一、项目介绍
本项目基于max78000 FTHR_RevA开发板实现,通过板载麦克风采集周围的语音信号,利用max78000的ai功能,进行语音识别,实现语音开启录音,并将录制的语音信号以wav和mp3两种格式保存到sd卡中。
二、项目设计思路
1、安装环境
参考链接:GitHub - MaximIntegratedAI/ai8x-training: Model Training for ADI's MAX78000 and MAX78002 AI Devices
本项目中使用的系统为win11的wsl2 ubuntu 20.04版本。
第一步
安装相应的软件
sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev libsndfile-dev portaudio19-dev
第二步
安装python
- 安装pyenv
curl -L https://github.com/pyenv/pyenv-installer/raw/master/bin/pyenv-installer | bash
- 在~/.bashrc文件中添加
# WSL2
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init --path)"
eval "$(pyenv virtualenv-init -)"
- 初始化pyenv
~/.pyenv/bin/pyenv init
- 安装python
pyenv install 3.8.11
第三步
下载ai8x-training和ai8x-synthesis工程
git clone --recursive https://github.com/MaximIntegratedAI/ai8x-training.git
git clone --recursive https://github.com/MaximIntegratedAI/ai8x-synthesis.git
第四步
创建和安装训练需要的python环境
cd ai8x-training
pyenv local 3.8.11
python -m venv venv --prompt ai8x-training
source venv/bin/activate
pip3 install -U pip wheel setuptools
pip3 install -r requirements-cu11.txt
第五步
训练,由于语音训练需要的系统资源过多,本人电脑无法完整运行,所以直接使用demo自带的关键字实现识别功能。
2、语音录制
本项目录音的流程为,先保存原始声音信息,再将声音信息转成wav文件,最后将wav文件转成mp3文件。
第一步
采集声音信号。通过i2s总线读取由板载数字麦克风采集到的声音数据。由于只有一个麦克风,所以录制的声音为单声道格式。
板载数字麦克风读取协议如下图所示,是一个24位精度的数据,但是每次都传输32位。后续我们在处理声音信号时,利用i2s_rx_buffer[loop] >> 14向右移动14位,来移除多余的8位数据无效数据,以及滤除波动大的低6位数据。对比下方代码和协议,可以理解代码的用以。
/* Configure I2S interface parameters */
req.wordSize = MXC_I2S_DATASIZE_WORD;
req.sampleSize = MXC_I2S_SAMPLESIZE_THIRTYTWO;
req.justify = MXC_I2S_MSB_JUSTIFY;
req.wsPolarity = MXC_I2S_POL_NORMAL;
req.channelMode = MXC_I2S_INTERNAL_SCK_WS_0;
/* Get only left channel data from on-board microphone. Right channel samples are zeros */
req.stereoMode = MXC_I2S_MONO_LEFT_CH;
req.bitOrder = MXC_I2S_MSB_FIRST;
/* I2S clock = PT freq / (2*(req.clkdiv + 1)) */
/* I2S sample rate = I2S clock/64 = 16kHz */
req.clkdiv = 5;
req.rawData = NULL;
req.txData = NULL;
req.rxData = i2s_rx_buffer;
req.length = I2S_RX_BUFFER_SIZE;
第二步
完成原始声音数据到wav文件的转码。
wav的文件格式说明

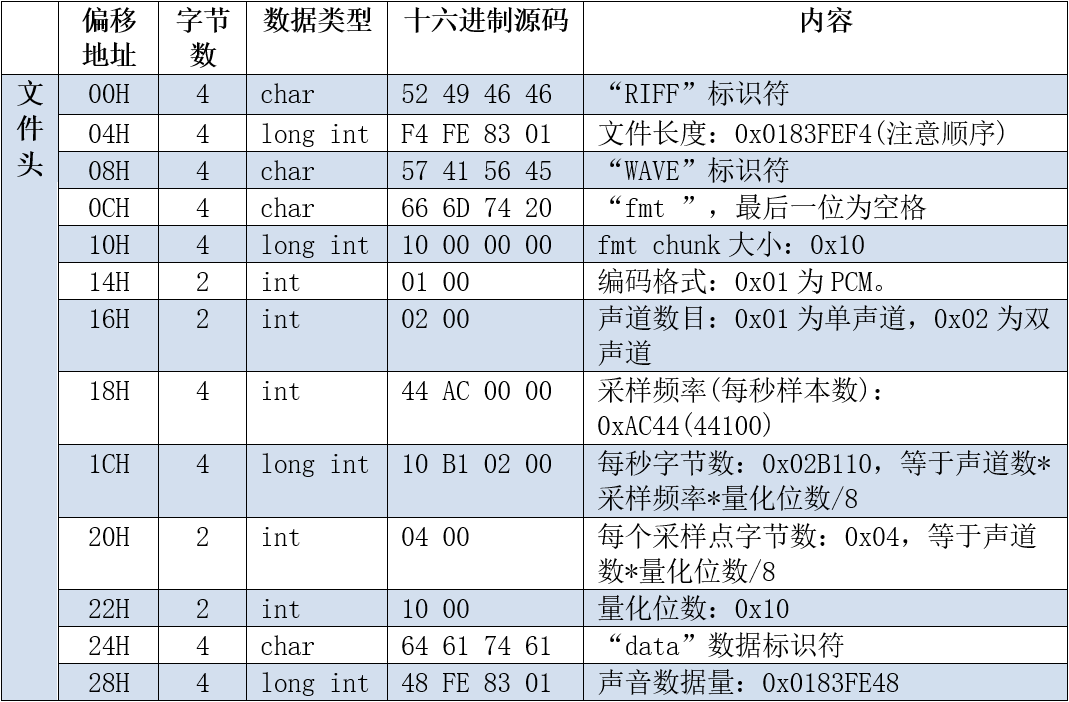
将i2s的数据放入wav文件的声音数据区,并添好相关的头部信息,就完成了wav文件的生成。其中声音的采集频率和时间决定了文件的内容的大小。
第二步
wav转成mp3。由于格式转化的工作一般都是由主机进行的,需要耗费的资源一般比较多也比较复杂。通过在网上搜索和对比,本项目对github上开源的linux 版的mp3编码库(https://github.com/toots/shine)进行了移植适配,实现在单片机上独立完成wav到mp3的转换。
3、整体代码逻辑
硬件上电后,简单初始化串口和唤醒始终。接着就进入到cnn_test函数,进行语音指令的侦听。本工程移除了大量示例工程中无效的宏定义和代码,方便阅读。
int main(void)
{
MXC_Delay(200000);
system_clock_init();
// Initialize UART
console_UART_init(CON_BAUD);
Microphone_Power(POWER_ON);
PR_INFO("\n*** READY ***\n");
/* Read samples */
while (1)
{
cnn_test();
record_init();
}
}
当检测到“on”指令的出现,就开始进行录音,如果没有就一直保持持续的监听。由于录音和侦听都使用到了外部的麦克风,所以侦听任务函数在执行侦听前,都会重新初始化一遍所需的资源。
static void cnn_test(void)
{
uint32_t sampleCounter = 0;
mxc_tmr_unit_t units;
uint8_t pChunkBuff[CHUNK];
uint16_t avg = 0;
uint16_t ai85Counter = 0;
uint16_t wordCounter = 0;
uint16_t avgSilenceCounter = 0;
mic_processing_state procState = STOP;
micBuff = fsfBuff;
pAI85Buffer = &fsfBuff[SAMPLE_SIZE];
i2s_rx_buffer = &fsfBuff[SAMPLE_SIZE * 2];
#ifdef WUT_ENABLE
// Get ticks based off of microseconds
mxc_wut_cfg_t cfg;
uint32_t ticks;
MXC_WUT_GetTicks(WUT_USEC, MXC_WUT_UNIT_MICROSEC, &ticks);
// config structure for one shot timer to trigger in a number of ticks
cfg.mode = MXC_WUT_MODE_CONTINUOUS;
cfg.cmp_cnt = ticks;
// Init WUT
MXC_WUT_Init(MXC_WUT_PRES_1);
// Config WUT
MXC_WUT_Config(&cfg);
MXC_LP_EnableWUTAlarmWakeup();
NVIC_EnableIRQ(WUT_IRQn);
#endif
#ifdef WUT_ENABLE
MXC_WUT_Enable(); // Start WUT
#endif
/* Enable peripheral, enable CNN interrupt, turn on CNN clock */
/* CNN clock: 50 MHz div 1 */
cnn_enable(MXC_S_GCR_PCLKDIV_CNNCLKSEL_PCLK, MXC_S_GCR_PCLKDIV_CNNCLKDIV_DIV1);
/* Configure P2.5, turn on the CNN Boost */
cnn_boost_enable(MXC_GPIO2, MXC_GPIO_PIN_5);
#include "types.h"
printf("sizeof(shine_global_config)=%#x", sizeof(shine_global_config));
PR_INFO("\n\nANALOG DEVICES \nKeyword Spotting Demo\nVer. %s \n", VERSION);
PR_INFO("\n***** Init *****\n");
memset(pAI85Buffer, 0x0, SAMPLE_SIZE);
PR_DEBUG("pChunkBuff: %d\n", sizeof(pChunkBuff));
PR_DEBUG("pAI85Buffer: %d\n", sizeof(pAI85Buffer));
/* Bring state machine into consistent state */
cnn_init();
/* Load kernels */
cnn_load_weights();
/* Configure state machine */
cnn_configure();
/* Disable CNN clock */
MXC_SYS_ClockDisable(MXC_SYS_PERIPH_CLOCK_CNN);
/* switch to silence state*/
procState = SILENCE;
/* initialize I2S interface to Mic */
I2SInit();
MXC_Delay(SEC(2)); // wait for debugger to connect
uint8_t readyFlag = 0;
while (1)
{
/* Read from Mic driver to get CHUNK worth of samples, otherwise next sample*/
if (MicReadChunk(&avg) == 0)
{
continue;
}
sampleCounter += CHUNK;
/* wait for at least PREAMBLE_SIZE samples before detecting the utterance */
if (sampleCounter < PREAMBLE_SIZE)
continue;
#ifdef ENABLE_SILENCE_DETECTION // disable to start collecting data immediately.
/* Display average envelope as a bar */
/* if we have not detected voice, check the average*/
if (procState == SILENCE)
{
/* compute average, proceed if greater than threshold */
if (avg >= thresholdHigh)
{
/* switch to keyword data collection*/
procState = KEYWORD;
/* record the average and index of the begining of the word */
utteranceAvg = avg;
utteranceIndex = micBufIndex;
ai85Counter += PREAMBLE_SIZE;
continue;
}
}
/* if it is in data collection, add samples to buffer*/
else if (procState == KEYWORD)
#endif // #ifdef ENABLE_SILENCE_DETECTION
{
uint8_t ret = 0;
/* increment number of stored samples */
ai85Counter += CHUNK;
/* if there is silence after at least 1/3 of samples passed, increment number of times back to back silence to find end of keyword */
if ((avg < thresholdLow) && (ai85Counter >= SAMPLE_SIZE / 3))
{
avgSilenceCounter++;
}
else
{
avgSilenceCounter = 0;
}
/* if this is the last sample and there are not enough samples to
* feed to CNN, or if it is long silence after keyword, append with zero (for reading file)
*/
if (avgSilenceCounter > SILENCE_COUNTER_THRESHOLD)
{
memset(pChunkBuff, 0, CHUNK);
zeroPad = SAMPLE_SIZE - ai85Counter;
ai85Counter = SAMPLE_SIZE;
}
/* if enough samples are collected, start CNN */
if (ai85Counter >= SAMPLE_SIZE)
{
int16_t out_class = -1;
double probability = 0;
/* end of the utterance */
int endIndex =
(utteranceIndex + SAMPLE_SIZE - PREAMBLE_SIZE - zeroPad) % SAMPLE_SIZE;
PR_DEBUG("Word starts from index %d to %d, padded with %d zeros, avg:%d > %d \n",
utteranceIndex, endIndex, zeroPad, utteranceAvg, thresholdHigh);
// zero padding
memset(pChunkBuff, 0, CHUNK);
/* PREAMBLE copy */
if (utteranceIndex - PREAMBLE_SIZE >= 0)
{
if (AddTranspose((uint8_t *)&micBuff[utteranceIndex - PREAMBLE_SIZE],
pAI85Buffer, PREAMBLE_SIZE, SAMPLE_SIZE, TRANSPOSE_WIDTH))
{
PR_DEBUG("ERROR: Transpose ended early \n");
}
}
else
{
/* copy oldest samples to the beginning*/
if (AddTranspose(
(uint8_t *)&micBuff[SAMPLE_SIZE - PREAMBLE_SIZE + utteranceIndex],
pAI85Buffer, PREAMBLE_SIZE - utteranceIndex, SAMPLE_SIZE,
TRANSPOSE_WIDTH))
{
PR_DEBUG("ERROR: Transpose ended early \n");
}
/* copy latest samples afterwards */
if (AddTranspose((uint8_t *)&micBuff[0], pAI85Buffer, utteranceIndex,
SAMPLE_SIZE, TRANSPOSE_WIDTH))
{
PR_DEBUG("ERROR: Transpose ended early \n");
}
}
/* Utterance copy */
if (utteranceIndex < endIndex)
{
/* copy from utternace to the end */
if (AddTranspose((uint8_t *)&micBuff[utteranceIndex], pAI85Buffer,
endIndex - utteranceIndex, SAMPLE_SIZE, TRANSPOSE_WIDTH))
{
PR_DEBUG("ERROR: Transpose ended early \n");
}
// copy zero padding
while (!ret)
{
ret = AddTranspose(pChunkBuff, pAI85Buffer, CHUNK, SAMPLE_SIZE,
TRANSPOSE_WIDTH);
}
}
else
{
/* copy from utternace to the end*/
if (AddTranspose((uint8_t *)&micBuff[utteranceIndex], pAI85Buffer,
SAMPLE_SIZE - utteranceIndex, SAMPLE_SIZE, TRANSPOSE_WIDTH))
{
PR_DEBUG("ERROR: Transpose ended early \n");
}
/* copy from begining*/
if (AddTranspose((uint8_t *)&micBuff[0], pAI85Buffer, endIndex, SAMPLE_SIZE,
TRANSPOSE_WIDTH))
{
PR_DEBUG("ERROR: Transpose ended early \n");
}
// copy zero padding
while (!ret)
{
ret = AddTranspose(pChunkBuff, pAI85Buffer, CHUNK, SAMPLE_SIZE,
TRANSPOSE_WIDTH);
}
}
/* reset counters */
ai85Counter = 0;
avgSilenceCounter = 0;
/* new word */
wordCounter++;
/* change state to silence */
procState = SILENCE;
/* sanity check, last transpose should have returned 1, as enough samples should have already been added */
if (ret != 1)
{
PR_DEBUG("ERROR: Transpose incomplete!\n");
fail();
}
//---------------------------------- : invoke AI85 CNN
PR_DEBUG("%.6d: Starts CNN: %d\n", sampleCounter, wordCounter);
/* enable CNN clock */
MXC_SYS_ClockEnable(MXC_SYS_PERIPH_CLOCK_CNN);
/* load to CNN */
if (!cnn_load_data(pAI85Buffer))
{
PR_DEBUG("ERROR: Loading data to CNN! \n");
fail();
}
/* Start CNN */
if (!cnn_start())
{
PR_DEBUG("ERROR: Starting CNN! \n");
fail();
}
/* Wait for CNN to complete */
while (cnn_time == 0)
{
__WFI();
}
/* Read CNN result */
cnn_unload((uint32_t *)ml_data);
/* Stop CNN */
cnn_stop();
/* Disable CNN clock to save power */
MXC_SYS_ClockDisable(MXC_SYS_PERIPH_CLOCK_CNN);
/* Get time */
MXC_TMR_GetTime(MXC_TMR0, cnn_time, (void *)&cnn_time, &units);
PR_DEBUG("%.6d: Completes CNN: %d\n", sampleCounter, wordCounter);
switch (units)
{
case TMR_UNIT_NANOSEC:
cnn_time /= 1000;
break;
case TMR_UNIT_MILLISEC:
cnn_time *= 1000;
break;
case TMR_UNIT_SEC:
cnn_time *= 1000000;
break;
default:
break;
}
PR_DEBUG("CNN Time: %d us\n", cnn_time);
/* run softmax */
softmax_q17p14_q15((const q31_t *)ml_data, NUM_OUTPUTS, ml_softmax);
/* find detected class with max probability */
ret = check_inference(ml_softmax, ml_data, &out_class, &probability);
PR_DEBUG("----------------------------------------- \n");
/* Treat low confidence detections as unknown*/
if (!ret || out_class == NUM_OUTPUTS - 1)
{
PR_DEBUG("Detected word: %s", "Unknown");
}
else
{
PR_DEBUG("Detected word: %s (%0.1f%%)", keywords[out_class], probability);
}
PR_DEBUG("\n----------------------------------------- \n");
Max = 0;
Min = 0;
//------------------------------------------------------------
/* clear the buffer */
memset(micBuff, 0, SAMPLE_SIZE);
micBufIndex = 0;
// sampleCounter = 0; // comment to start immediately after the last utterance
if (out_class == 8)
{
break;
}
}
}
}
MXC_WUT_Disable();
}
当采集到“on”指令后,跳出侦听函数。
if (out_class == 8)
{
break;
}
跳出cnn_test函数后就进入录音函数。由于接下来是具体的录音过程,在录音过程中,很有可能需要录音的内容中包含关键字,所以无法通过语音去关闭录音。于是本项目中就采用按键去关闭。
录音过程中需要使用到的按键、led、麦克风、sd卡,它们录音前完成相关资源的配置。
static void record_test(void)
{
PB_Init();
LED_Init();
time_init();
wav_init();
PB_RegisterCallback(0, record_button_start);
PB_RegisterCallback(1, record_button_stop);
__enable_irq();
record_loop();
}
初始化麦克风和sd卡。
void wav_init(void)
{
int32_t err;
mxc_i2s_req_t req;
/* Jumper J20 (I2S CLK SEL) needs to be installed to INT position to provide 12.288MHz clock from on-board oscillator */
printf("\n***** I2S Receiver Example *****\n");
extern uint8_t fsfBuff[0x18000];
i2s_rx_buffer = &fsfBuff;
i2s_tx_buffer = &fsfBuff[I2S_RX_BUFFER_SIZE * 4];
A if (max20303_init(MXC_I2C1) != E_NO_ERROR)
{
printf("Unable to initialize I2C interface to commonicate with PMIC!\n");
while (1)
{
}
}
if (max20303_mic_power(1) != E_NO_ERROR)
{
printf("Unable to turn on microphone!\n");
while (1)
{
}
}
MXC_Delay(MXC_DELAY_MSEC(200));
max20303_led_red(0);
max20303_led_blue(0);
max20303_led_green(1);
printf("\nMicrophone enabled!\n");
MXC_I2S_Shutdown();
/* Initialize I2S RX buffer */
memset(i2s_rx_buffer, 0, I2S_RX_BUFFER_SIZE * 4);
/* Configure I2S interface parameters */
req.wordSize = MXC_I2S_DATASIZE_WORD;
req.sampleSize = MXC_I2S_SAMPLESIZE_THIRTYTWO;
req.justify = MXC_I2S_MSB_JUSTIFY;
req.wsPolarity = MXC_I2S_POL_NORMAL;
req.channelMode = MXC_I2S_INTERNAL_SCK_WS_0;
/* Get only left channel data from on-board microphone. Right channel samples are zeros */
req.stereoMode = MXC_I2S_MONO_LEFT_CH;
req.bitOrder = MXC_I2S_MSB_FIRST;
/* I2S clock = 12.288MHz / (2*(req.clkdiv + 1)) = 1.024 MHz */
/* I2S sample rate = 1.024 MHz/64 = 16kHz */
req.clkdiv = 5;
req.rawData = NULL;
req.txData = NULL;
req.rxData = i2s_rx_buffer;
req.length = I2S_RX_BUFFER_SIZE;
if ((err = MXC_I2S_Init(&req)) != E_NO_ERROR)
{
printf("\nError in I2S_Init: %d\n", err);
while (1)
{
}
}
/* Set I2S RX FIFO threshold to generate interrupt */
MXC_I2S_SetRXThreshold(4);
/* Set DMA Callback pointer if desired */
#if DMA_CALLBACK
MXC_I2S_RegisterDMACallback(i2s_dma_cb);
#else
MXC_I2S_RegisterDMACallback(NULL);
#endif
NVIC_EnableIRQ(DMA0_IRQn);
waitCardInserted();
printf("sd card is ready\r\n");
record.state = RECORD_UNKNOW;
}
准备原始音频文件。
void record_ready(void)
{
mount();
mc_start();
max20303_led_green(0);
max20303_led_red(1);
if ((err = f_open(&record.raw, (const TCHAR *)"raw.txt", FA_CREATE_ALWAYS | FA_WRITE)) != FR_OK)
{
f_mount(NULL, "", 0);
return err;
}
record.state = RECORD_ING;
{
uint32_t day, hr, min, sec;
memset(record.filName, 0, sizeof(record.filName));
sec = time_get() % SECS_PER_DAY;
hr = sec / SECS_PER_HR;
sec -= hr * SECS_PER_HR;
min = sec / SECS_PER_MIN;
sec -= min * SECS_PER_MIN;
sprintf(record.filName, "%02d_%02d_%02d", hr, min, sec);
}
printf("file.name=%s\r\n", record.filName);
}
将获取到的音频信息实时存入到文件中。
void recording(void)
{
FRESULT result;
uint32_t len;
if (mc_get_data(i2s_tx_buffer, &len) == 0)
{
return;
}
printf("data = %d\n", len);
result = f_write(&record.raw, i2s_tx_buffer, 4 * len, &bytes_written);
if (result != FR_OK)
{
f_mount(NULL, "", 0);
return;
}
f_sync(&record.raw);
printf("flash_wr_size = %d\n", bytes_written);
}
将原始音频文件转成wav文件。通过录音的时间去计算具体的文件大小,进行wav首部信息的填写。
uint8_t _stop(void)
{
UINT len;
uint32_t rawFileSize = 0;
uint32_t cnt = 0;
int16_t *wBuff = (int16_t *)i2s_tx_buffer;
char wav_header_fmt[WAVE_HEADER_SIZE];
uint32_t flash_rec_time = 16000 * 2 * record.recordTime;
char wavName[40] = {0};
sprintf(wavName, "%s.wav", record.filName);
printf("recording time %d s\r\n", record.recordTime);
if ((err = f_close(&record.raw)) != FR_OK)
{
return 0;
}
printf("recording time 1\r\n");
if (record.recordTime == 0)
{
return 0;
}
printf("recording time 2\r\n");
if ((err = f_open(&record.raw, (const TCHAR *)"raw.txt", FA_READ)) != FR_OK)
{
return 0;
}
printf("recording time 3\r\n");
if ((err = f_open(&record.wav, (const TCHAR *)wavName, FA_CREATE_ALWAYS | FA_WRITE)) != FR_OK)
{
return 0;
}
_generate_wav_header(wav_header_fmt, flash_rec_time, 16000);
if ((err = f_write(&record.wav, wav_header_fmt, WAVE_HEADER_SIZE, &len)) != FR_OK)
{
return 0;
}
HPF_init();
while (cnt < flash_rec_time)
{
f_read(&record.raw, i2s_rx_buffer, I2S_RX_BUFFER_SIZE * 4, &len);
if (len == 0)
{
printf("len is zero\r\n");
break;
}
cnt += len;
len /= 4;
for (uint16_t loop = 0; loop < len; loop++)
{
wBuff[loop] = HPF(i2s_rx_buffer[loop] >> 14);
}
f_write(&record.wav, wBuff, len * 2, &len);
printf("wave file size=%d\r\n", cnt / 2);
}
if (f_close(&record.raw) != FR_OK)
{
return 0;
}
if (f_close(&record.wav) != FR_OK)
{
return 0;
}
return 1;
}
将wav文件转成mp3文件。
void mp3_cover(char *fileName)
{
char wavName[40] = {0};
char mp3Name[40] = {0};
int16_t buffer[2 * SHINE_MAX_SAMPLES];
wave.file = &file;
mount();
sprintf(wavName, "%s.wav", fileName);
sprintf(mp3Name, "%s.mp3", fileName);
set_defaults(&config);
if (!wave_open(wavName, &wave, &config, quiet))
{
printf("mp3 open error\r\n");
}
config.mpeg.bitr = 32;
if (shine_check_config(config.wave.samplerate, config.mpeg.bitr) < 0)
{
printf("Unsupported samplerate/bitrate configuration.");
}
config.wave.channels = 1;
if (config.wave.channels > 1)
config.mpeg.mode = STEREO;
else
config.mpeg.mode = MONO;
s = shine_initialise(&config);
if (s == NULL)
{
printf("error\r\n");
return;
}
samples_per_pass = shine_samples_per_pass(s);
f_open(&wFile, (const TCHAR *)mp3Name, FA_CREATE_ALWAYS | FA_WRITE);
uint32_t totalLen = f_size(wave.file) - f_tell(wave.file);
uint32_t index = 0;
uint32_t getSize;
while (index < totalLen)
{
getSize = totalLen - index;
if (getSize > samples_per_pass * 2)
{
getSize = samples_per_pass * 2;
}
f_read(wave.file, buffer, getSize, &len1);
char *data = shine_encode_buffer_interleaved(s, buffer, &written);
f_write(&wFile, data, written, &len1);
index += getSize;
printf(" index=%#x\r\n", index);
}
char *data = shine_flush(s, &written);
f_write(&wFile, data, written, &len1);
shine_close(s);
wave_close(&wave);
f_close(&wFile);
umount();
printf("ok\r\n");
return;
}
三、搜集素材的思路
使用demo
四、预训练实现过程
使用demo
五、遇到的困难
1、在训练环境的安装上,新手很难顺利的一次安装成功。首先是对linux和python本身的不了解,其次网络的原因也导致安装的困难,部分软件需要多次的重复安装,才安装成功,最后就是训练对于硬件的要求比较高,有些消耗资源大的项目一般电脑无法完成。像本项目中使用的语音识别,由于资源很大,本人电脑就无法完成训练,但猫狗识别这类较小的可以。
2、硬件资源受限,在需要跑ai的工程中,ai本身的功能就占据了比较大的空间,后续复杂功能的添加就比较受限。由于本项目是本地进行mp3编码的,编码过程中,要占用90多k的ram空间,对于有着128k的max78000本来还算勉强可以运行,但是语音识别这一功能本身也需要占用30多k的代码。这样一来,基本上就无法同时满足这两个功能。本项目最后通过定义一个大数组,让语音功能和录音功能都从这个大数组中获取大空间。由于两个任务是顺序执行的,所以哪怕共用一个空间,也可以正常运行。虽然开发板中带有外部sram,但录音需要用到sd卡存储数据,而这两个使用同一spi。
3、本项目最开始先完成了录音功能和语音识别功能的独立测试,但在两个功能整合后,就出现语音录制的过程中经常出现写入语音文件失败的情况。经过大量测试和查找资料,发现是sd卡io驱动出现了问题。而导致sd驱动出现问题的是前面语音识别功能开启的唤醒时钟导致的。引入唤醒时钟是为了在语音识别过程中降低功耗。在语音录制过程中,唤醒时钟频繁进入中断去严重干扰了sd驱动的稳定运行。通过在退出语音识别时,关闭唤醒时间就可以解决这一问题。

 Lucia
Lucia