827
test=26981
Reading compression schedule from: policies/schedule-faceid.yaml
此处可能会出现如下报错,张量不匹配等等:
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-training# ./scripts/train_faceid.sh --data /sd/
Configuring device: MAX78000, simulate=False.
Log file for this run: /root/max78000/ai8x-training/logs/2022.10.21-112709/2022.10.21-112709.log
{'start_epoch': 10, 'weight_bits': 8}
Optimizer Type: <class 'torch.optim.adam.Adam'>
Optimizer Args: {'lr': 0.001, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0.0, 'amsgrad': False}
Data loading...
48274 of data samples loaded in 30.5351 seconds.
Data loading...
26981 of data samples loaded in 15.5358 seconds.
---------------------load data----------------------
Dataset sizes:
training=43447
validation=4827
test=26981
Reading compression schedule from: policies/schedule-faceid.yaml
Training epoch: 43447 samples (100 per mini-batch)
Epoch: [0][ 250/ 435] Overall Loss 0.053484 Objective Loss 0.053484 LR 0.001000 Time 0.065158
Epoch: [0][ 435/ 435] Overall Loss 0.053024 Objective Loss 0.053024 MSE 0.053965 LR 0.001000 Time 0.061565
--- validate (epoch=0)-----------
Log file for this run: /root/max78000/ai8x-training/logs/2022.10.21-112709/2022.10.21-112709.log
Traceback (most recent call last):
File "train.py", line 1705, in <module>
main()
File "train.py", line 543, in main
top1, top5, vloss, mAP = validate(val_loader, model, criterion, [pylogger],
File "train.py", line 898, in validate
return _validate(val_loader, model, criterion, loggers, args, epoch, tflogger)
File "train.py", line 1112, in _validate
classerr.add(output.data.permute(0, 2, 3, 1).flatten(start_dim=0,
File "/root/anaconda3/envs/max78000/lib/python3.8/site-packages/torchnet/meter/msemeter.py", line 21, in add
self.sesum += torch.sum((output - target) ** 2)
RuntimeError: The size of tensor a (512) must match the size of tensor b (51200) at non-singleton dimension 1修改方法为将train.py的779行 and 1111行的classerr.add(output.data.permute(0, 2, 3,1).flatten(start_dim=0,end_dim=2),target.flatten())改为classerr.add(output.data, target),即可开始进行训练。
3. 模型量化与评估
3.1 模型量化
首先将训练出的/qat_best.pth.tar模型复制到ai8x-synthesis\proj文件夹中,然后进入ai8x-synthesis目录,执行以下命令即可:
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# python ./quantize.py proj/qat_best.pth.tar proj/qat_best-ai8x-q.pth.tar --device MAX78000 -v -c networks/faceid.yaml
Configuring device: MAX78000
Reading networks/faceid.yaml to configure network...
Converting checkpoint file proj/qat_best.pth.tar to proj/qat_best-ai8x-q.pth.tar
Model keys (state_dict):
conv1.output_shift, conv1.weight_bits, conv1.bias_bits, conv1.quantize_activation, conv1.adjust_output_shift, conv1.shift_quantile, conv1.op.weight, conv2.output_shift, conv2.weight_bits, conv2.bias_bits, conv2.quantize_activation, conv2.adjust_output_shift, conv2.shift_quantile, conv2.op.weight, conv3.output_shift, conv3.weight_bits, conv3.bias_bits, conv3.quantize_activation, conv3.adjust_output_shift, conv3.shift_quantile, conv3.op.weight, conv4.output_shift, conv4.weight_bits, conv4.bias_bits, conv4.quantize_activation, conv4.adjust_output_shift, conv4.shift_quantile, conv4.op.weight, conv5.output_shift, conv5.weight_bits, conv5.bias_bits, conv5.quantize_activation, conv5.adjust_output_shift, conv5.shift_quantile, conv5.op.weight, conv6.output_shift, conv6.weight_bits, conv6.bias_bits, conv6.quantize_activation, conv6.adjust_output_shift, conv6.shift_quantile, conv6.op.weight, conv7.output_shift, conv7.weight_bits, conv7.bias_bits, conv7.quantize_activation, conv7.adjust_output_shift, conv7.shift_quantile, conv7.op.weight, conv8.output_shift, conv8.weight_bits, conv8.bias_bits, conv8.quantize_activation, conv8.adjust_output_shift, conv8.shift_quantile, conv8.op.weight, avgpool.output_shift, avgpool.weight_bits, avgpool.bias_bits, avgpool.quantize_activation, avgpool.adjust_output_shift, avgpool.shift_quantile
conv1.op.weight avg_max: 0.23429993 max: 0.2981393 mean: -0.0012111976 factor: [256.] bits: 8
conv2.op.weight avg_max: 0.29567257 max: 0.49292472 mean: -0.013966456 factor: [256.] bits: 8
conv3.op.weight avg_max: 0.3058117 max: 0.5719163 mean: -0.0075516785 factor: [128.] bits: 8
conv4.op.weight avg_max: 0.2525767 max: 0.50934964 mean: -0.015919587 factor: [128.] bits: 8
conv5.op.weight avg_max: 0.24346802 max: 0.5357917 mean: -0.0096125575 factor: [128.] bits: 8
conv6.op.weight avg_max: 0.3251059 max: 0.5835651 mean: -0.010212447 factor: [128.] bits: 8
conv7.op.weight avg_max: 0.29670662 max: 0.59505373 mean: -0.010930746 factor: [128.] bits: 8
conv8.op.weight avg_max: 0.3084465 max: 0.68859434 mean: 0.00021292236 factor: [128.] bits: 8模型评估
由于我们使用的损失函数是均方差,因此,L2(欧几里得)范数被选为该分析中嵌入之间的距离。提取所有类的嵌入与给定图像的嵌入的平均距离以确定距离最近的类别。然后,该算法返回嵌入平均最接近给定嵌入的类别。
对于未知对象的识别,基于相似度的测量方法需要确定一个阈值,默认使用 ROC曲线 (Receiver Operating Characteristic)来确定。ROC 曲线是通过在不同阈值下绘制真阳性 (TP) 率与假阳性 (FP) 率来创建的。因此,当它在 ROC 曲线上移动时,阈值设置会发生变化,并且可以根据所选性能确定阈值。
此处多注意参数即可,尤其主要需要指定--data,即数据集的位置:
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-training# python ./train.py --model ai85faceidnet --dataset FaceID --data /sd/ --regression --evaluate --exp-load-weights-from ../ai8x-synthesis/proj/qat_best-ai8x-q.pth.tar -8 --device MAX78000
Configuring device: MAX78000, simulate=True.
Log file for this run: /root/max78000/ai8x-training/logs/2022.10.21-151850/2022.10.21-151850.log
{'start_epoch': 10, 'weight_bits': 8}
=> loading checkpoint ../ai8x-synthesis/proj/qat_best-ai8x-q.pth.tar
=> Checkpoint contents:
+----------------------+-------------+---------------+
| Key | Type | Value |
|----------------------+-------------+---------------|
| arch | str | ai85faceidnet |
| compression_sched | dict | |
| epoch | int | 10 |
| extras | dict | |
| optimizer_state_dict | dict | |
| optimizer_type | type | Adam |
| state_dict | OrderedDict | |
+----------------------+-------------+---------------+
=> Checkpoint['extras'] contents:
+-----------------+--------+---------------+
| Key | Type | Value |
|-----------------+--------+---------------|
| best_epoch | int | 10 |
| best_mAP | int | 0 |
| best_top1 | Tensor | |
| clipping_method | str | MAX_BIT_SHIFT |
| current_mAP | int | 0 |
| current_top1 | Tensor | |
+-----------------+--------+---------------+
Loaded compression schedule from checkpoint (epoch 10)
=> loaded 'state_dict' from checkpoint '../ai8x-synthesis/proj/qat_best-ai8x-q.pth.tar'
Optimizer Type: <class 'torch.optim.sgd.SGD'>
Optimizer Args: {'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0.0001, 'nesterov': False}
Data loading...
48274 of data samples loaded in 30.7844 seconds.
Data loading...
---------------------load data----------------------
Dataset sizes:
training=43447
validation=4827
test=26981
--- test ---------------------
26981 samples (256 per mini-batch)
Test: [ 10/ 106] Loss 0.036438 MSE 0.036438
Test: [ 20/ 106] Loss 0.036864 MSE 0.036864
Test: [ 30/ 106] Loss 0.036845 MSE 0.036845
Test: [ 40/ 106] Loss 0.036945 MSE 0.036945
Test: [ 50/ 106] Loss 0.037197 MSE 0.037197
Test: [ 60/ 106] Loss 0.037189 MSE 0.037189
Test: [ 70/ 106] Loss 0.037266 MSE 0.037266
Test: [ 80/ 106] Loss 0.037311 MSE 0.037311
Test: [ 90/ 106] Loss 0.037277 MSE 0.037277
Test: [ 100/ 106] Loss 0.037256 MSE 0.037256
Test: [ 106/ 106] Loss 0.037298 MSE 0.037290
==> MSE: 0.03729 Loss: 0.0374. 模型部署
4.1 模型转换
使用Maxim工具中的python脚本为MAX78000获得量化模型后,需转换成适合模型部署的c代码,包括初始化 CNN 加速器、加载量化的 CNN 权重、运行给定示例输入样本的模型以及在准备好这三项后从设备获取模型输出的函数。
运行以下脚本进行模型转换,其中--test-dir需指定pkl文件的文件夹,--checkpoint-file为量化之后的模型位置,转换后的模型在\sd文件夹中
(max78000) root@iZ2ze9gdjnlb2cwpcldexpZ:~/max78000/ai8x-synthesis# python ./ai8xize.py -e --verbose --top-level cnn -L --test-dir /sd/ --prefix faceid --checkpoint-file ./proj/qat_best-ai8x-q.pth.tar --config-file networks/faceid.yaml --device MAX78000 --fifo --compact-data --mexpress --display-checkpoint --unload
Configuring device: MAX78000
Reading networks/faceid.yaml to configure network...
Reading ./proj/qat_best-ai8x-q.pth.tar to configure network weights...
Checkpoint for epoch 10, model ai85faceidnet - weight and bias data:
InCh OutCh Weights Quant Shift Min Max Size Key Bias Quant Min Max Size Key
3 16 (48, 3, 3) 8 -1 -73 76 432 conv1.op.weight N/A 0 0 0 0 N/A
16 32 (512, 3, 3) 8 -1 -126 101 4608 conv2.op.weight N/A 0 0 0 0 N/A
32 32 (1024, 3, 3) 8 0 -73 35 9216 conv3.op.weight N/A 0 0 0 0 N/A
32 64 (2048, 3, 3) 8 0 -65 38 18432 conv4.op.weight N/A 0 0 0 0 N/A
64 64 (4096, 3, 3) 8 0 -69 60 36864 conv5.op.weight N/A 0 0 0 0 N/A
64 64 (4096, 3, 3) 8 0 -75 58 36864 conv6.op.weight N/A 0 0 0 0 N/A
64 64 (4096, 3, 3) 8 0 -76 58 36864 conv7.op.weight N/A 0 0 0 0 N/A
64 512 (32768, 1, 1) 8 0 -88 83 32768 conv8.op.weight N/A 0 0 0 0 N/A
TOTAL: 8 parameter layers, 176,048 parameters, 176,048 bytes
Configuring data set: FaceID.
faceid...
Arranging weights... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100%
Storing weights... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100%
Creating network... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100%文件的目录结构如下
(base) root@iZ2ze9gdjnlb2cwpcldexpZ:/sd# tree
.
├── faceid
│ ├── cnn.c
│ ├── cnn.h
│ ├── faceid.launch
│ ├── log.txt
│ ├── main.c
│ ├── Makefile
│ ├── sampledata.h
│ ├── sampleoutput.h
│ ├── softmax.c
│ └── weights.h
└── VGGFace-2
├── test
│ ├── whole_set_00.pkl
│ └── whole_set_01.pkl
└── train
├── whole_set_00.pkl
├── whole_set_01.pkl
├── whole_set_02.pkl
└── whole_set_03.pkl生成的代码仅包含了模型相关部分,要实现完整的人脸识别功能,我们还需要做一些额外的工作,比如外设。这部分示例faceid_evkit下已经提供,只需将src替换即可。
4.2 制作测试用例
接下来可以自己制作一些测试用例,用以下姿势各拍一张,共6-8张:
a) 直接面对相机(1张)
b) 脸向右、左、上、下略微倾斜(5-10度),但仍注视着相机(4张)
c) 将人脸直接缩小到相机覆盖约 20-30% 的区域(1 张图片):
d)如果需要,可以添加额外的 1-2 张照片,其中一些面部表情(例如微笑)直接面对相机。
e)注意任意名称以 .jpg 格式保存图片。
导航到“db”文件夹并为数据库中的每个类创建一个文件夹,并将每个类的照片复制到这些文件夹中。
数据库
├── 姓名1
│ ├── Image1.jpg
│ ├── Image2.jpg
│ ├── Image3.jpg
│ ├── Image4.jpg
│ ├── Image5.jpg
│ └── Image6.jpg
└── 姓名2
├── Image1.jpg
├── Image2.jpg
├── Image3.jpg
├── Image4.jpg
└── Image5.jpg通过以下方式运行python脚本,生成数据库:
python db_gen/generate_face_db.py --db db --db-filename embeddings --include-path include或
sh gen_db.sh运行成功后,会在db_gen目录下,生成参考向量的嵌入embeddings.bin。
接着就可以对项目工程进行重新编译了。
写在最后
max78000为美信发布的一款边缘人工智能处理开发板,非常感谢硬禾学堂提供的这次上手机会,能够让我能够接触到这么一款出色的边缘计算开发板!同时由于中文资料的稀少,在此要非常感谢微信公众号 AI研修 潜水摸大鱼的相关文档,本文有相当一部分内容来自于此!在最后还要感谢美信的工程师撰写的开发文档,非常的全面、具体!
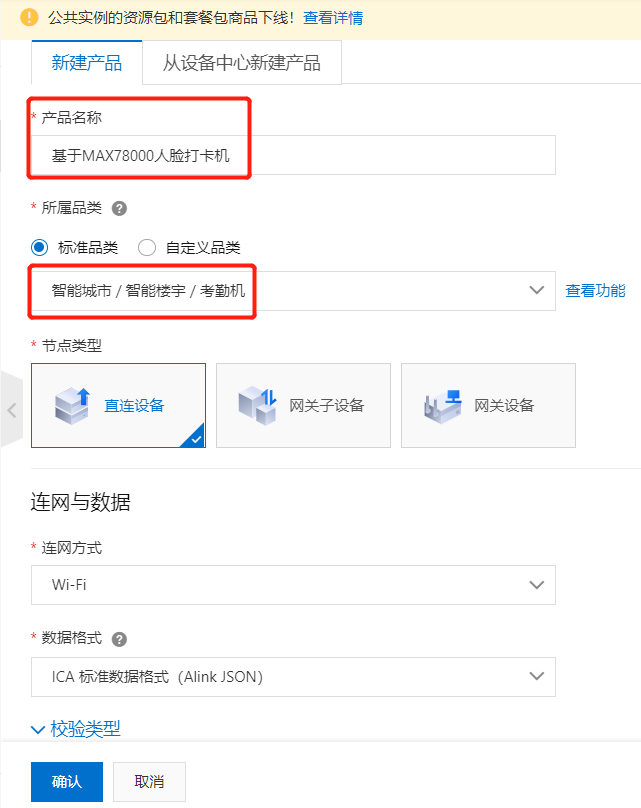
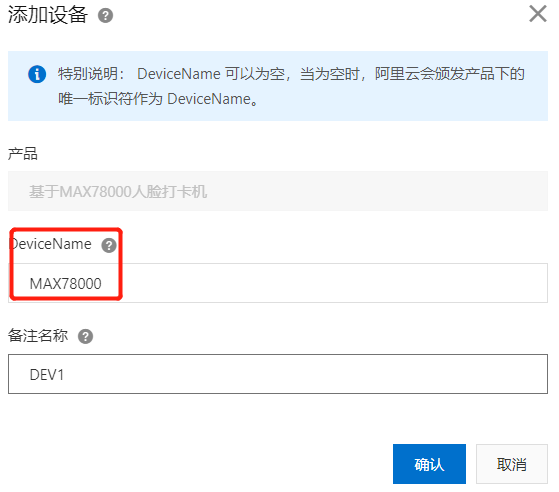
点击“创建产品”,产品命名为“基于MAX78000人脸打卡机”,产品品类选择考勤机,其他保持默认。
点击“添加设备”,选择产品为“基于MAX78000人脸打卡机”,设备命名“MAX78000”。
进入设备界面,找到MQTT连接参数,选择查看。
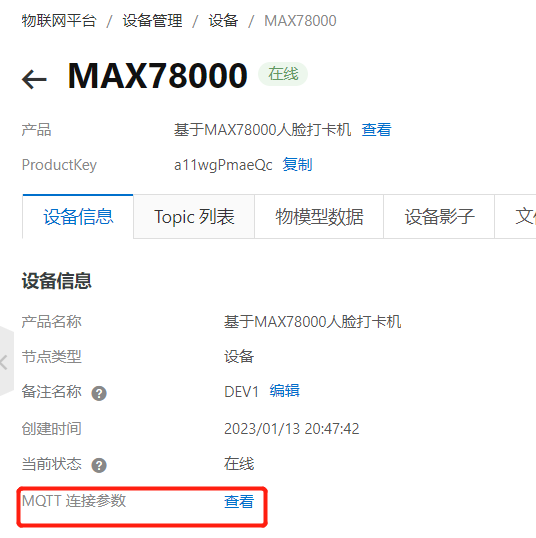
mqttHostUrl: a11wgPmaeQc.iot-as-mqtt.cn-shanghai.aliyuncs.com
port: 1883
ClientId: a11wgPmaeQc.MAX78000|securemode=2,signmethod=hmacsha256,timestamp=1673619001643|
Username: MAX78xxxxxxxmaeQc
Password: 70de2224e0f6xxxxxxxxxxxxxxxxxxxdcbabae6085c60aceac串口助手调试命令如下(收到为ESP8266回传数据):
[20:36:07.432]发→◇ATE0
□
[20:36:07.435]收←◆ATE0
OK
[20:48:00.743]发→◇AT
□
[20:48:00.746]收←◆
OK
[20:49:56.160]发→◇AT+CWMODE=3
□
[20:49:56.225]收←◆
OK
[20:50:03.622]发→◇AT+CIPSNTPCFG=1,8,"ntp1.aliyun.com"
□
[20:50:03.628]收←◆
OK
[20:52:46.331]发→◇AT+CWJAP="ChinaNet-ZAtL","13739771346LB"
□
[20:52:46.338]收←◆
busy p...
[20:52:50.290]收←◆WIFI CONNECTED
[20:52:53.297]收←◆WIFI GOT IP
[20:52:54.196]收←◆
OK
[21:13:14.033]发→◇AT+MQTTUSERCFG=0,1,"NULL","MAX7xxxxxPmaeQc","2f843d0666bd9xxxxxxxxxxxxxxx60be40719df4a3a1",0,0,""
□
[21:13:14.042]收←◆
OK
[21:41:16.628]发→◇AT+MQTTCLIENTID=0,"a11wgPmaeQc.MAX78000|securemode=2\,signmethod=hmacsha256\,timestamp=1673619001643|"
□
[21:41:16.639]收←◆
OK
[21:41:37.121]发→◇AT+MQTTCONN=0,"a11wgPmaeQc.iot-as-mqtt.cn-shanghai.aliyuncs.com",1883,1
□
[21:41:37.271]收←◆+MQTTDISCONNECTED:0
[22:57:35.164]发→◇AT+MQTTSUB=0,"/sys/a11wgPmaeQc/MAX78000/thing/event/property/post_reply",1
□
[22:57:35.220]收←◆
OK
[22:58:42.367]发→◇AT+MQTTPUB=0,"/sys/a11wgPmaeQc/MAX78000/thing/event/property/post","{\"id\":1673621165732\,\"params\":{\"AttendanceState\":0}\,\"version\":\"1.0\"\,\"method\":\"thing.event.property.post\"}",1,0
□
[22:58:42.421]收←◆
OK
+MQTTSUBRECV:0,"/sys/a11wgPmaeQc/MAX78000/thing/event/property/post_reply",116,{"code":200,"data":{},"id":"1673621165732","message":"success","method":"thing.event.property.post","version":"1.0"}
AT+MQTTCLEAN=0 // 断开连接这里我使用了魔罗大佬的AT Command命令通信交互组件,涵盖了大部分AT通信形式,如参数设置,查询,二进制数据发送等,同时也支持自定义命令交互管理,由于它的每个命令请求都是异步的,所以对于无操作系统的环境也支持。
1.定义适配器,完成驱动接口及缓冲区设置(wifi_aliyun.c)此处需定义AT控制器并实现MAX78000串口接收和串口发送。
/*
* @brief 定义AT控制器
*/
static at_obj_t *at;
/*
* @brief AT适配器
*/
static const at_adapter_t at_adapter = {
.write = wifi_uart_write,
.read = wifi_uart_read,
.error = at_error,
.read = wifi_uart_read,
.write = wifi_uart_write,
.urc_bufsize = sizeof(wifi_urcbuf),
.recv_bufsize = sizeof(wifi_recvbuf)
};MAX78000串口数据接收我使用的是DMA接收,此处仍有些小问题,目前只能在第二次回复后收到数据。(main.c)
void DMA_Handler(void)
{
MXC_DMA_Handler();
uint8_t i, j =0;
memset(BRxData, 0, 32); // 清空数组
for(i=0; i<8; i++)
{
if(RxData[i]>=0x41 && RxData[i]<=0x5A) // 筛出未知字符
BRxData[j++] = RxData[i];
}
WIFI_UART_RxCpltCallback(BRxData, strlen(BRxData)); // 放入数据缓存区
UARTRevMode(); // 接收模式
MXC_UART_ClearRXFIFO(MXC_UART_GET_UART(WIFI_UART)); // 清空接受标志位
DMA_FLAG = 0;
if(BRxData[0] == 'M' || BRxData[0] == 'N') // 接收到这两个字符证明配置完成
{
MQTT_STATE = 0; // 连接
UARTSendMode(); // 发送模式
}
}MAX78000串口发送函数(wifi_uart.c)
unsigned int wifi_uart_write(const void *buf, unsigned int len)
{
unsigned int ret;
ret = ring_buf_put(&rbsend, (unsigned char *)buf, len);
Luart.rxLen = 0;
Luart.txData = buf;
Luart.txLen = len;
MXC_UART_Transaction(&Luart); // wifi串口数据发送
return ret;
}wifi_init函数初始化AT适配器并将命令放入缓冲区。
/*
* @brief wifi初始化 配置8266
*/
void wifi_init(void)
{
static char msg[128];
// WIFI 串口初始化
wifi_uart_init(115200);
at = at_obj_create(&at_adapter);
// 关闭回显
at_send_singlline(at, NULL, "ATE0"); // OK
// AT测试
at_send_singlline(at, NULL, "AT"); // OK ERROR *
// 配置工作模式 S+A模式
at_send_singlline(at, NULL, "AT+CWMODE=3");
// 连接阿里云
at_send_singlline(at, NULL, "AT+CIPSNTPCFG=1,8,\"ntp1.aliyun.com\"");
// 连接路由器 仅需配置一次 之后可自动连接 此处无法匹配 请自行确定
//at_exec_cmd(at, NULL, "AT+CWJAP=\"%s\",\"%s\"", SSID, PWD);
// 发送 Username Password
at_exec_cmd(at, NULL, "AT+MQTTUSERCFG=0,1,\"NULL\",\"%s\",\"%s\",0,0,\"\"", Username, Password);
// 发送 ClientId
at_exec_cmd(at, NULL,"AT+MQTTCLIENTID=0,\"%s\"", ClientId);
// 发送 mqttHostUrl
at_exec_cmd(at, &attr, "AT+MQTTCONN=0,\"%s\",1883,1\r\n", mqttHostUrl);
}; 经过以上步骤即可完成AT命令的配置,通过在上电时加入延时循环即可完成。
/*
* @brief wifi任务(10ms 轮询1次)
*/
void wifi_task(void)
{
at_obj_process(at);
};
// 主函数调用
wifi_task();
Ticksum(5); // 需自行实现此函数 获取系统Tick
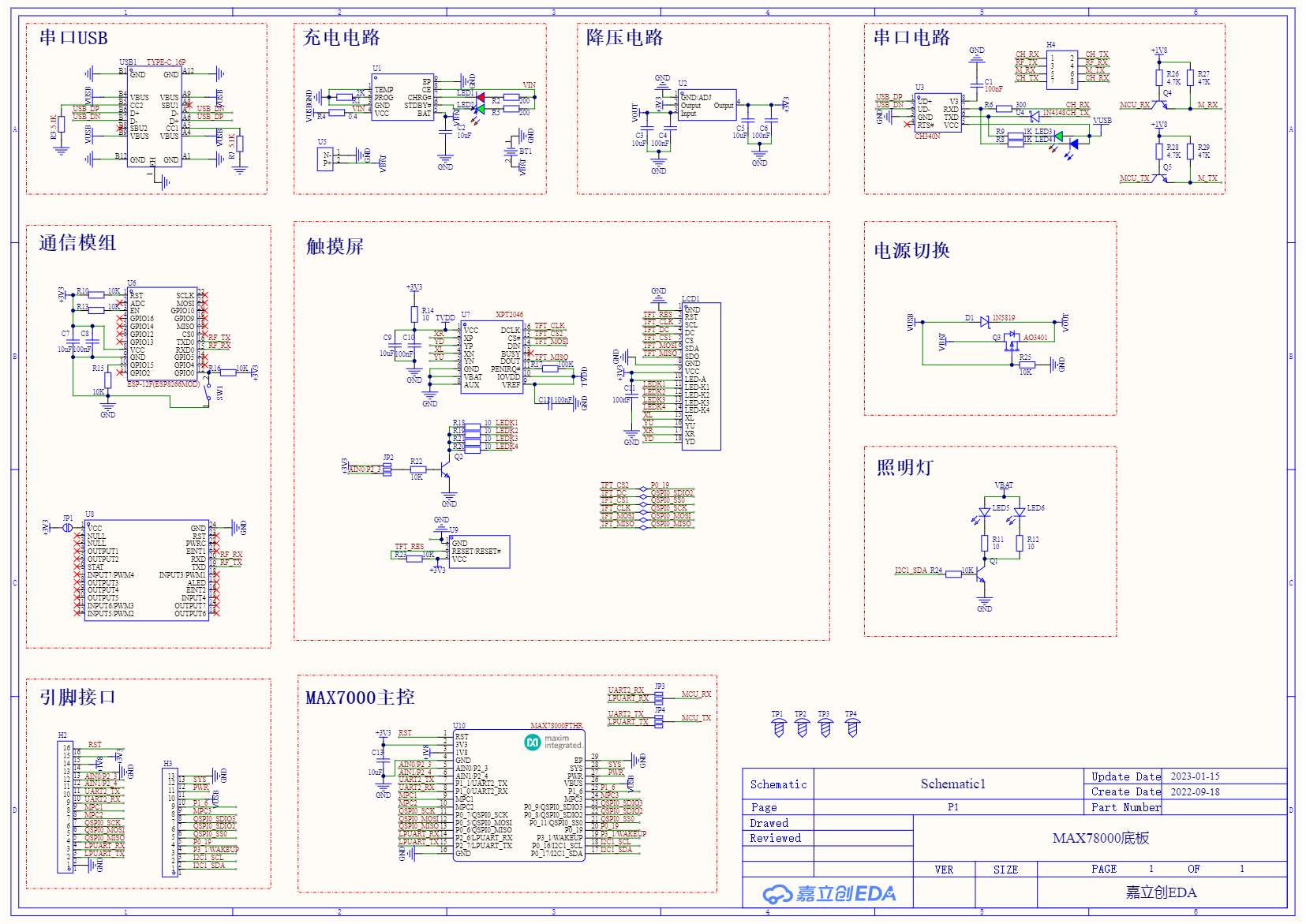
MXC_Delay(3000);原理图如下,人脸识别底板有以下特点。
1.使用USB/电池供电,设计了电源切换、TP4056芯片充电、AMS1117-3.3降压电路;
2.板载WIFI/蓝牙模组,可使用此模块进行物联网开发,同时板载串口电路,方便对MAX78000/WIFI/蓝牙模组进行调试;
3.板载一块2.4寸LCD屏,同时PCB集成了XPT2046触摸芯片;
4.MAX78000 REV开发板引脚全部引出,可通过杜邦线连接其他模块;
5.板载2颗白光LT2832 高亮度LED,方便对摄像头进行补光操作。
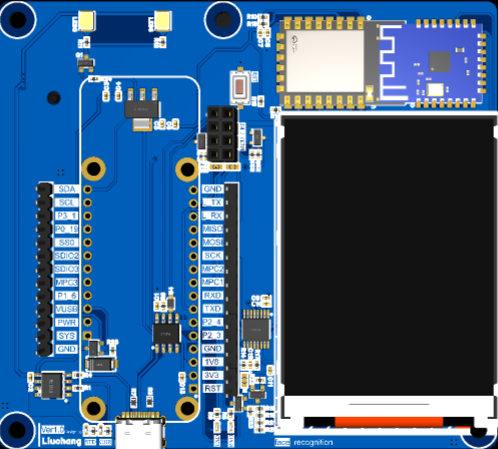
PCB如下图,MAX78000位于屏幕左侧,MAX78000主板下布置了电源切换电路、串口电路和降压电路。
WIFI/BLE位于LCD屏幕上侧,补光灯位于MAX78000上侧。
人脸识别框架主要参考faceid_evkit例程进行二次开发,主要界面如下:
ESP8266配置界面如下图,屏幕中间显示配置进度条。

人脸识别测试:在网上找到星爷和茵姐的照片测试了下识别效果,如下图,这里显示的名字都是他们的英文名。

3.阿里云属性上传
当时识别到特定人脸后,即可通过串口向ESP8266发送MQTT上报消息,如下,其中较为复杂的是格式化部分:
memset(sendmsg, 0, 128);
sprintf(sendmsg, "AT+MQTTPUB=0,\"%s\",\"{\\\"id\\\":1673621165732\\\,\\\"params\\\":{\\\"StephenChow_State\\\":%d}\\\,\\\"version\\\":\\\"1.0\\\"\\\,\\\"method\\\":\\\"thing.event.property.post\\\"}\",1,0\r\n", Post, StephenChow_s);
Luart.rxLen = 0;
Luart.txData = sendmsg;
Luart.txLen = strlen(sendmsg);
MXC_UART_Transaction(&Luart); // wifi串口数据发送发送完成后即可在阿里云查看数据属性:

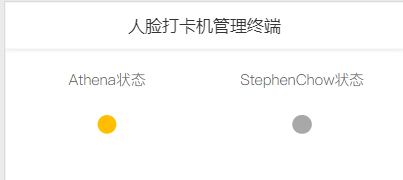
同时还可以使用阿里云stduio平台进行可视化显示:

 Lucia
Lucia